
- 분류 전체보기 (1243)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- C++
- 자바
- 컴퓨터구조
- 혼공머신
- 데이터입출력구현
- 딥러닝
- 데이터베이스
- 중학수학
- CSS
- html/css
- CNN
- 정보처리기사실기
- 데이터분석
- JSP/Servlet
- 중학1-1
- 연습문제
- 코딩테스트
- numpy/pandas
- 텍스트마이닝
- 운영체제
- 자바 실습
- SQL
- 정수와유리수
- 파이썬
- pandas
- 컴퓨터비전
- 영어공부
- 파이썬라이브러리
- 정보처리기사필기
- 머신러닝
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
비지도 학습 3 - k-평균 1 : k 평균 알고리즘으로 주어진 정보가 없는 상태에서 과일 사진 분류하기 본문
이번에는 평균 알고리즘에 대해 학습해 보겠다.
학습 목표
k-평균 알고리즘의 작동 방식을 이해하고, 과일사진을 자동으로 모으는 비지도 학습 모델을 만들어본다.
시작하기 전에
이전 학습에서 사과, 파인애플, 바나나에 있는 각 픽셀의 평균값을 구하서 가장 가까운 사진을 골랐다. 하지만 진짜 비지도 학습에서는 사진에 어떤 과일이 들어있는지 알지 못한다.
이런 경우 어떻게 평균을 구할 수 있을까?

바로 k-평균 군집 알고리즘이 평균값을 자동으로 찾아준다. 이 평균값이 클러스트의 중심에 위치하기 때문에 클러스트 정 심 또는 센트로이드라고 부른다.
k-평균 알고리즘 소개
k-평균 알고리즘의 작동 방식은 다음과 같다.
- 무작위로 k개의 클러스터 중심을 정한다.
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
- 클러스터 중심에 변화가 없을 때까지 2번으로 똘아가 반복한다.
이를 그림으로 나타내면 다음과 같다.
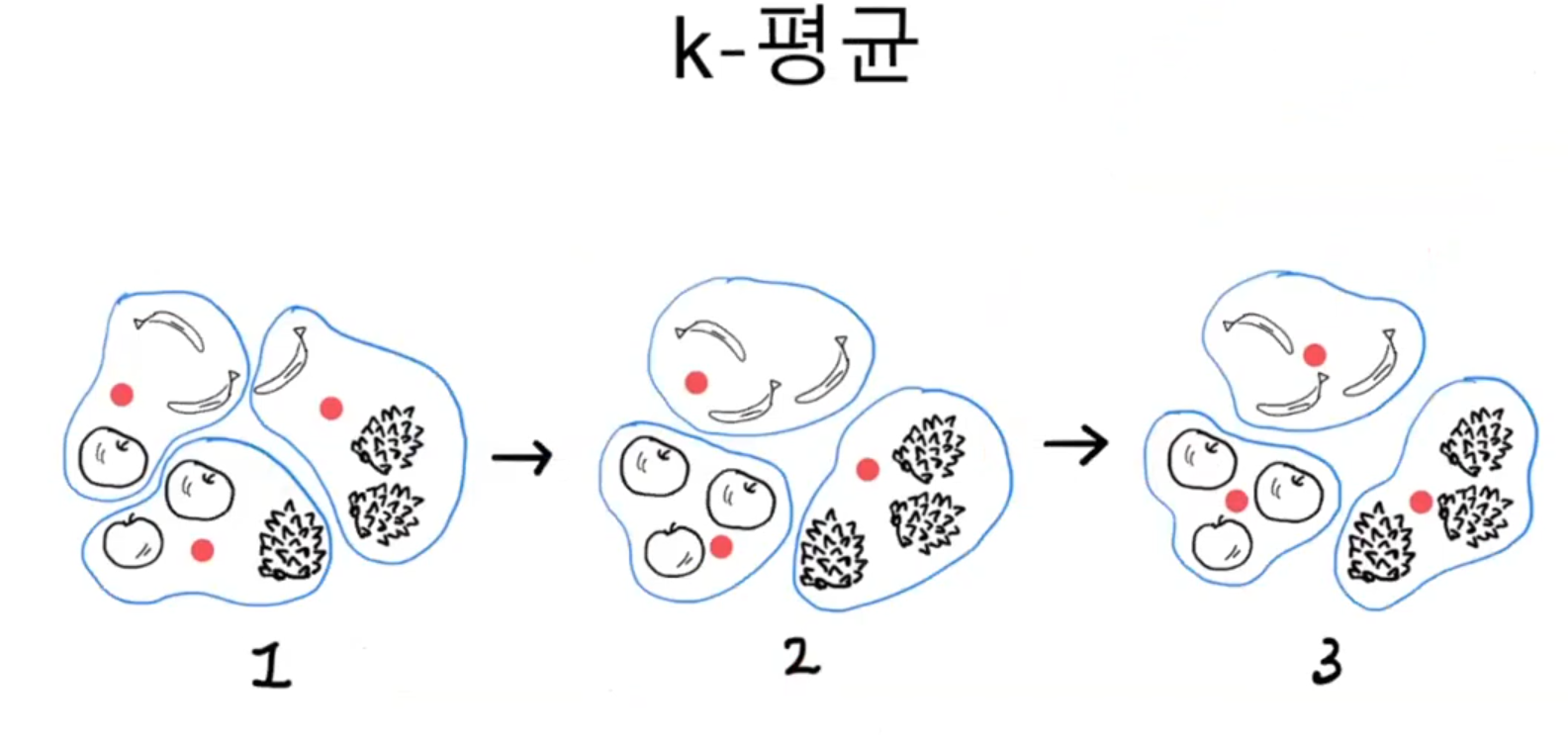
먼저 3개의 클러스터 중심(빨간 점)을 랜덤하게 지정한다(1). 그리고 클러스터 중심에서 가장 가까운 샘플을 하나의 클러스터로 묶는다. 클러스터에는 순서나 번호는 의미가 없다.
그다음 클러스터의 중심을 다시 계산하여 이동시킨다. 맨 아래 클러스터는 사과 쪽으로 중심이 조금 더 이동하고 왼쪽 위의 클러스터는 바나나 쪽으로 중심이 이동하는 식이다. 클러스터 중심을 다시 계산한 다음 가장 가까운 샘플을 다시 클러스터로 묶는다(2). 이제 3개의 클러스터에는 바나나와 파인애플, 사과가 3개씩 올바르게 묶여있다.
이동된 클러스터 중심에서 다시 한번 가장 가까운 샘플을 클러스터로 묶는다(3). 중심에서 가장 가까운 샘플은 이전 클러스터(2)와 동일하다. 따라서 만들어진 클러스터에 변동이 없으므로 k-평균 알고리즘을 종료한다.
k-평균 알고리즘은 처음에는 랜덤하게 클러스터 중심을 선택하고 점차 가장 가까운 샘플의 중심으로 이동하는 비교적 간단한 알고리즘이다. 이번에는 사이킷런으로 k-평균 모델을 직접 만들어보겠다.
KMeans 클래스
먼저 파일을 준비하고 k-평균 모델을 훈련하기 위해 (샘플 개수, 너비, 높이) 크기의 3차원 배열을 (샘플 개수, 너비x높이) 크기를 가진 2차원 배열로 변경한다.
KMeans 클래스에서 설정할 매개변수는 클러스터 개수를 지정하는 n_clusters이다. 여기서는 클러스터 개수를 3으로 지정했다.

이 클래스를 사용하는 방법도 다른 클래스들과 비슷하다. 다만 비지도 학습이므로 fit() 메서드에서 타깃 데이터를 사용하지 않겠다. 군집된 결과는 KMeans 클래스 객체의 labels_ 속성에 저장된다. labels_ 배열의 길이는 샘플 개수와 같다.
n_clusters=3으로 지정했기 때문에 labels_ 배열의 값은 0, 1, 2 중 하나이다. 레이블값 0, 1, 2와 레이블 순서에는 어떤 의미도 없다.
레이블 0, 1, 2로 모은 샘플의 개수를 확인한다. 첫 번째 클러스터가 111개를, 두 번째 클러스터는 98개를, 세 번째 클러스터는 91개의 샘플을 모았다. 그럼 각 클러스터가 어떤 이미지를 나타냈는지 그림으로 출력하기 위해 간단한 유틸리티 함수 draw_fruits()를 만들어보겠다.

draw_fruits() 함수는 (샘플 개수, 너비, 높이)의 3차원 배열을 입력받아 가로로 10개씩 이미지를 출력한다. 샘플 개수에 따라 행과 열의 개수를 계산하고 figsize를 지정한다. figsize는 ratio 매개변수에 비례하여 커진다. 기본값은 1이다.
이 함수를 사용해 레이블이 0인 과일 사진을 모두 그려본다. 넘파이는 불리언 인덱싱을 사용해 원소를 선택할 수 있다. 불리언 인덱싱을 적용하면 True인 위치의 원소만 모두 추출한다.
두 번째와 세 번째 레이블도 출력해 보았다.

레이블이 1인 클러스터는 바나나로만, 레이블이 2인 클러스터는 사과로만 이루어져 있다. 하지만 레이블이 0인 클러스터는 파인애플에 사과 9개와 바나나 2개가 섞여 있다.
k-평균 알고리즘은 이 샘플들을 완벽하게 구별하지는 못했다. 하지만 훈련 데이터에 타깃 레이블을 제공하지 않았음에도 스스로 비슷한 샘플들을 아주 잘 모았다.
클러스터 중심
KMeans 클래스가 최종적으로 찾은 클러스터 중심은 cluster_centers_ 속성에 저장되어 있다. 이 배열은 fruits_2d 샘플의 클러스터 중심이기 때문에 각 중심을 이미지로 출력하려면 100 x 100 크기의 2차원 배열로 바꿔야 한다.
KMeans 클래스는 훈련 데이터 샘플에서 클러스터 중심까지 거리로 변환해 주는 transform() 메서드를 가지고 있다. transform() 메서드가 있다는 것은 마치 StandardScaler 클래스처럼 특성값을 변환하는 도구로 사용할 수 있다는 의미이다.

첫 번째 클러스터의 길이가 3393.8로 가장 작다. 이 샘플을 레이블 0에 속한 것 같다. KMeans 클래스는 가장 가까운 클러스터 중심을 예측 클래스로 출력하는 predict() 메서드를 제공한다.
k-평균 알고리즘은 반복적으로 클러스터 중심을 옮기면서 최적의 클러스터를 찾는다. 알고리즘이 반복한 횟수는 KMeans 클래스의 n_iter_ 속성에 속한다.
최적의 k 찾기
k-평균 알고리즘의 단점 중 하나는 클러스터 개수를 사전에 지정해야 한다는 것이다. 실전에서는 몇 개의 클러스터가 있는지 알 수 없다. 어떻게 하면 적절한 k값을 찾을 수 있는지 알아보겠다.
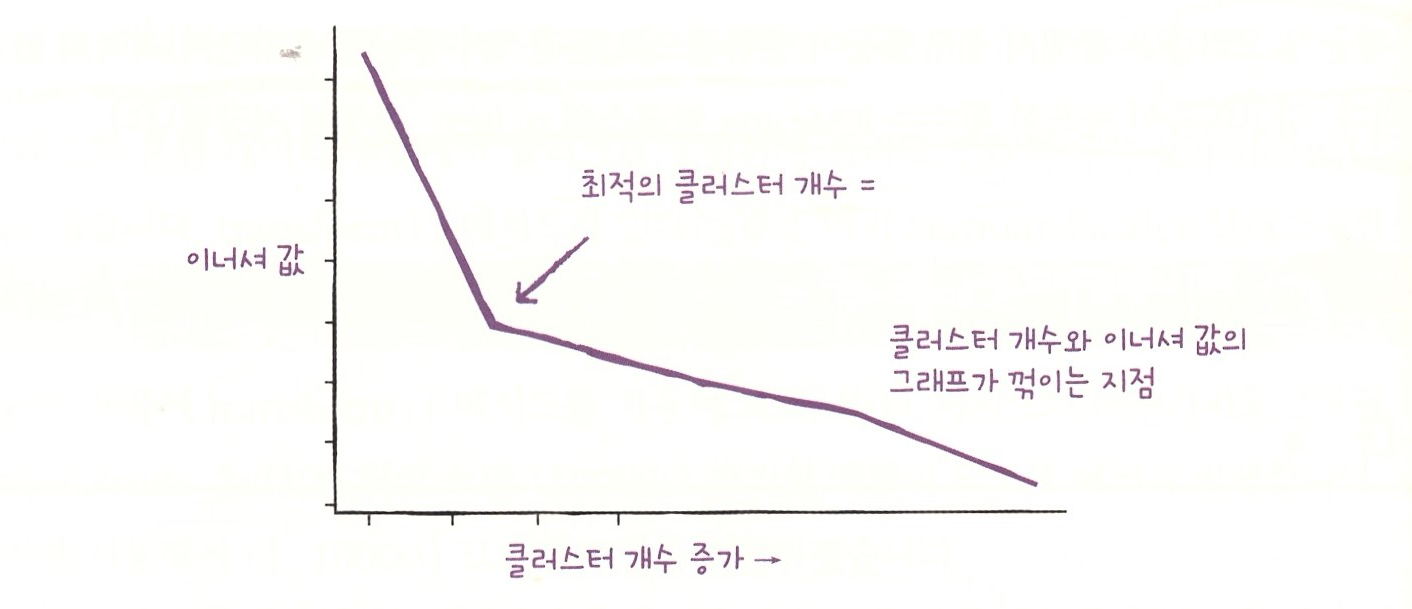
여기서는 적절한 클러스터 개수를 찾기 위한 대표적인 방법인 엘보우 방법을 사용해 본다. k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있다. 이 거리의 제곱 합을 이너셔라고 부른다. 이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값으로 생각할 수 있다. 일반적으로 클러스터 개수가 늘어나면 클러스터 개개의 크기는 줄어들기 때문에 이너셔도 줄어든다. 엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법이다.
클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있다. 이 지점부터는 클러스터 개수를 늘려도 클러스터에 잘 밀집된 정도가 크게 개선되지 않는다. 이 지점이 마치 팔꿈치 모양이어서 엘보우 방법이라 부른다.
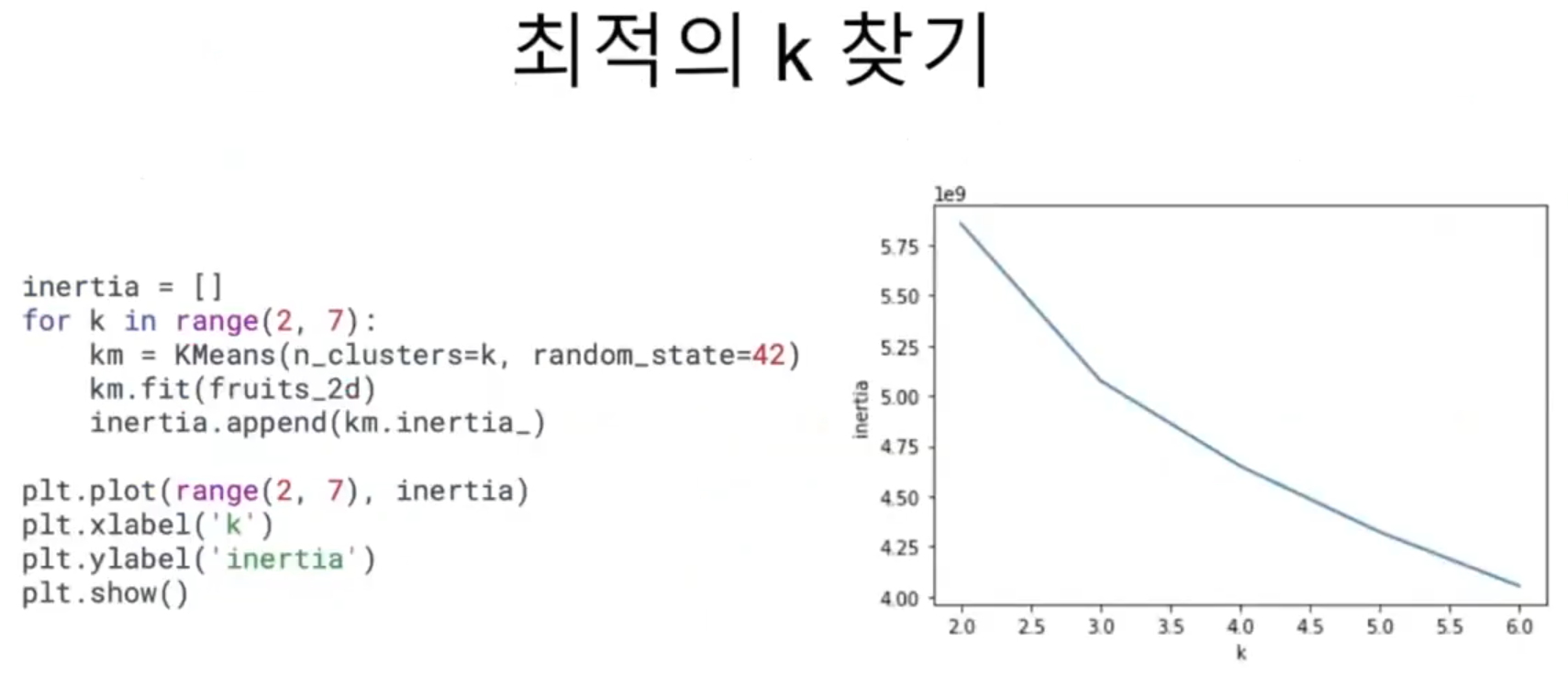
과일 데이터셋을 사용해 이너셔를 계산해 본다. KMeans 클래스는 자동으로 이너셔를 계산해서 inertia_ 속성으로 제공한다. 다음 코스에서 클러스터 개수 k를 2~6까지 바꿔가며 KMeans 클래스를 5번 훈련한다. fit() 메서드로 모델을 훈련한 후 inertia_ 속성에 저장된 이너셔 값을 inertia 리스트에 추가한다. 마지막으로 inertia 리스트에 저장된 값을 그래프로 출력한다.
이 그래프에서는 꺾이는 지점이 두드러지지 않지만, k=3에서 그래프의 기울기가 조금 바뀐 것을 볼 수 있다. 엘보우 지점보다 클러스터 개수가 많아지면 이너셔의 변화가 줄어들면서 군집 효과도 줄어든다.
학습을 마치고
두 번째 장도 학습을 모두 마쳤다. 클러스터라는 새로운 개념도 배우고 어떻게 하면 최적의 k를 찾을 수 있는지 알게 된 단원이었다.
이제 절반 이상 달려왔으니 좀 더 힘을 내서 나머지 아침 공부도 잘 마무리해 볼 것이다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 비지도 학습 5 - 주성분 분석 1 : 주성분 분석으로 차원 축소 알고리즘 사용해보기 (0) | 2024.09.30 |
|---|---|
| 비지도 학습 4 - k-평균 2 : 스스로 실습하고 문제 풀어보는 시간 (0) | 2024.09.30 |
| 비지도 학습 2 - 군집 알고리즘 2 : 스스로 실습하며 문제를 풀어보는 시간 (0) | 2024.09.30 |
| 비지도 학습 1 - 군집 알고리즘 1 : 군집 알고리즘으로 사진을 분류해보기 (0) | 2024.09.30 |
| 트리 알고리즘 6 - 트리의 앙상블 2 : 스스로 실습하고 문제를 풀어보는 시간 (0) | 2024.09.30 |



