
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 딥러닝
- pandas
- 코딩테스트
- 컴퓨터비전
- 자바
- SQL
- CSS
- 파이썬라이브러리
- numpy/pandas
- html/css
- 데이터분석
- 데이터입출력구현
- C++
- 운영체제
- 정보처리기사실기
- 머신러닝
- 영어공부
- 파이썬
- 자바 실습
- 연습문제
- 정수와유리수
- 혼공머신
- 중학1-1
- 중학수학
- 정보처리기사필기
- 컴퓨터구조
- 텍스트마이닝
- 데이터베이스
- CNN
- JSP/Servlet
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
CNN 10 - Image Segmentation 1 : 이미지 분할 원리와 종류, 기술의 발전 그리고 FCN이 등장하기까지 본문
CNN 10 - Image Segmentation 1 : 이미지 분할 원리와 종류, 기술의 발전 그리고 FCN이 등장하기까지
huenuri 2024. 10. 31. 22:03아침 시험이 끝나고 오후 시험 전까지 30분 정도 시간이 남을 것 같아 새벽에 공부하다 말았던 부분부터 다시 학습을 시작해볼까 했었다. 근데 YOLO 모델로 새벽에 코드를 실행하다 너무 오래 걸려서 중간에 끊었던 게 마음에 걸려 다시 실행하게 되었다. GPU가 부족해서 지금은 예제를 실습해볼 수가 없어 조금 기다려야 할 것 같다.
오후에 Spring 시험도 잘 마치고 아침에 하지 못한 운동도 하고 오랜만에 장도 보면서 신선한 먹거리도 구입하니 정말 좋았다. 자취생활이 1년이 넘어가니 이젠 혼자서 잘할 수 있는 일들이 정말 많아졌다. 정리와 청소는 이제 좋은 습관으로 자리잡았고 인스턴트 음식도 점차 멀리하게 된다.
요즘에는 스스로 음식도 만들어 먹고 싶은 마음이 들기도 했다. 조만간 요리의 즐거움도 느끼지 않을까 싶다. 화장실 청소까지 깔끔하게 하고 저녁을 먹으니 얼마나 기분이 상쾌하고 기쁜지 모른다. 이제 저녁 공부를 하며 하루를 마무리하려고 한다. 난 학습일지를 쓰며 처음과 끝에 나의 일상에 대한 이야기도 쓰곤 한다.
따로 일기를 쓰지 않으니 이곳에 흔적을 남겨 두면 이때 내가 어떤 생각을 하며 사는지 알 수 있을 테니까. 이제 공부를 1시간 하고 하루를 마무리하려고 한다. 이번주에는 행사가 많아 공부 일정이 많이 미뤄지고 있지만 그래도 괜찮다.
Image Segmetation이란 무엇인가?


CNN은 특징을 강조하고 Pooling은 불필요한 부분을 삭제한다. 예를 들면 토기라고 생각되는 부분이 강조되고, 나머지 영역은 값이 낮아진다. 이들을 반복하게 되면 중요한 정보만 압축이 되고, 마지막이 이 압축된 정보를 수행하기 위해 Multi Layer Percept론인 MLP로 평균값을 예측한다.

여기에 객체의 위치 정보까지 함께 알아내는 기술이 객체 탐지이다. YOLO에서는 네모 박스가 중요한데 이것을 Bounding Box이다. Bounding Box 표기법은 매우 중요한데 두 가지가 있다.
첫번째는 시작 좌표와 끝 좌표를 표기하는 방식이다. 두 좌표만 알면 나머지 두 좌표는 알 수 있다. 두번째는 중심 좌표와 가로, 세로 정보를 저장하는 방식이다. 그리고 너비와 높이 정보를 함께 저장한다. YOLO에서는 두번째 표기법을 사용한다. 사용 전 어떤 표기법으로 되어 있는지 먼저 확인 해야한다.
이미지 분할은 이미지의 영역을 정확하게 맞추는 것을 말한다. 이 기법은 자율주행에도 많이 사용되는데 영상 기반으로 거리를 잴 때 자주 사용된다.


왼쪽은 오리지널 데이터이고 오른쪽은 세그멘테이션으로 예측을 수행한 결과값이다. Segmentation이란 이미지 안에 들어있는 픽셀 하나 단위로 예측을 수행하는 것을 말한다. Classification은 전체 영역을, 객체 탐지는 일부 영역만 잘라서 예측을 수행했다.

그림을 보면 3, 4, 2의 영역으로 나누어져 있는 것을 확인할 수 있다. 결국은 분류를 하는 것이다.
Segmentation의 종류


Semantic은 의미론적으로 같은 영역을 분할하는 개념이다. 길의 영역, 양의 역역 등으로 각각의 픽셀들이 같은지 다른지 분할되어 있다. 같은 양들도 하나로 친다. Instance는 각각의 개체를 구별한다.
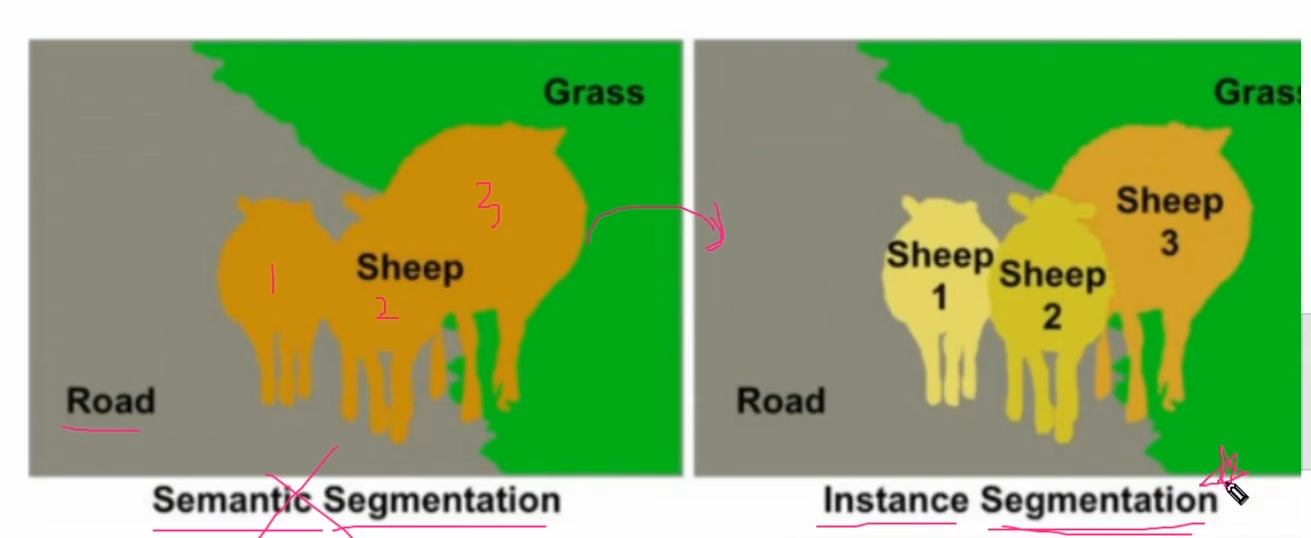
보편적으로는 Instance Segmetation을 많이 사용한다.

추상화는 구체적인 정보가 있을 때 그것을 간추려서 간략하게 만드는 것을 말한다. 예를들어 자바에서 여러 객체가 있을 때 공통된 특징을 추출해서 Car라는 클래스를 만들 수 있다. 이미지 분할에서도 마찬가지로 CNN과 Pooling을 통해 강조와 삭제가 반복되면 이미지가 추상화된다.
CNN 동작 원리에서 오리지널 이미지가 있을 때 커널이 3 x 3으로 9개씩 이동하면서 숫자를 하나씩 묶어가며 픽셀 정보를 도출한다. 색상 정보가 묶여서 가기 때문에 원래 원본 이미지의 정보보다는 압축된 정보들이 모여 정보가 만들어진다. 하지만 이렇게 하면 색상 정보는 모이지만 위치 정보는 소실된다. 따라서 9개씩 묶어서 연산한다.

따라서 이런 문제로 인해 기존 Segmentation으로는 바로 활용할 수 없었다. 이미지 분할은 각 픽셀 영역에서 어디 영역에 속하는지를 맞춰야 한다. 그러면 픽셀의 위치 정보가 그대로 유지되어야 한다. 이러한 문제점을 해결하기 위해 등장한 것이 Fully Convolutional Network(FCN)이다.


오리지널 데이터를 CNN과 Polling을 거치면서 줄여 나간다. 그리고 마지막에 만들어진 레이어에 MLP를 거치면서 붙여준다. 평평하게 붙여주는 Flatten 작업도 하는데 그 이유는 다음과 같다. MLP는 데이터가 1차원으로 들어가야 하는데 CNN과 Pooling을 지나면서 위치 정보가 소실되었다. 2차원 정보를 유지할 필요가 없기에 Flatten해서 평평하게 만드는 것이다.

하지만 FCN에서는 MLP가 더이상 필요 없다. 특징이 아닌 픽셀에 대한 정보가 필요하기에 MLP를 제거한다. 대신 마지막층을 Convolution으로 끝낸다.
FCN은 마지막 레이어의 압축된 정보를 토대로 원래 크기의 CNN 레이이로 복원시키는 것을 붙인다. 여기서 착안해서 모델들을 발전시킨 것이 Incoder, Decoder이다.


앞쪽은 압축을 했기에 인코더를 뒤쪽은 복원을 했으므로 디코더를 수행한다. 이 구조가 정립되면서 Segementation이 한 획을 긋게 된다. 이 구조는 자연어 처리에서도 등장한다. 딥러닝은 한쪽에서 유명하면 다른 쪽에서 이를 흡수해서 넘어가는 경우가 많다.
원래 구조로 복원하는 것을 Upsampling이라고 한다. 기존처럼 하나의 픽셀 크기로 복원하는 것이 아닌 단계적으로 크기를 키워나가면서 복원한다. 한 가지 특징은 복원시 Skip Connection을 활용한다.

앞쪽이 인코더, 뒤쪽이 디코더인데 이미지를 보면 픽셀 정보를 Downsampling하여 정보를 축약시키며 픽셀 정보가 점차 줄어든다. 마지막에는 하나만 남는 순간이 온다. 이때 원본 이미지를 한번에 보관하지 않고 여러 개를 분할하는 Upsampling을 선택한다. 마지막에 압축된 정보가 아닌 이전의 정보를 참조하여 Upsampling한다. 그 이유는 마지막에 있는 정보는 너무 압축이 되어 이것으로 결과물을 만들면 정보가 좋지 못하기 때문이다. 그렇기에 위치 정보가 살아있는 압축이 덜 된 정보를 참조한다. 이런 것을 Skip Connection이라고 부른다.

Skiip Connection을 사용하면서 예측에 대한 결과물의 향상도가 올라가고 연산 속도로 떨어진다. 결론적으로는 더 많은 정보를 넣어 더 좋은 결과물을 만들 수 있게 된 것이다.
학습을 마치고
어제 저녁에 공부하려던 부분인데 너무 졸려서 처음 부분만 학습했다가 오늘 새벽 3시 반에 일어나서 1시간 동안 더 학습을 진행했다. 선생님이 다른 선생님으로 바뀌어서 이틀 동안 수업을 진행하셨는데, 개념을 자세하게 설명해주시는 부분이 좋았다.
앞 부분을 강의하셨던 선생님은 또 다른 좋은 부분이 있었다. 어쨌든 두 명의 선생님이 번갈아서 수업을 진행하시는 것도 나름 괜찮았다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| CNN 12 - Image Segemtation 3 : 차량 파손범위 예측 실습하기 전에 알아두어야 할 사항 (1) | 2024.11.02 |
|---|---|
| CNN 11 - Image Segmentation 2 : YOLOv8을 이용한 이미지 분할 실습해보기 (0) | 2024.11.01 |
| 합성곱 신경망 11 - 객체 탐지 3 : YOLO 객체 탐지 2 <나만의 YOLO 모델 생성> (1) | 2024.10.31 |
| 합성곱 신경망 10 - 객체 탐지 2 : YOLO 객체 탐지 1 <Darknet YOLO 모델 추론하기> (0) | 2024.10.31 |
| 합성곱 신경망 9 - 객체 탐지 1 : 텐서플로 허브 활용 (1) | 2024.10.31 |



