
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 중학1-1
- 데이터베이스
- 중학수학
- 파이썬라이브러리
- html/css
- 데이터입출력구현
- 연습문제
- pandas
- 자바
- 머신러닝
- 컴퓨터비전
- 혼공머신
- JSP/Servlet
- numpy/pandas
- 영어공부
- CSS
- CNN
- 운영체제
- 자바 실습
- 파이썬
- SQL
- 컴퓨터구조
- 텍스트마이닝
- 정보처리기사필기
- 코딩테스트
- 딥러닝
- 정수와유리수
- 데이터분석
- 정보처리기사실기
- C++
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
인덱스 3 - 인덱스의 실제 사용 본문
드디어 인덱스의 마지막 장이다. 이번 장에서는 단순 보조 인덱스 및 고유 보조 인덱스를 생성하고 제거하는 방법을 익힌다. MySQL의 실행 계획에서 인덱스를 효율적으로 사용하는 방밥을 알아볼 것이다.
시작하기 전에
인덱스에 대한 개념을 파악한 후에는 실제로 인덱스를 생성하는 SQL을 익혀야 한다. 인덱스를 생성하기 위해서는 CREATE INDEX 문을 사용하고, 제거하기 위해서는 DROP INDEX 문을 사용한다. 기본 형식은 다음과 같다.

보조 인덱스는 데이터의 중복 여부에 따라 단순 보조 인덱스와 고유 보조 인덱스로 나뉜다.
인덱스 생성과 제거 문법
인덱스 생성과 제거에 대한 정확한 문법을 이해하고 활용하는 방법을 익혀보겠다.
인덱스 생성 문법
테이블을 생성할 때 특정 열을 기본 키, 고유 키로 설정하면 인덱스가 자동 생성된다는 것은 이미 확인했다. Primary Key 문법을 사용하면 클러스터형 인덱스가, Unique 문법을 사용하면 보조 인덱스가 자동으로 생성되었다.
그 외에 직접 인덱스를 생성하려면 CREATE INDEX 문을 사용해야 한다. 인덱스를 생성하는 문법은 다음과 같다.

실제로 사용하는 방법은 다음과 같다.

UNIQUE는 중복이 안 되는 고유 인덱스를 만드는 것인데 생략하면 중복이 허용된다. CREATE UNIQUE로 인덱스를 생성하려면 기존에 입력된 값들에 중복이 있으면 안 된다. 그리고 인덱스를 생성한 후에 입력되는 데이터와도 중복될 수 없으니 신중해야 한다.
예를 들어, 회원 이름을 UNIQUE로 지정하면 향후에는 같은 이름의 회원은 입력할 수 없게 된다. 회원 이름은 같을 수도 있으므로 이름과 같은 성격을 가진 열에는 UNIQUE로 지정하면 안 된다. 이와 달리 휴대폰 번호, 이메일 등은 사람마다 모두 다르기 때문에 UNIQUE로 지정해도 별 문제가 없다.
ASC 또는 DESC는 인덱스를 오름차순 또는 내림차순으로 만들어준다. 기본은 ASC로 만들어지며, DEXC로 만드는 경우는 거의 없다.
인덱스 제거 문법
CREATE INDEX로 생성한 인덱스는 DROP INDEX로 제거한다.

주의할 점은 기본 키, 고유 키로 자동 생성된 인덱스는 DROP INDEX로 제거하지 못한다는 것이다. ALTER TABLE 문으로 기본 키나 고유 키를 제거하면 자동으로 생성된 인덱스도 제거할 수 있다.

인덱스 생성과 제거 실습
인덱스 생성 및 제거 후에 내부적인 변화를 이해하는 것이 중요하다.
인덱스 생성 실습
먼저 데이터의 내용을 확인해 본다.

이전에 실습할 때 데이터의 일부를 잘라서 사용했으므로 먼저 market_db를 모두 실행시킨 다음에 이 코드를 실행한다.
SHOW INDEX 문으로 member에 어떤 인덱스가 설정되어 있는지 확인해 볼 것이다. Key_name이 PRIMARY이면 클러스터형 인덱스를 의미한다.

현재 member에는 mem_id 열에 클러스터형 인덱스 1개만 설정되어 있다.
이번에는 인덱스의 크기를 확인해 본다. SHOW TABLES STATUS 문을 사용한다.

LIKE 뒤에 'member'는 member라는 글자가 들어간 테이블의 정보를 본다는 의미이다.
이미 클라스터형 인덱스가 있으므로 이 테이블에는 더 이상 클러스터형 인덱스를 생성할 수 없다. 주소(addr)에 중복을 허용하는 단순 보조 인덱스를 생성하겠다. 인덱스 이름을 idx_member_addr로 지정했다.

주의할 점은 Non_unique가 1로 설정되어 있으므로 고유 보조 인덱스가 아니라는 것이다. 즉, 중복된 데이터를 허용한다.
클러스트형 인덱스와 보조 인덱스 동시 사용

이번에는 보조 인덱스가 추가되었으므로 전체 인덱스의 크기를 다시 확인해 보겠다.

index_length 부분이 보조 인덱스의 크기인데 이상하게도 0으로 나왔다. 생성한 인덱스를 실제로 적용하려면 ANALYZE TABLE 문으로 먼저 테이블을 분석/처리해줘야 한다.

인덱스의 크기가 제대로 표시되었다.
이번에는 인원수에 중복을 허용하지 않는 고유 보조 인덱스를 생성해 보겠다.

블랙핑크, 마마무, 레드벨벳의 인원수가 4이기에 미리 중복된 값이 있다. 따라서 인원수 열에는 고유 보조 인덱스를 생성할 수 없다.
회원 이름으로 고유 보조 인덱스를 생성해 본다.

Non_uinque가 0이라는 것은 중복을 허용하지 않는다는 의미로, 고유보조 인덱스가 잘 생성된 것이다. 이번에는 마마무와 이름이 같은 태국의 가수 그룹이 회원가입을 하려고 한다. 회원 아이디인 기본 키만 다르면 되므로 MOO로 지정한다.

오류가 발생했다. 이것은 조금 전에 생성한 고유 고조 인덱스로 인해 중복된 값을 입력할 수 없기 때문이다. 이럴 때는 업무상 절대로 중복이 되지 않는 열에만 UNIQUE 옵션을 사용해서 인덱스를 생성해야 한다.
인덱스 활용 실습
지금까지 만든 인덱스가 어느 열에 있는지 확인해 보겠다.

회원 아이디, 이름, 주소 열에 인덱스가 생성되어 있다.
이번에는 전체를 조회해 보겠다.
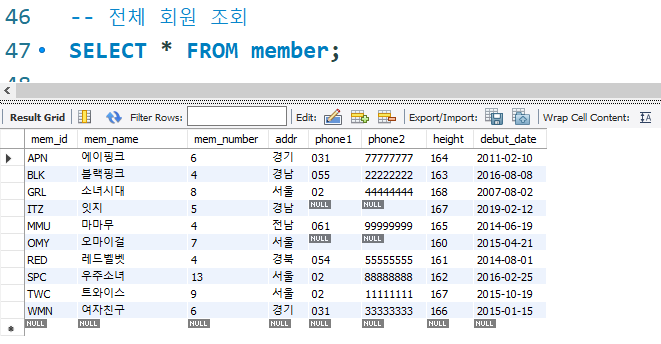
인덱스를 사용했는지 여부는 Execution Plan 창을 확인하면 된다.

전체 테이블 검색이 확인된다. 책과 비교하면 첫 페이지부터 끝 페이지까지 넘겨본 것이다.
이번에는 인덱스가 있는 열을 조회해 보겠다.


열 이름이 SELECT 다음에 나와도 인덱스를 사용하지 않았다. 이번에는 인덱스가 생성된 mem_name 값이 '에어핑크'인 행을 조회해 본다.


Sigle Row라고 되어 있는데 이 용어는 인덱스를 사용해서 결과를 얻었다는 의미이다. WHERE 절에 열 이름이 들어있어야 인덱스를 사용한다.
이번에는 숫자의 범위로 조회해 보겠다.



숫자의 범위로 조회하는 것도 인덱스를 사용한다.
인덱스를 사용하지 않을 때
인덱스가 있고 WHERE 절에 열 이름이 나와도 인덱스를 사용하지 않는 경우가 있다. 인원수가 1명 이상인 회원을 조회할 것이다.


7명 이상일 때는 인덱스를 사용했는데, 1명 이상으로 하니 전체 테이블 검색을 했다. 인덱스가 있더라도 MySQL이 인덱스 검색보다는 전체 테이블 검색이 낫겠다고 판단했기 때문이다. 이 경우에는 대부분의 행을 가져와야 하므로 인덱스를 왔다 갔다 하는 것보다는 테이블을 차례대로 읽는 것이 효율적이다.
인원수의 2배를 하면 14명 이상이 되는 회원의 이름과 인원수를 검색해 보자.


인덱스 검색을 기대했는데 전체 테이블 검색을 했다. WHERE 문에서 열에 연산이 가해지면 인덱스를 사용하지 않는다. 이 경우에는 다음과 같이 수정하면 된다.


이번에는 인덱스를 사용했다.
인덱스 제거 실습
지금까지 사용한 인덱스를 제거하겠다. 먼저 인덱스의 이름을 확인한다.

클러스터형 인덱스와 보조 인덱스가 섞여 있을 때는 보조 인덱스를 먼저 제거하는 것이 좋다. 보조 인덱스는 어떤 것을 먼저 제거해도 상관없다.

클러스터형 인덱스를 제거할 때 오류가 발생했다. 이유는 member의 mem_id 열을 buy가 참조하고 있기 때문이다. 그러므로 기본 키를 제거하기 전에 왜래 키 관계를 제거해야 한다.
테이블에는 여러 개의 외래 키가 있을 수 있다. 그래서 먼저 외래 키의 이름을 알아내야 한다. information_schema 데이터베이스의 referential_constraints 테이블을 조회하면 외래 키의 이름을 알 수 있다.

information_schema 데이터베이스의 referential_constraints 테이블은 MySQL 안에 원래 포함되어 있는 시스템 데이터베이스와 테이블이다. 여기에는 MySQL 전체 외래 키 정보가 들어있다.
이제 외래 키 이름을 알았으니 외래 키를 먼저 제거하고 기본 키를 제거하면 된다.

인덱스를 제거한다고 데이터의 내용이 바뀌는 것은 아니다.
인덱스를 효과적으로 사용하는 방법
인덱스를 효과적으로 사용하는 방법에 대해 정리해 본다.
1. 인덱스는 열 단위에 생성된다.
하나의 열에 하나의 인덱스를 생성할 수 있다.
2. WHERE 절에서 사용되는 열에 인덱스를 만들어야 한다.
SELECT 문을 사용할 때, WHERE 절의 조건에 해당 열이 나와야 인덱스를 사용한다. market_db의 member를 사용하는 SQL은 다음과 같다.

WHERE 절에 있는 인덱스만을 사용한다. 그러므로 mem_name 열 외에 다른 열에 인덱스를 만드는 것은 낭비가 된다.
3. WHERE 절에 사용되더라도 자주 사용해야 가치가 있다.
인덱스로 인해 성능이 오히려 나빠지게 된다. 차라리 인덱스 없이 SELECT를 하는 것이 더 낫다.
4. 데이터의 중복이 높은 열은 인덱스를 만들어도 별 효과가 없다.
열에 들어갈 데이터의 종류가 몇 가지 되지 않으면 인덱스가 큰 효과를 내지 못한다.
5. 클러스터형 인덱스는 테이블당 하나만 생성할 수 있다.
클러스터형 인덱스는 데이터 페이지를 읽는 수가 보조 인덱스보다 적기 때문에 성능이 더 우수하다. 그러므로 하나밖에 지정하지 못하는 클러스터형 인덱스는 조회할 때 가장 많이 사용하는 열에 지정하는 것이 효과적이다.
6. 사용하지 않는 인덱스는 제거한다.
그러면 공간을 확보할 뿐 아니라 데이터 입력 시 발생되는 부하도 많이 줄일 수 있다.
단원 마무리하기


3번은 3번이 아니라 2번이 답이다. 중복된 값이 있으면 CREATE UNIQUE INDEX 문에서 오류가 발생한다.
학습을 마치고
인덱스의 마지막 절은 정말 지루하고 재미는 없었다. 그래도 공부를 끝까지 계속하며 2시간에 걸쳐 다 마쳤다. 중간에 15분 정도 낮잠을 자기도 했는데 자고 나니 머리도 더 맑아지고 공부도 더 잘 되었다.
이것으로 3일 동안의 SQL 책 학습을 마친다. 마지막 두 Chapter는 다른 학습도구로 공부를 진행한 후에 해볼 것이다. 3일 동안 SQL 공부하느라 수고가 많았다. 이제 MySQL도 잘 다룰 수 있게 되었고 이 책을 통해 얻은 것들이 정말 많다.
점심을 먹고 쉬었다가 엘리스로 SQL 심화 학습을 시작해 볼 것이다.
'알고리즘 및 자료 관리 > SQL' 카테고리의 다른 글
| 집합 연산자와 계층형 질의 2 - 집합연산자 개념 1 : UNION/ UNION ALL 1 <이론 및 실습 문제 풀기> (0) | 2024.10.22 |
|---|---|
| 집합 연산자과 계층형 질의 1 - STANDARD SQL (0) | 2024.10.22 |
| 인덱스 2 - 인덱스의 내부 작동 (0) | 2024.10.22 |
| 인덱스 1 - 인덱스의 개념을 파악하자 (0) | 2024.10.22 |
| 테이블과 뷰 4 - 가상의 테이블 <뷰> (0) | 2024.10.22 |



