
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- pandas
- 머신러닝
- 텍스트마이닝
- 자바
- 자바 실습
- 영어공부
- 정보처리기사필기
- SQL
- 코딩테스트
- 파이썬
- CNN
- 딥러닝
- CSS
- 중학1-1
- 혼공머신
- 컴퓨터비전
- 데이터분석
- 중학수학
- C++
- 운영체제
- html/css
- 파이썬라이브러리
- JSP/Servlet
- numpy/pandas
- 연습문제
- 컴퓨터구조
- 데이터입출력구현
- 정수와유리수
- 데이터베이스
- 정보처리기사실기
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
합성곱 신경망 12 - 이미지 분할(Segmentation) 본문
이제 오늘 오후에는 책으로 합성곱 신경망을 학습하고 모두 끝낼 생각이다. 아침에 예배를 갔다 와서 새벽에 하지 못했던 운동도 하고 샤워도 하니 개운하니 정말 좋다.
점심을 먹기 전에 잠깐 공부를 하며 워밍업을 한 후 식사 후에 나머지 부분을 하게 될 것 같다.
이미지 분할에 대하여
이미지 분할 또는 세그멘테이션은 이미지를 구성하는 모든 픽셀에 대해 픽셀 단위로 분류하는 것이다. 즉, 모든 픽셀은 어떤 클래스에 속한다. 예를 들어 배경 클래스와 객체 클래스로 구성된 이미지가 있다면, 모든 픽셀은 배경 또는 객체 중 하나로 분류된다. 이렇게 모든 픽셀에 대한 정답 클래스를 레이블 처리한 데이터셋을 가지고, 딥러닝 모델을 훈련시키면 정답 클래스를 알지 못하는 새로운 이미지에 대해서로 배경과 객체를 분리할 수 있다.

이미지 분할은 의미 분할(semantic segmentation)과 인스턴스 분할(instance segemtation)로 구분된다. 의미 분할은 같은 범주의 여러 객체를 하나의 범주로 묶어서 구분하지만, 인스턴스 분할은 같은 범주에 속하더라도 서로 다른 객체를 구분하는 개념이다.

1. 데이터셋 준비하기
이미지 분할에 사용할 데이터셋은 Oxford-IIIT Pet Datatset이다. 이 데이터셋은 반려동물의 이미지 및 분류 레이블, 각 이미지를 구성하는 픽셀 단위의 마스크로 구성되어 있다 여기서 말하는 마스크는 각 픽셀에 대한 범주 레이블을 나타낸다. 각 픽셀은 다음 세 가지 범주 중 하나에 속한다.
- class 1 : 반려동물이 속한 픽셀(다음 그림의 노란색 영역)
- class 2 : 반려동물과 인접한 펙셀(빨간색 영역)
- class 3 : 위에 속하지 않는 경우/ 주변 픽셀(파란색 영역)

영상 처리를 위한 OpenCV를 비롯한 필수 라이브러리를 다음과 같이 먼저 불러온다.

모델 학습에 필요한 입력 이미지의 크기와 학습 파라미터를 설정한다. 이런 방식으로 주요 파라미터를 따로 정리하면 모델의 세부 튜닝 작업을 효율적으로 할 수 있다.

텐서플로 데이터셋에서 옥스포드 반려동물 데이터를 불러온다. 메타 정보를 가져와서 info 변수에 저장한다.

원본 이미지와 분할 마스크를 전처리하는 함수를 정의한다. 이미지 크기를 사전에 정의한(128, 128) 크기로 변경하고 자료형을 변환한다. 원본 이미지의 픽셀을 255로 나눠서 0~1 범위로 정규화한다. 마스크는 0, 1, 2의 정수형 값만 갖도록 1을 차감한다.

앞에서 정의한 전처리 함수를 훈련 셋, 테스트 셋에 매핑해 주고 미니배치로 분할한다.

샘플 배치를 한 개 선택한다. 배치에는 16개의 샘플 이미지와 마스크 이미지가 들어 있다.

배치에서 첫번째 이미지를 출력한다. 0~1 사이의 값이므로 255를 곱해서 정규화 이전의 원래 값으로 복원했다.

마스크 이미지를 출력한다. 마스크 값의 범위는 0~2이므로 2로 나눈 다음에 255를 곱하면 RGB 이미지로 표현할 수 있다.

위 이미지는 랜덤 수인지 출력할 때마다 다르게 나온다.
2. U-Net 모델(인코더-디코더)

사전 학습된 VGG16 모델을 인코더라 활용하는 U-Net 모델을 만들어 본다. VGG16은 이미지넷 경진 대회를 통해 성능이 검증된 모델이다. 사실 사전 학습된 모델 없이 U-Net을 구성하여 학습을 진행해도 학습은 된다. 단, 데이터 개수가 충분하고, 시간이 충분하다는 전체에서 말이다.
구글 코랩 환경에서 제한된 자원으로 양호한 성능을 갖는 모델을 만들기 위해서 사전 학습된 모델을 베이스모델로 활용하는 전이 학습 방법을 사용하기로 한다.
먼저 VGG16 모델을 최종 레이어를 제외한 채로 불러온다.

VGG16 모델은 합성곱 층과 풀링 층을 직렬로 연결한 구조를 갖는다. 다음 코드의 실행 결과에서 모델 구조를 보면 (128, 128) 크기의 텐서가 마지막 레이어에서는 (4, 4) 크기로 축소되는 것을 확인할 수 있다.
이 모델을 U-Net의 인코더로 사용할 예정이다. 인코더는 원본 이미지 중에서 같은 범주에 속하는 픽셀을 결합하면서 점진적으로 이미지를 더 작은 크기로 축소한다. 다시 말하면, 마스크 정답을 활용하여 각 픽셀의 마스크 범주를 0, 1, 2 중에서 하나로 분류하는 역할을 한다.


만들고자 하는 U-nET의 모양을 미리 정하고, 사전 학습된 모델에서 어느 부분의 어떤 shape의 출력을 가져올지 먼저 정한다. VGG16 모델의 중간 레이어 중에서 필요한 출력 텐서를 지정하여, 다양한 피처(특징)를 추출하는 인코더 모델을 정의하게 된다.
여기서는 VGG16 모델로부터 5개의 출력을 가져와서 사용한다. 다음과 같이 새로운 Feature Extrator 모델을 정의하고, f_model 변수에 저장한다. 1개의 입력과 5개의 출력을 갖는다.

사전 학습된 파라미터를 인코더에 그대로 사용하기 위해서 업데이트되지 않도록 고정한다.

인코더 부분에서 5개의 출력을 가져와서 디코더의 입력으로 전달하면서 업샘플링한다. 업샘플링은 축소된 이미지를 원래 이미지 클기로 복원하는 과정을 말한다. 제일 작은 (8, 8, 512) 텐서에서 시작해서 조금씩 크기를 키워 나가며 중간 출력과 합친다.


U-Net 모델을 시각화한다. 인코더의 중간 출력이 업샘플링 과정에서 디코더의 중간 출력과 합치지는 것을 확인할 수 있다. 각 레이어의 입출력 텐서 크기를 잘 살펴본다.


모델 구조를 요약하면 다음과 같다. 인코더 출력에 사용하기 위해 f_model로부터 유래하는 2개 레이어의 14,714,688개의 파라미터는 학습되지 않도록 고정돼 있다.


예측 클래스 개수가 3개인 다중 분류 문제에 맞도록 SparseCategoricalCrossentropy 손실함수를 설정하고, Adam 옵티마이저를 적용한다. 기본 성능을 확인하는 수준에서 5 epoch만 훈련한다.

이 코드를 실행하다 GPU를 한 번 더 구입했다. 지난번에 구입한지 일주일도 되지 않아서 다 써버려서 이번에는 최대한 늦게 구입하고 싶었으나 T4도 되지 않고 너무 느렸다. 공부하려면 돈을 아낌없이 투자해야 할 것 같았다.
검증 셋의 배치를 하나 선택하고 predict() 메서드로 이미지 분할 클래스를 예측한다. 배치를 구성하는 16개의 이미지 중에서 첫 번째 이미지의 분할 결과를 노트북에 출력한다.

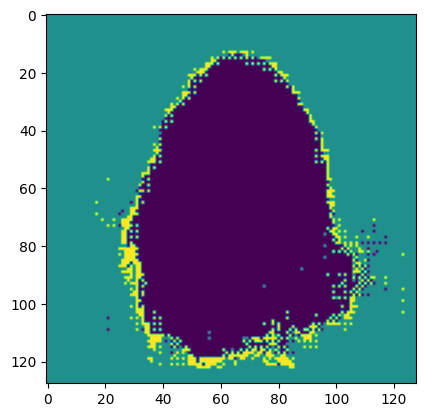
그림이 마음에 들지 않아 3번이나 출력했으나 비슷해서 그냥 이걸로 출력하기로 했다.
정답 마스크 이미지를 출력하고, 앞서 예측한 분할 이미지와 비교한다. 어느 정도 객체의 경계를 찾아내는 것을 확인할 수 있다.

학습을 마치고
학습 분량이 많았으나 끊기가 애매해서 그냥 모두 한번에 정리해 보았다. GPU도 중간에 구입했는데 조금 아깝기는 하지만 그래도 딥러닝을 공부하려면 어쩔 수 없는 것 같다. T4도 무료 버전은 제한이 있어서 어느 정도 사용하면 더 이상 쓸 수가 없다. 요즘은 하루종일 딥러닝을 공부하다 보니 GPU가 많이 부족하다.
이번에는 최대한 아껴서 사용해볼 것이다. 지난번에는 구입한 지 일주일 만에 다 썼다. 이미지 분할 실습은 수업 시간에 열심히 공부해서 그런지 별로 어렵지 않았다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 합성곱 신경망 14 - GAN(생성적 적대 신경망) 동영상 파일로 만들기 (1) | 2024.11.03 |
|---|---|
| 합성곱 신경망 13 - Knowledge Distillation (0) | 2024.11.03 |
| CNN 18 - 이미지 생성 모델 실습해보기 2 : 이미지 인페인팅으로 특정 부분 채우기 (2) | 2024.11.03 |
| CNN 17 - 이미지 생성 모델 실습해보기 1 : Stable Diffusion 기초 실습 (0) | 2024.11.03 |
| CNN 16 - 이미지 생성 모델의 이해 2 : Diffusion 모델의 잡음 예측기 학습 및 예측 과정과 다양한 활용법 (0) | 2024.11.03 |



