
- 분류 전체보기 (1250)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- JSP/Servlet
- 데이터베이스
- CNN
- 파이썬
- 중학1-1
- 정수와유리수
- 텍스트마이닝
- html/css
- 코딩테스트
- C++
- CSS
- 운영체제
- 컴퓨터구조
- 영어공부
- SQL
- 딥러닝
- 정보처리기사필기
- 중학수학
- 컴퓨터비전
- 파이썬라이브러리
- 데이터분석
- 자바
- numpy/pandas
- pandas
- 연습문제
- 자바 실습
- 혼공머신
- 데이터입출력구현
- 머신러닝
- 정보처리기사실기
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
합성곱 신경망 1 - 합성곱 신경망에 대하여 본문
저녁을 먹고 아침에 하다 말았던 딥러닝 공부를 다시 시작해 본다. 사실 식사하기 전에 30분 정도 공부를 했었는데 수업 영상이 중간에 잘리기도 하고 제공된 코드도 없어서 도저히 진행할 수가 없었다. 선생님께 자료를 요청했으나 답장이 없어 그냥 원래 없다고 생각하고 넘어가기로 했다.
책에도 자세한 내용이 나와있으니 부족하면 책으로 공부를 진행하면 된다. 엊그제는 케라스 공부를 마쳤는데 오늘과 내일까지 이틀 동안 CNN 공부를 마쳐볼 생각이다.
합성곱 신경망(CNN : Convolutional Neural Network)은 데이터가 가진 특징들의 패턴을 학습하는 알고리즘으로 컴퓨터 비전 분야에서 많이 사용된다. 대표적으로 이미지 분류, 객체 탐지, 스타일 전이 등을 예로 들 수 있다.
아래 그림은 이미지 분류 문제를 설명하고 있다. 그림을 보면 고양이 또는 강아지 사진으로 모델을 학습시키면 모델을 이미지의 특징을 추출해 고양이 또는 강아지를 분류할 수 있게 된다. 즉, 이미지를 인식할 수 있는 능력을 모델이 갖추게 된다.

다음 그림은 객체 탐지 사례를 보여준다. 이미지에서 특정한 객체를 인식하고 이미지의 어디에 있는지 위치까지 파악하는 기술이다. 고양이 이미지의 위치에 표시된 노란색 실선을 경계 박스라고 부른다. 인식한 객체가 어떤 클래스에 속하는지 본류 확률과 예측을 함께 알려 준다.
일반적으로 객체의 위치는 이미지의 좌표 값으로 나타내기 때문에, 경계 박스를 찾는 문제는 회귀분석으로 해결한다. 반면 클래스를 예측하는 문제는 분류 문제가 된다.

한편 스타일 전이는 콘텐츠의 이미지와 스타일 참조 이미지를 이용해 콘텐츠의 기본 형태를 유지하고 스타일을 입혀서 새로운 이미지를 생성하는 기술을 말한다.
이미지 표현
이미지(또는 영상)를 컴퓨터가 이해할 수 있게 하려면 숫자로 표현해야 한다. 이번에 다룰 이미지들은 모두 숫자 데이터로 기록되어 있다.
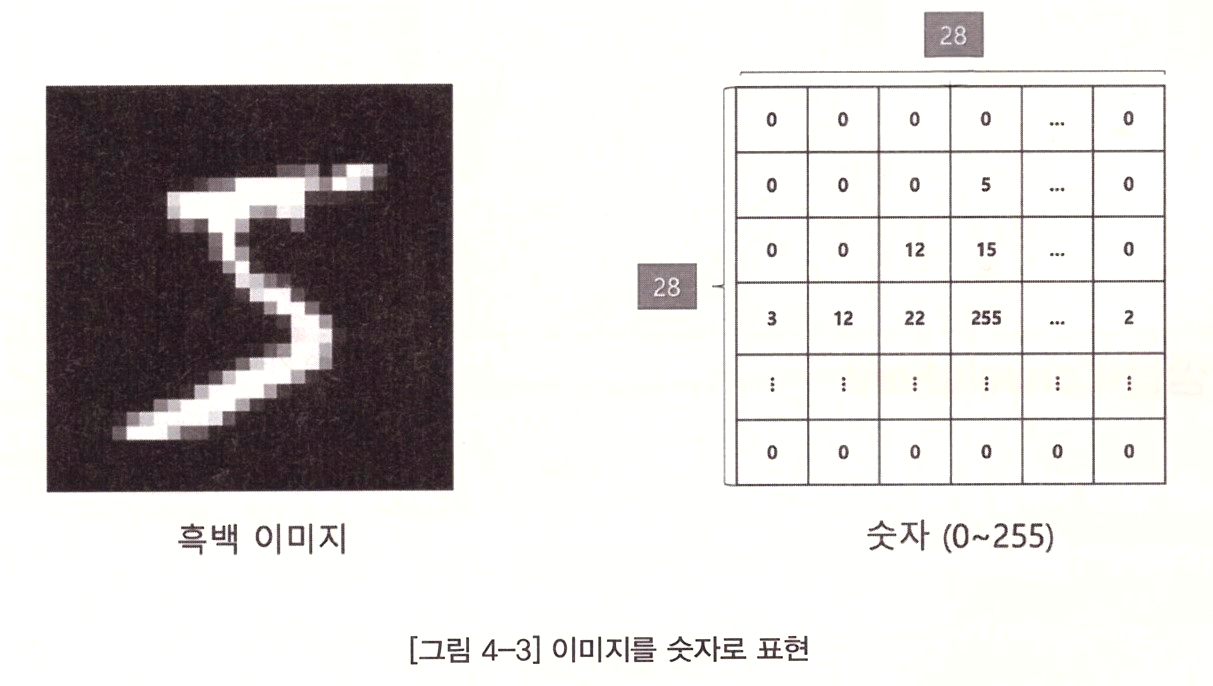
위 그림을 보면 왼쪽에 있는 손글씨 이미지는 오른쪽 그림과 같이 0~255 사이의 숫자로 각 픽셀의 화소 값을 나타내는 방식으로 표현할 수 있다. 숫자 0은 완전히 검은색을 나타내고 숫자 255는 흰색을 나타낸다.
그 중안게 있는 숫자들은 회색으로 표현된다. 화소를 나타내는 숫자는 이미지의 강도를 나타내고 숫자가 클수록 더 강한 특성을 나타낸다.
한편 컬러 이미지는 R, G, B 채널로 구성된 3장의 이미지를 겹쳐서 표현한다. 각 채널 이미지는 채널이 1개인 흑백이미지와 마찬가지로 0~255 사이의 숫자로 나타낸다. 숫자가 클수록 해당 색상을 더 강하게 표현한다. 여기서 채널은 각각이 하나의 이미지로 구분되며, 컬러 이미지는 3개의 채널 이미지를 하나로 결합하여 표현하는 방식이다.

합성곱(Convolution)
합성곱 연산은 입력 이미지에 대하여 일반적으로 정방형 크기를 가지는 커널을 사용하여, 입력이미지에 대한 특성을 추출하는 방법을 말한다. 합성곱 연산을 통해서 추출된 이미지를 특성맵(feature map)이라고 부른다. 이렇게 추출된 특성맵을 딥러닝 모델 학습에 사용하면 훨씬 더 좋은 성능을 보인다.
아래 그림은 이미지에 필터를 적용하는 합성곱 연산을 설명하고 있다.
입력 이미지는 (세로, 가로) 순서로 shape이 출력된다. 즉, 세로 5 픽셜, 가로 5픽셀의 크기를 가지는 이미지는 (5, 5)의 shape을 가진다. 이러한 입력 이미지의 좌측 상단부터 커널과 같은 크기를 갖도록 이미지의 일부분에 커널이 겹치도록 투영해 준다. 이렇게 입력 이미지와 커널이 겹치는 부분에 대하여 합성곱 연산을 수행하게 된다.
예를 들어, 3 x 3 사이즈를 가지는 커널이 첫 좌측 상단의 입력 이미지 3 x 3 부분과 매칭되어 합성곱 연산을 수행한다. 합성곱 연산은 elsement-wise 곱셈 연산을 수행 후 모두 더한 값으로 단일 스칼라 값이 나온다. 이렇게 나온 결과는 추출된 이미지인 feature map의 좌측 상단의 첫 번째 값이 된다.

커널 사이즈가 3 x 3인 경우 총 9개의 가중치를 가지며 오차 역전파 시 커널의 가중치를 업데이트한다. 합성곱 신경망이 이미지 특성 추출에 효율적 이유는 바로 커널의 공유 가중치 때문이다. 오차 역전파 시 커널의 그래디언트를 계산할 때 9개에 대해서만 업데이트하면 되므로 완전 연결층을 사용할 때보다 연산량이 훨씬 적다는 장점이 있다.
채널
채널은 입력 이미지를 구성하는 2차원 배여의 개수를 나타낸다. 흑백 이미지는 단이 ㄹ채널, 즉 채널의 개수가 1개인 이미지다. 하지만 컬러 이미지의 경우 R, G, B, 3개의 채널을 가지는 이미지이므로 채널 이미지 3장이 겹쳐서 컬러 이미지로 표현된다.
컬러 이미지와 같이 입력 이미지가 여러 개의 채널을 갖는 경우, 합성곱 연산을 수행할 때 특성맵의 생성 과정을 잘 살펴봐야 한다. 우선 입력 이미지의 채널 개수만큼 커널이 생성되고, 각 채널마다 하나씩 커널을 적용하여 합성곱 연산을 수행한다. 이 과정을 거치면 입력 이미지의 채널 개수만큼 합성곱 연산된 결과가 생성되고, element-wise 덧셈 연산으로 모두 어해주면 최종 특성맵이 생성된다.

만약 합성곱 레이어에 출력 필터의 개수를 20개로 설정했다면, 입력 이미지의 채널 개수 개와 출력 필터의 개 수 20개가 곱해져 총 50개의 커널이 생성된다. 1개 커널의 사이즈가 3 x 3으로 설정했다면, (3 x 3 x 입력 채널 수 x 출력 채널 수) = 3 x 3 x 3개(R, G, B) x 20개(출력 필터 수) = 540개가 된다. 즉 해당 층에서 업데이트할 가중치의 그래디언트는 540개가 된다.
여기에 bias가 추가로 계산되는데 20개의 출력 필터 개수만큼 추가된다.
스트라이드 (stride)
커널은 좌측 상단으로부터 입력 이미지를 기준으로 우측으로 이동하면서 합성곱 연산을 계속 수행하고 특성맵에 결과를 채워나간다. 이때 이동하는 간격을 스트라이드로 정의하며, 주로 1 또는 2로 설정한다.
스트라이드를 1로 설정 시 커널은 우측으로 1픽셀씩 이동하게 되며, 커널이 입력 이미지의 우측 끝까지 이동했다면 아래 방향으로 1칸 좌측 첫 번째 픽셜로 이동하여 추출한다. 스트라이드를 2로 설정하게 되면 2픽셀씩 건너뛰기 때문에 특성맵의 크기가 1/2로 줄어들게 된다.

텐서플로 케라스에서 제공하는 Conv2D 레이어의 strides 매개변수에 스트라이드를 지정할 수 있다.
패딩(padding)
커널 크기가 3 x 3이고, 스트라이드에서 1로 설정하게 되는 경우에도 추출된 특성맵의 사이즈는 입력 이미지 대비 가로로 2픽셀, 세로로 2픽셀씩 줄어들게 된다. 하지만 추출된 특성맵의 크기가 입력 이미지 대비 줄어들지 않도록 패딩을 설정할 수 있다.
앞의 그림과 같이 일반적으로 zero-padding을 사용하게 되며, 입력 이미지의 가장 자라에 0으로 채워진 패딩 값으로 채운 후 추출하게 된다. 패딩을 적용한 후 합성곱 연산을 수행하게 되면 특성맵의 크기가 줄어들지 않는다.

텐서플로 케라스의 Conv2D 레이어에서 padding = 'same'으로 설정하면 zero-padding을 적용한다. 기본값은 padding = 'valid'이다.
풀링(pooling)
풀링 레이어는 추출된 특성맵에 대해 다운 샘플링하여 이미지의 크기를 축소하는 레이어다. 풀링 레이어를 사용하면서 얻을 수 있는 이점으로는 이미지 축소를 통해 연산량을 감소한다는 점과 과대적합을 방지함에 있다. 풀링 레이어는 크게 최대 풀링과 평균 풀링으로 나뉜다. 최대 풀링은 특징의 값이 큰 값이 다른 특징들을 대표한다는 개념으로 도입되었으며 생각보다 좋은 성능을 발휘하기 때문에 합성곱 신경망과 같이 주로 사용된다.
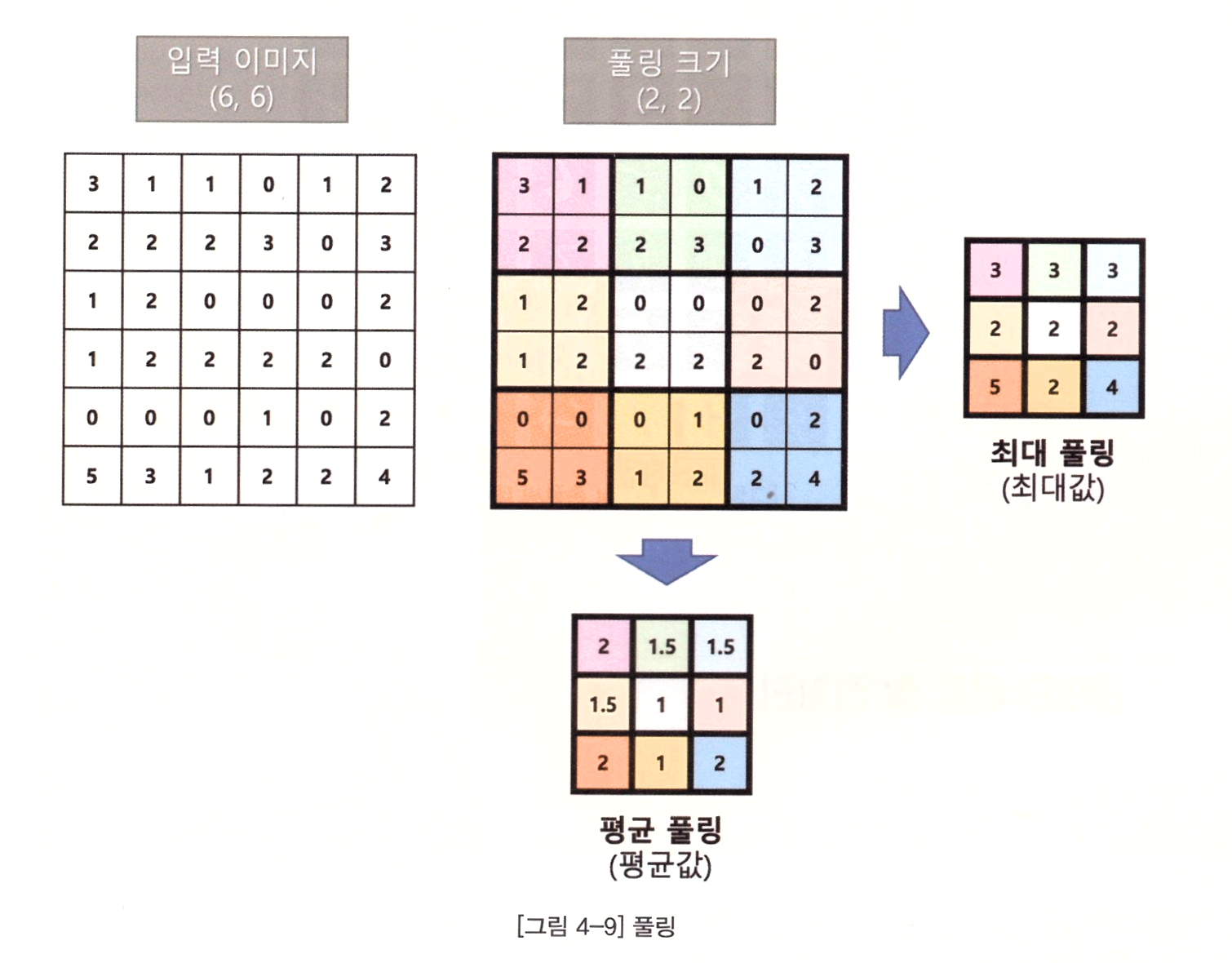
최대 풀링 수행 시 커널의 크기가 2 x 2로 주어졌을 때 입력 이미지의 2 x 2 픽셀 중 최댓값이 출력 값으로 선택된다. 평균 풀링을 수행하면 2 x 2 픽셀들의 평균값이 출력 값으로 나온다. 풀링 레이어도 역시 스트라이드 값을 가지며 스트라이드를 2로 설정하면, 2칸씩 건너뛰면서 풀링을 수행한다. 최대 풀링 커널 크기를 2 x 2로 설정하고, 스트라이드를 2로 설정 시 출력 이미지는 입력 이미지 대비 세로 1/2, 가로 1/2로 줄어들어 입력 이미지 대비 총 1/4 크기로 줄어든다.
학습을 마치고
먼저 합성곱 신경망에 대한 개념을 살펴보는 학습을 진행했다. 이 내용을 3번째 학습을 하다 보니 이제는 많이 이해가 되는 내용도 있었다. 아직 잘 모르는 개념도 있지만 그 부분도 나중에 분명 이해가 될 것 같다.
이 단원에서는 코드를 작성하는 내용은 없었지만 그림을 잘 살펴보며 어디서 숫자가 옮겨지고 바뀌는지 잘 파악해야 한다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 합성곱 신경망 3 - 간단한 모델 생성 2 : 모델 구조 파악 (0) | 2024.10.29 |
|---|---|
| 합성곱 신경망 2 - 간단한 모델 생성 1 : 데이터 로드 및 전처리와 Sequential API로 모델 생성 및 학습 (0) | 2024.10.28 |
| CNN 3 - 개와 고양이를 분류하는 실습 1 : 이미지 파일 분류 (0) | 2024.10.28 |
| CNN 2 - 합성곱 신경망 실습해보기 (0) | 2024.10.28 |
| CNN 1 - CNN 이미지 분석과 필터 그리고 패딩에 대하여 (0) | 2024.10.28 |



