
- 분류 전체보기 (1618)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- JDBC
- 자바 실습
- 데이터베이스
- 컴퓨터구조
- c언어
- 정보처리기사실기
- 자바스크립트심화
- 머신러닝
- 자바
- 컴퓨터비전
- 상속
- 혼공머신
- JSP/Servlet
- 오블완
- SQL
- 자바스크립트
- 정보처리기사필기
- CSS
- 연습문제
- 순환신경망
- 중학수학
- JSP
- rnn
- 중학1-1
- 파이썬
- 데이터분석
- 개발일기
- 딥러닝
- 디버깅
- html/css
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
인덱스 2 - 인덱스의 내부 작동 본문
운동을 마치고 간단한 아침도 먹고 이제 아침 공부를 시작해 본다. 아침에는 4시간 동안 인덱스 단원을 모두 마치고 오늘 오후부터는 엘리스로 SQL 심화 공부를 할 예정이다. 1주 차까지는 마칠 수 있을 것 같다. 저녁에는 2주 차를 2\3 이상 마치고, 내일은 4주 차까지 모두 학습을 마쳐야겠다. 그리고 다시 SQL 책으로 돌아와서 스토어드 프로시저에 대해서 공부하면 거의 모든 과정이 끝난다.
파이썬으로 연결하는 건 나중에 해도 될 것 같아 7장까지만 공부할 것이다. 그럼 이제 오늘의 아침 공부를 본격적으로 시작해볼 것이다.
인덱스를 만들고 사용하는 방법은 어렵지 않다. 하지만 인덱스의 작동 과정을 제대로 이해하지 못한 상태에서 사용하면 오히려 문제가 생길 수 있다.
시작하기 전에
틀러스터형 인덱스와 보조 인덱스는 모두 내부적으로 균형 트리 형태로 만들어진다. 균형 트리는 '자료 구조'에 나오는 범용적으로 사용되는 데이터 구조이다.
나무를 거꾸로 표현한 자료 구조로, 트리에서 제일 상단의 뿌리를 루트, 줄기를 중간, 끝에 달린 잎을 리프라고 부른다.

인덱스의 내부 작동 원리
인덱스의 내부 작동 원리를 이해하면, 인덱스를 사용해야 할 경우와 사용하지 말아야 할 경우를 선택할 때 도움이 된다. 인덱스가 늘 좋은 것은 아니므로 정확히 판단하는 것이 중요하다.
균형 트리의 개념
균형 트리 구조에서 데이터가 저장되는 공간을 노드라고 한다. 다음 그림에서는 노드를 4개로 표현했다. 루트 노드는 노드의 가장 상위 노드를 말한다. 모든 출발은 루트 노드에서 시작된다. 리프 노드는 제일 마지막에 존재하는 노드를 말한다. 루트 노드와 리프 노드의 중간에 끼인 노드들은 중간 노드라 부른다.

노드라는 용어는 개념적인 설명에서 주로 나오는 용어이며, MySQL에서는 페이지라고 부른다. 페이지는 최소한의 저장 단위로, 16 Kbyte 크기를 갖는다. 예를 들어 데이터 1건만 입력해도 1개 페이지가 필요하다.
균형 트리는 데이터를 검색할 때(SELECT 구문을 사용) 아주 뛰어난 성능을 발휘한다. 만약 다음 그림에서 MMM이라는 데이터를 검색한다고 생각해 보자. 모두 리프 페이지만 있으므로 MMM을 찾는 방법은 처음부터 검색하는 방법밖에 없다. AA부터 MMM까지 8건의 데이터를 검색해야 그 결과를 알 수 있다.

이번에는 균형 트리에서 검색해보겠다. 균형 트리는 무조건 루트 페이지부터 검색한다. 루트 페이지에서 AA, FFF, LLL 3개와 리프 페이지에서 LLL, MMM 2개 합쳐서 5건의 데이터를 검색해서 원하는 결과를 찾았으며 페이지 2개를 읽었다.
위에서 균형 트리가 아닌 구조에서는 3페이지를 읽었지만, 균형 트리에서는 2페이지만 읽어서 결과를 얻을 수 있다.

실무에서 사용되는 훨씬 많은 양의 데이터는 균형 트리 구성 여부에 따라 읽어야 하는 페이지 수의 차이가 상당히 크다.
균형 트리의 페이지 분할
인덱스는 균형 트리로 구성되어 있다. 즉, 인덱스를 만들면 SELECT의 속도를 향상할 수 있다. 2페이지를 읽어서 데이터를 찾는 것은 3페이지를 읽어서 데이터를 찾는 것보다 빠른 방법이다.
그런데 인덱스를 구성하면 데이터 변경 작업(INSERT, UPDATE, DELETE) 시 성능이 나빠진다. 특히 INSERT 작업이 일어날 때 더 느리게 입력될 수 있다. 이유는 페이지 분할이라는 작업이 발생하기 때문이다. 페이지 분할이란 새로운 페이지를 준비해서 데이터를 나누는 작업을 말한다. 페이지 분할이 일어나면 MySQL이 느려지고, 너무 자주 일어나면 성능에 큰 영향을 준다.
앞에서 본 그림에 III 데이터가 새로 INSERT 되었다고 가정해보겠다. 균형 트리는 다음과 갈이 변경될 것이다.

두번째 리프 페이지에는 빈 공간이 있어서 JJJ가 아래로 한 칸 이동하고 III가 그 자리에 삽입된다. 이번에는 GGG를 입력해 보겠다. 그런데 두 번째 리프 페이지에는 더 이상 빈 공간이 없다. 이럴 때 페이지 분할 작업이 일어난다.
데이터를 1개 밖에 추가하지 않았는데 많은 변화가 생겼다. 우선 새 페이지를 확보한 후 페이지 분할이 1회 일어났고, 루트 페이지에도 새로 등록된 페이지의 제일 위에 있는 데이터 III가 등록되었다.

이번에는 PPP와 QQQ 2개를 연속으로 입력해보겠다.

①번에서 PPP를 입력하면 네 번째 리프 페이지에 빈칸이 있으므로 제일 마지막에 추가된다. QQQ를 입력하려고 보니 네 번째 리프 페이지에는 빈칸이 없으므로 ②번처럼 페이지 분할 작업이 일어난다.
페이지 분할 후에 추가된 다섯 번째 리프 페이지를 루프 페이지에 등록하려고 하니, 루트 페이지도 이미 꽉 차서 더 이상 등록할 곳이 없다 그래서 ③과 같이 루트 페이지도 다시 페이지 분할을 해야 한다. 그리고 원래 루트 페이지가 있던 곳은 2개의 페이지가 되어 더 이상 루트 페이지가 아니라 중간 페이지가 된다.
마지막으로 ④의 새 페이지를 준비해서 중간 노드를 가리키는 새로운 루트 페이지로 구성된다. 결국 QQQ 하나를 입력하기 위해서 3개의 새로운 페이지가 할당되고 2회의 페이지 분할이 되었다. 데이터 하나를 입력하기 위해 너무 많은 일이 있어난 것이다.
이 예를 통해 인덱스를 구성하면 왜 데이터 변경 작업이 느려지는지 확인할 수 있었다.
인덱스의 구조
인덱스의 구조를 통해 인덱스를 생성하면 왜 데이터가 정렬되는지, 어떤 인덱스가 더 효율적인지 살펴보겠다.
클러스터형 인덱스 구성하기
이번에는 클러스트형 인덱스와 보조 인덱스의 구조는 어떻게 다른지 살펴보겠다. 우선 인덱스 없이 테이블을 생성하고 다음과 같이 데이터를 입력한다.
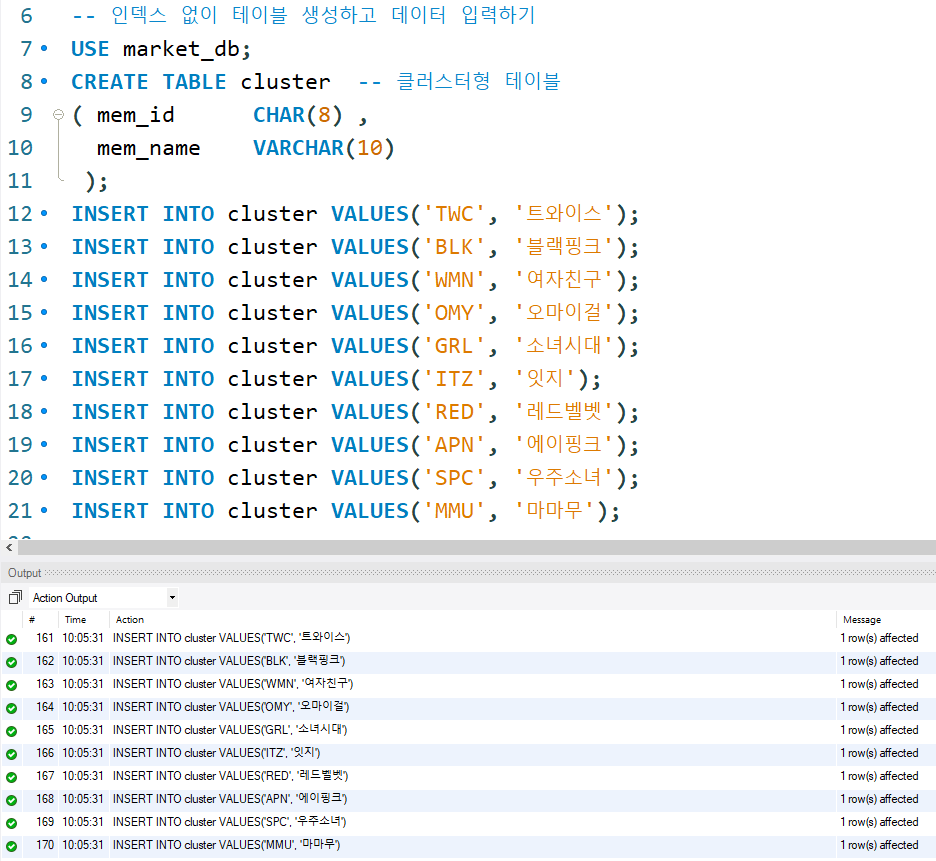
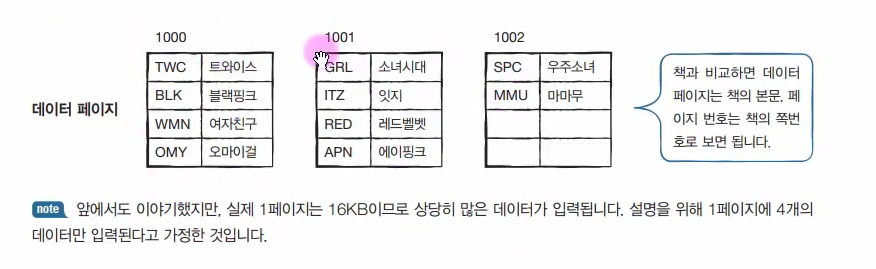
한 페이지에 4개의 행이 입력된다고 가정해 보겠다. 이 데이터는 다음과 같이 구성되어 있을 것이다.

아직은 인덱스가 없는 상태로, 각 페이지 위에 써진 숫자는 페이지 번호를 임의로 부여했다.
정렬된 순서를 확인해 보자.

입력한 순서와 동일한 순서로 보인다.
이제 테이블의 mem_id에 클러스터형 인덱스를 구성해 보겠다. mem_id를 Primary Key로 지정하면 클러스터형 인덱스로 구성된다.

mem_id를 기준으로 오름차순 정렬되었다. mem_id 열을 PK로 지정했으니 클러스터형 인덱스가 생성되어서 그렇다.
실제 데이터는 다음과 같이 데이터 페이지가 정렬되고 균형 트리 형태의 인덱스가 형성된다. 먼저 클러스터형 인덱스를 구성하기 위해 행 데이터를 지정한 열로 정렬한다. 아래쪽의 데이터 페이지를 보면 회원 아이디로 정렬된 것이 확인된다. 그리고 각 페이지의 인덱스로 지정된 열의 첫 번째 값을 가지고 루트 페이지를 만든다.

보조 인덱스 구성하기
이번에는 동일한 데이터로 보조 인덱스를 만들어보겠다.

순서대로 데이터가 입력되었다. 앞서 고유 키 제약조건은 보조 인덱스를 생성한 다는 것을 확인했다. mem_id 열에 UNIQUE를 지정하고 데이터를 확인해 보겠다.

보조 인덱스가 생성되었는데도 입력한 것과 순서가 동일하다. 내부적으로는 다음과 같이 구성된다. 다음 그림의 아래쪽을 보면 보조 인덱스는 데이터 페이지를 건드리지 않았다. 위쪽을 보면 별도의 장소에 인덱스 페이지를 생성했다.
책의 뒷부분 등 별도의 공간에 찾아보기가 만들어진 것처럼 보조 인덱스가 별도의 공간에 만들어졌다.

우선 인덱스 페이지의 리프 페이지에 인덱스로 구성한 열(mem_id)을 정렬한다. 그리고 실제 데이터가 있는 위치를 준비한다. 일반 책의 찾아보기를 보면 각 단어 옆에 페이지 번호가 써 있는 것과 동일하다. 데이터의 위치는 페이지 번호 +#위치로 기록되어 있다. APN을 예로 들면, 1001번 페이지의 네 번째(#4)에 데이터가 있다고 기록된다.
인덱스에서 데이터 검색하기
이제 데이터를 검색(SELECT 문)해보겠다. 먼저 클러스터형 인덱스에서 검색을 하겠다. 만약 SPC인 회원의 이름을 검색한다면 몇 개의 페이지를 읽어야 알 수 있을까?
다음 그림의 ①번에서 일단 루트 페이지(100번)를 읽어야 한다. 그다음 SPC는 MMU와 TWC 사이에 있으므로 루트 페이지의 MMU가 가리키는 리프 페이지의 1001번으로 이동한다.
②번처럼 리프 페이지(데이터 페이지, 1001번)를 읽으니 ③번처럼 네 번째 찾고자 하는 SPC가 있고 이름이 '우주소녀'라는 것을 알아냈다.
클러스터형 인덱스에서는 SPC 회원의 이름을 알아내기 위해 100번 루트 페이지와 1001 리프 페이지를 읽었다. 결국 총 2개 페이지를 읽어서 SPC의 이름을 알아낸 것이다.

이번에는 보조 인덱스에서 SPC 회원의 이름을 걱샘해보겠다. SPC를 검색할 때 인덱스 페이지의 루트 페이지(10번), 리프 페이지(200번)를 읽는다. 그리고 데이터 페이지(1002번)를 읽어서 SPC의 이름이 '우주소녀'인 것을 알아냈다. 결국 총 3개 페이지를 읽어서 SPC의 이름을 알아낸 것이다.

두 인덱스 모두 검색이 빠르기는 하지만 클러스터형 인덱스가 조금 더 빠르다.
단원 마무리하기


4번은 맞을 수 있었는데 틀렸다. 1번은 맞는 답이고 3번에서 맞는지 틀린 지 헷갈렸다. 보조인덱스를 생성하면 정렬되지 않는다.
학습을 마치고
오늘은 공부가 생각했던 것보다 일찍 끝났다. 역시 공부든 일이든 주위 환경이 중요하다는 걸 확실히 느꼈다. 선생님의 배려로 앞으로 난 집에서 온라인으로 공부할 수 있게 되었다. 하루종일 내가 하고 싶을 때 언제든지 할 수 있다는 것이 홈스클링의 가장 큰 매력이다.
앞으로 35일 정도 남은 인사교 기간 동안 정말 열심히 공부해서 내 실력을 지금보다 배 이상 끌어올릴 생각이다.
'알고리즘 및 자료 관리 > SQL' 카테고리의 다른 글
| 집합 연산자과 계층형 질의 1 - STANDARD SQL (0) | 2024.10.22 |
|---|---|
| 인덱스 3 - 인덱스의 실제 사용 (0) | 2024.10.22 |
| 인덱스 1 - 인덱스의 개념을 파악하자 (0) | 2024.10.22 |
| 테이블과 뷰 4 - 가상의 테이블 <뷰> (0) | 2024.10.22 |
| 테이블과 뷰 3 - 제약조건으로 테이블을 견고하게 2 : 기타 제약조건 (0) | 2024.10.21 |



