
- 분류 전체보기 (1853)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 정보처리기사필기
- 파이썬
- JDBC
- 스프링
- SQL
- 자바스크립트
- JSP
- 데이터베이스
- 컴퓨터비전
- 쇼핑몰홈페이지제작
- ChatGPT
- 자바
- 타입스크립트심화
- JSP/Servlet
- 연습문제
- 정보처리기사실기
- 중학수학
- 상속
- 디버깅
- 자바스크립트심화
- 딥러닝
- 데이터분석
- 자바 실습
- 중학1-1
- 머신러닝
- 혼공머신
- 개발일기
- rnn
- html/css
- 스프링프레임워크
- Today
- Total
"게임 개발자"를 향한 매일의 공부일지 1기 : 2024년 5 ~ 12월
프롬프트 비식별화 2 - 식별자 마스킹과 가짜 식별자 생성 본문
비식별화 단원을 이어서 학습해 보겠다. 이번에는 두 개의 이론 학습을 이어서 진행할 것이다.
이론 2 - 식별자 마스킹

식별자는 특정한 이름을 가지는 경우가 많다.

이러한 모델들은 많이 공개되어 있다. 이 내용을 통해서 일반 단어, 수, 기관 등을 감시해 낼 수 있다.

각각의 단어가 개체명인지 알아낸다.
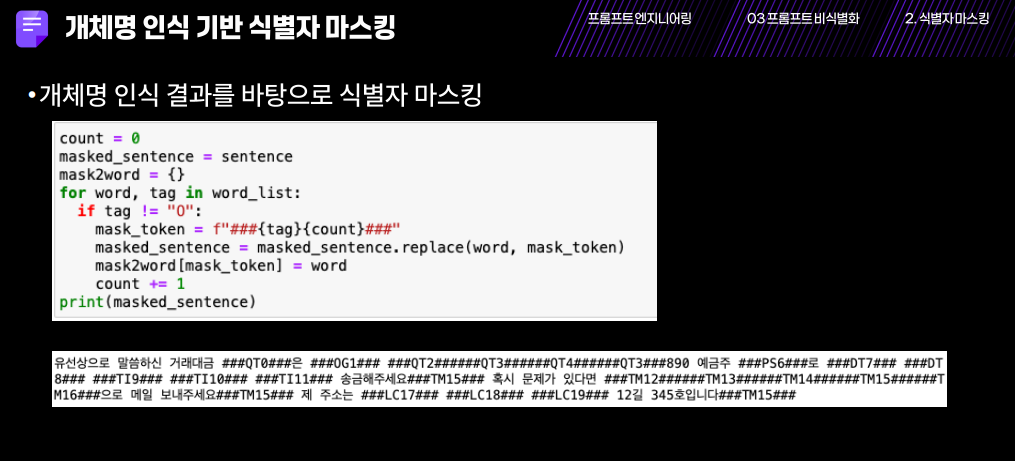
단순히 단어를 지우면 어색한 문장이 되므로 해당 위치에 어떤 단어가 있었는지 약간의 힌트를 준다.

마스킹 단어를 영어로 번역하면 실제로 이런 결과물을 보여준다.

원래 단어로 원상 복구해주기도 한다. 이런 식으로 ChatGPT를 사용하면 민감 정보를 제거하여 ChatGPT 서버로 저장되지 않게 할 수 있다.
이론 3 - 가짜 식별자 생성

식별자 마스킹을 통해 번역했을 경우 계좌번호가 잘리거나 시간을 나타내는 부분이 잘못 출력되기도 한다. 한 문장에 여러 숫자가 있을 경우에는 대응되는 숫자를 찾기 어렵다.

손실되는 정보를 최소화하여 프롬프팅을 올바르게 하도록 만든다. 가짜 식별자를 사용할 때는 Faker라는 라이브러리를 활용한다. 한국어가 지원되므로 한국어 정보도 생성할 수 있다.

가짜 식별자를 채울 때는 조금 더 정교한 방식으로 처리할 필요가 있다.

번역을 할 때 영어와 한국어의 이름이 달라 원상복구에서 어려움이 있다.
퀴즈 3 - 가짜 식별자 생성의 효과


학습을 마치고
이론 수업과 퀴즈 문제까지 모두 풀었고 이제 실습 예제 하나만이 남아있다. 언제 이 공부를 다 마치나 했는데 오늘 하루 만에 다 마치게 된다. 가짜 식별자를 채움으로 민감 정보가 유출되지 않도록 하는 방법이 있다는 것도 알게 되었다. 원상 복구를 할 때 차이가 있기는 해도 이런 식으로 개인 정보를 보호할 수 있다는 것만으로도 큰 수확이었다.
'인공지능 > 프롬프트 엔지니어링 & 생성형 AI' 카테고리의 다른 글
| 거대 언어 모델(LLM)이란? 1 - 거대 언어 모델이란 (0) | 2024.12.21 |
|---|---|
| 프롬프트 비식별화 3 - 프롬프트 비식별화 실습 (0) | 2024.12.20 |
| 프롬프트 비식별화 1 - 프롬프트 보안의 필요성 (0) | 2024.12.20 |
| 프롬프트 관련 확장 프로그램 6 - Langchain : 도구, 검색과 융합된 ChatGPT 2 <문제 2~5번> (0) | 2024.12.20 |
| 프롬프트 관련 확장 프로그램 5 - Langchain : 도구, 검색과 융합된 ChatGPT 1 <1번 문제> (0) | 2024.12.20 |



