
- 분류 전체보기 (1250)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- CSS
- C++
- 데이터입출력구현
- 컴퓨터구조
- SQL
- 혼공머신
- JSP/Servlet
- 중학수학
- 중학1-1
- 정보처리기사필기
- 딥러닝
- 코딩테스트
- 자바
- 컴퓨터비전
- 영어공부
- 파이썬
- CNN
- 머신러닝
- html/css
- 운영체제
- numpy/pandas
- 파이썬라이브러리
- 정보처리기사실기
- 연습문제
- 데이터베이스
- 텍스트마이닝
- 정수와유리수
- pandas
- 데이터분석
- 자바 실습
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
케라스 9 - 사용자 정의 : 배치 및 자동 미분을 활용한 모델 훈련 본문
사용자 정의 함수에 대해서 공부해 볼 것이다. 어떤 내용일지 무척 기대가 된다.
1. 사용자 정의 손실함수
텐서플로에서 기본으로 제공되는 손실함수 외에 사용자가 직접 정의한 손실함수를 정의하여 모델을 훈련시킬 수 있다. 사용자 정의 손실함수를 만드는 방법은 간단하다. 함수를 정의하고 모델 컴파일 시 적용할 수 있다.



여기서도 코드를 하나 수정했다. 책에는 넘파이로 하지 않고 계산했지만 이렇게 하면 오류가 발생했다. 넘파이 배열로 하니 이제 잘 출력이 된다.
2. 사용자 정의 레이어
레이어도 사용자가 직접 정의하여 모델에 적용할 수 있다. 텐서플로가 제공하는 레이어를 상속받아 필요한 부분만 수정해 변경할 수 있고 완전히 새로운 레이어를 정의하여 사용할 수 있다.
다음 코드와 같이 tf.keras.layeres의 Layer 클래스를 상속받아 쉽게 구현할 수 있다. Dense 레이어를 직접 구현한 예시다.

Dense 레이어를 사용하지 않고, 직접 Layer를 상속받아 구현한 MyDense 클래스를 활용하여 모델을 생성하고 훈련해 결과를 확인한다.

이 코드 역시 넘파이 배열로 바꾸어서 진행했다.
3. 사용자 정의 훈련
1. train_on_batch
지금까지 모델을 훈련할 때 fit() 메서드로 훈련을 진행했다. fit() 메서드를 활용하면 전체 배치에 훈련을 진행한 후 1 epoch가 끝나면 전체 훈련 손실함수와 평가지표를 보여준다.
한편, train_on_batch()를 활용하면 배치별로 구분해서 훈련을 진행할 수 있다. 먼저 실습을 위해 mnist 데이터셋을 로드하고 정규화를 진행한다.

Sequential API를 활용하여 모델 생성 후 컴파일한다. 컴파일 과정까지는 동일하게 진행한다.

배치별로 구분해 학습을 진행하기 위해서 배치를 생성하는 함수를 구현한다. batch_size의 기본값으로는 32개로 설정해 batch_size를 원하는 크기로 조절할 수 있다. 함수의 반복문 내부에서는 x, y의 쌍으로 묶인 1개의 배치를 생성한 후 반환한다. 이때 yield 키워드를 지정했는데, 이 키워드는 for 루프가 실행될 때 yield 키워드를 만나기 전까지 실행하고 해당 루프에 대한 결과를 반환하며 다음 함수를 호출할 때 다음 로프가 실행되어 결과를 반환한다.

yield로 반환하는 함수는 파이썬 제너레이터가 되며, 제너레이터에서 값을 반환하기 위해서는 next 키워드를 사용하면 된다. 1개의 배치를 반환할 때 batch_size = 32로 지정했기 때문에 32개의 x, y 데이터가 튜플 형식의 쌍으로 반환된다.

모델 인스턴스의 train_on_batch() 메서드를 사용해 훈련할 때는 각 배치에 대한 반복 훈련이 필요하다. 먼저 epoch를 반복할 루프를 정의하고 루프 안에서 이전에 정의한 get_batches() 제너레이터를 통해 x, y를 반환받아 train_on_batch() 메서드에 매개변수로 입력한다.
배치별 손실을 누적으로 합하여 전체 배치의 개수로 나누어 주면 평균 손실을 산출할 수 있다. 또한 배치별 손실을 리스트에 추가하여 1 epoch의 훈련이 끝난 후 배치별 손실 변화를 시각화할 수 있다.








50개의 배치 훈련이 끝난 후 전체 손실에 대한 평균을 구해 리스트에 추가했다. 하나의 epoch 훈련을 마친 후 배치별 손실의 평균을 시각화하여 변화를 확인한다.
모델 인스턴스의 fit() 메서드를 활용해 모델을 훈련할 때 배치별 훈련을 제어하거나 매 epoch가 끝날 때마다 시각화가 어렵다는 단점이 존재하지만, train_on_batch() 메서드를 활용하면 배치 훈련이 완료된 뒤 다양한 로직을 직접 구현해 줌으로써 훈련을 모니터링할 수 있다.
이 코드를 실행하는 일이 얼마나 시간이 많이 걸리던지 몇 번이나 중단했다가 GPU를 구입한 후에 겨우 진행할 수 있었다. 이렇게 구매를 했어도 18분이나 걸렸다.
2. 자동 미분
텐서플로는 그래디언트를 손쉽게 업데이트 할 수 있는 자동 미분 기능을 지원한다. 자동 미분은 tf.GradientTape()를 통해 계산 과정을 기록한 뒤 graident() 메서드로 미분을 계산할 수 있다. 다음은 자동 미분 기능을 활용한 그래디언트를 구하는 과정이다.
먼저 5개의 값을 포함하는 a, b 텐서를 생성한다. a, b가 훈련 가능한 텐서인지 확인한다. 훈련 가능한 텐서에 대해서만 그래디언트를 계산할 수 있다.

파이썬 with 문으로 tf.GradientTape() 범위를 정의하고 tape으로 지정한다. 그리고 with 문 내부에서 c = a * b를 정의한다. 여기서 tape는 계산 그래프를 저장하는데 with 문 바깥에서 tape.graidient()로 미분을 계산할 수 있다. 여기서 c를 a, b에 대한 편미분을 구하면 다음과 같다.


tape.graidient(c, [a. b])는 c를 a, b에 대한 편미분을 각각 구하여 반환한다. gads에 순차적인 인덱스로 접근하여 미분의 결과를 확인하면 b, a 순서로 결과가 출력된다.
다음은 y = wx + b 식을 계산하고 손실을 구한 뒤 자동 미분 기능을 활용하여 s, b값을 덥데이트한 후 최종 w, b값을 찾도록 한다. 먼저 x, y 샘플 데이터셋을 생성한다.

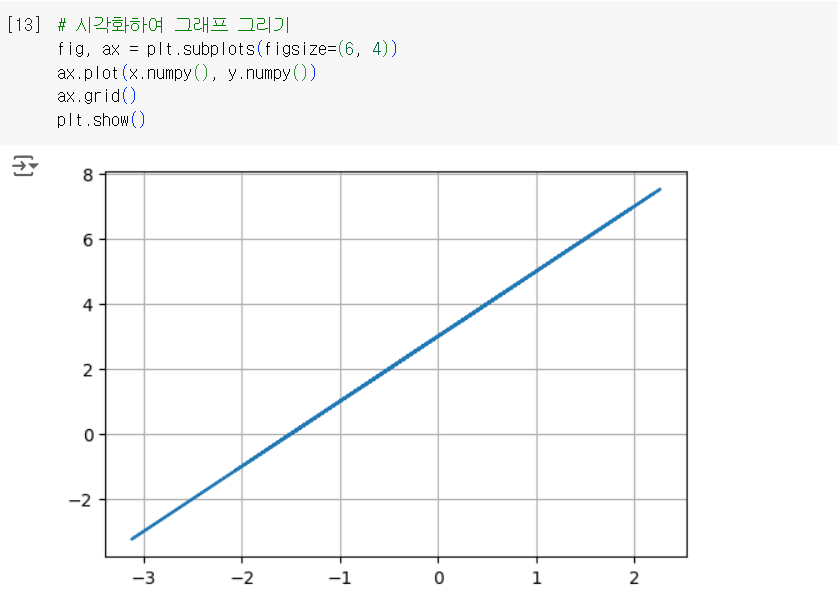
x는 100개의 난수를 생성하였으며 y에는 2x + 3으로 나온 결과를 저장한다. 즉 w = 2, b = 3이다. 그리고 x, y를 시각화하면 기울기가 2이고 절편이 3인 1차 함수 그래프가 생성된다.
다음은 tf.GradientTape() 범위 안에서 y = wx + b를 계산한 뒤 평균제곱오차 손실함수

으로 손실을 계산한다. tape 범위 바깥에서 그래디언트를 계산한 뒤 학습률을 곱하여 w, b에 차감한다.


epoch 9에서 손실은 0.0002를 기록하고, w = 1.9958, b = 2.9936이 출력되었다. y = 2x + 3에서의 기울기 2와 절편 3과 근사한 값을 텐서플로의 자동미분 기능을 이용하여 구했다.
3. 자동 미분을 활용한 모델 훈련
지금까지 모델 인스턴스의 fit() 메서드로 모델을 훈련했다면, 이번에는 텐서플로의 자동 미분 기능을 활용하여 모델 훈련을 진행한다. Sequential API를 활용하여 간단한 모델을 생성한다. 그리고 손실함수와 옵티마이저를 정의하는데 모델 인스턴스의 컴파일 메서드를 사용하여 정의하지 않고 클래스 인스턴스로 생성해 변수에 저장한다.

평가지표는 전체 훈련, 검증 데이터셋에 대한 평균 손실과 정확도를 계산하는 지표를 클래스에 인스턴스로 생성하여 변수에 저장한다.

배치를 생성하는 제러레이터를 생성한다.

train_step() 함수를 정의하고 이미지와 레이블을 매개변수로 입력받는다. 여기서 train_step() 함수에 @tf.function 데코레이터가 붙어 있는 것을 확인할 수 있다. 텐서플로가 2.0 버전으로 업데이트되면서 지연 실행 모드에서 즉시 실행 모드가 비본으로 활성화되도록 변경되었다. 복잡한 연산을 진행하는 모델을 훈련할 때 즉시 실행모드로 실행되면 연산이 느리고 비효율적이므로 계산 그래프를 생성한 뒤 효율적인 연산을 수행할 수 있도록 변경해 주는 작업을 해야 한다.
이럴 때 함수에 @tf.function 데코레이터를 붙여주면 텐서플로가 계산 그래프를 변환해서 지연 실행 모드로 처리된다. 주의해야 할 점은 @tf.function으로 데코레이팅된 함수의 내부에서 넘파이나 파이썬 호출은 상수로 변경된다. 따라서 텐서플로 연산 메서드를 내부에서 사용해야 한다.
train_step() 함수 내부에서는 tf.GradientTape()의 범위를 정의ㅏㅎ고, 범위 안에서 모델 인스턴스에 이미지를 입력하고 결과를 구해 prediction 변수에 대입한다. 정답 레이블인 labels 모델이 예측한 결과인 predictiohn를 손실함수에 입력값으로 대입해 손실을 계산한다. 이 모든 계산 과정은 tape에 기록된다.
tape의 범위이 바깥에서 tape.gradient()에 손실과 모델 인스턴스의 trainable_variables를 대입하여 전체 미분을 계산한다.
마지막으로 optimizer의 apply_gradients() 메서드를 사용하여, 이전에 구한 그래디언트와 모델 인스턴스의 trainable_variables를 zip으로 묶어 대입해 그래디언트를 갱신한다. 끝으로 훈련 손실과 정확도를 계산하여 저장한다.
train_step() 함수와 마찬가지로 검증 손실과 정확도를 계산해 저장한다.

마지막으로 평가지표를 reset_states() 메서드로 초기화한 뒤, 5번의 epoch를 반복 훈련할 수 있는 반복문 안에서 get_batches 제너레이터로 배치별 훈련을 진행한다. 미리 정의한 train__step() 함수는 모델의 그래디언트를 갱신하며 valid_step() 함수는 검증 손실 및 정확도를 계산한다.

학습을 마치고
이번 단원을 공부를 마치는데 시간이 참 많이 걸렸다. 그 이유는 코드를 실행하는데 굉장히 많은 시간이 걸렸기 때문이다. 특히 epoch를 3가지로 나누어서 연산하는 코드가 있었는데 그 코드에서 첫 번째 에포크만 연산하여 그래프로 그리는데 15분도 훨씬 넘게 걸렸다. 그리고 너무 오래 걸려서 10분 정도 있다가 몇 번이나 중단하고 다시 작업을 시작했다.
GPU로 바꾸어 보았으나 무료 버전이라 이용할 수 없다고 하고.. 결국 1만 5천원이나 되는 거금을 주고 GPU를 구입했다. 구입한 후에는 3배 이상 연산이 빨라졌다. 아마 그냥 계속 실행했더라면 1시간이 넘게 걸렸을지도 모르겠다.
이번 시간을 통해 딥러닝을 공부할 때는 GPU를 반드시 구입해서 사용해야 한다는 걸 알게 되었다. 앞으로 딥러닝 과정의 공부가 많이 남아있는데 그때마다 연산을 수행하는데 많은 시간이 걸려 공부 시간을 헛되게 보내고 싶지 않았다.
진작 구입할 걸 하는 생각이 들었다. 자동 미분 정말 어려운 단원이었지만 그래도 학습을 잘 마쳤다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 케라스 11 - tf.data.Dataset 클래스 (0) | 2024.10.26 |
|---|---|
| 케라스 10 - 텐서플로 데이터셋 (0) | 2024.10.26 |
| 케라스 8 - 복잡한 모델 생성 (0) | 2024.10.26 |
| 케라스 7 - 모델 저장 및 불러오기 (0) | 2024.10.26 |
| 케라스 6 - 콜백(Callback) (0) | 2024.10.26 |



