
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 자바 실습
- 영어공부
- CSS
- 텍스트마이닝
- 데이터입출력구현
- 정수와유리수
- 정보처리기사필기
- 파이썬
- 데이터베이스
- C++
- numpy/pandas
- 컴퓨터비전
- 중학수학
- 중학1-1
- 딥러닝
- 자바
- 파이썬라이브러리
- 코딩테스트
- 데이터분석
- CNN
- JSP/Servlet
- pandas
- 연습문제
- 정보처리기사실기
- html/css
- SQL
- 머신러닝
- 혼공머신
- 컴퓨터구조
- 운영체제
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
딥러닝을 시작합니다 6 - 신경망 모델 훈련 2 : 모델 저장과 복원 및 콜백 본문
이어서 신경망 모델 훈련을 학습해 볼 것이다.
모델 저장과 복원
에포크 횟수를 10으로 다시 지정하고 모델을 훈련하겠다. 나중에 한빛 마켓의 패션 럭키백 런칭에 사용하려면 이 모델을 저장해야 한다.


케라스 모델은 훈련된 모델의 파라미터를 저장하는 간편한 메서드를 제공한다.

책과 코드를 조금 다르게 작성했다. 가중치가 잘 전달이 되지 않고 오류가 떠서 weights를 써주었다.
두 가지 실험을 해보겠다. 첫 번째는 훈련을 하지 않은 새로운 모델을 만들고 model-weights.h5 파일에서 훈련된 모델 파라미터를 읽어서 사용한다. 두 번째는 아예 이 파일에서 새로운 모델을 만들어 바로 사용한다.
먼저 첫번째 실험부터 시작한다.

이 모델의 정확도를 확인해 보겠다. 케라스에서 예측을 수행하는 predict() 메서드는 사이킷런과 달리 샘플마다 10개의 클래스에 대한 곽률을 반환한다. 패션 MNIST 데이터셋에서 덜어낸 검증 세트의 샘플 개수는 12000개이기 때문에 predict() 메서드는 (12000, 10) 크기의 배열을 반환한다.

따라서 조금 번거롭지만 10개 확률 중에 가장 큰 값의 인덱스를 골라 타깃 레이블과 비교하여 정확도를 계산해 보겠다.

모델의 predict() 메서드의 결과에서 가장 큰 값을 고르기 위해 넘파이 argmax() 함수를 사용했다. 이 함수는 배열에서 가장 큰 값의 인덱스를 반환한다. argmax() 함수의 axis = -1은 배열의 마지막 차원을 따라 최댓값을 고른다. 검층 세트는 2차원 배열이기 때문에 마지막 차원은 1이 된다.

이번에는 모델 전체를 파일에서 읽은 다음 검증 세트의 정확도를 출력해 보겠다.

같은 모델을 저장하고 다시 불러들였기 때문에 위와 동일한 정확도를 얻었다. 이 과정을 돌이켜 보면 20번의 에포크 동안 모델을 훈련하여 검증 손실이 상승하는 지점을 확인했다. 그다음 모델을 과대적합되지 않는 에포크만큼 다시 훈련했다. 모델을 두 번씩 훈련하지 않고 한 번에 끝낼 수는 없을까?
콜백
콜백은 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체로 keras.callbacks 패키지 아래에 있는 클래스들이다. fit() 메서드의 callbacks 매개변수에 리스트로 전달하여 사용한다. 여기에 사용할 콜백은 기본적으로 에포크마다 모델을 저장한다.


오류가 떠서 파일 이름 확장자를 keras로 바꾸어주었더니 이제 잘 된다. ModelCheckpoint 클래스 객체 checkpoint_cb를 만든 후 fit() 메서드의 callbacks 매개변수에 리스트로 감싸서 전달한다. 모델을 훈련한 후에 best-model.keras에 최상의 검증 점수를 낸 모델이 저장된다. 이제 이 모델을 load_model() 함수로 읽어서 예측을 수행해 보겠다.

훨씬 편하다. ModelCheckpoint 콜백이 가장 낮은 검증 손실 모델을 자동으로 저장해 주었다. 하지만 여전히 20번의 에포크 동안 훈련을 한다. 사실 검증 점수가 상승하기 시작하면 그 이후에는 과대적합이 더 커지기 때문에 훈련을 계속할 필요가 없다. 이때 훈련을 중지하면 컴퓨터 자원과 시간을 아낄 수 있다. 이렇게 과대적합이 시작되기 전에 훈련을 미리 중지하는 것을 조기 종료라고 부르며, 딥러닝 분야에서 널리 사용한다.
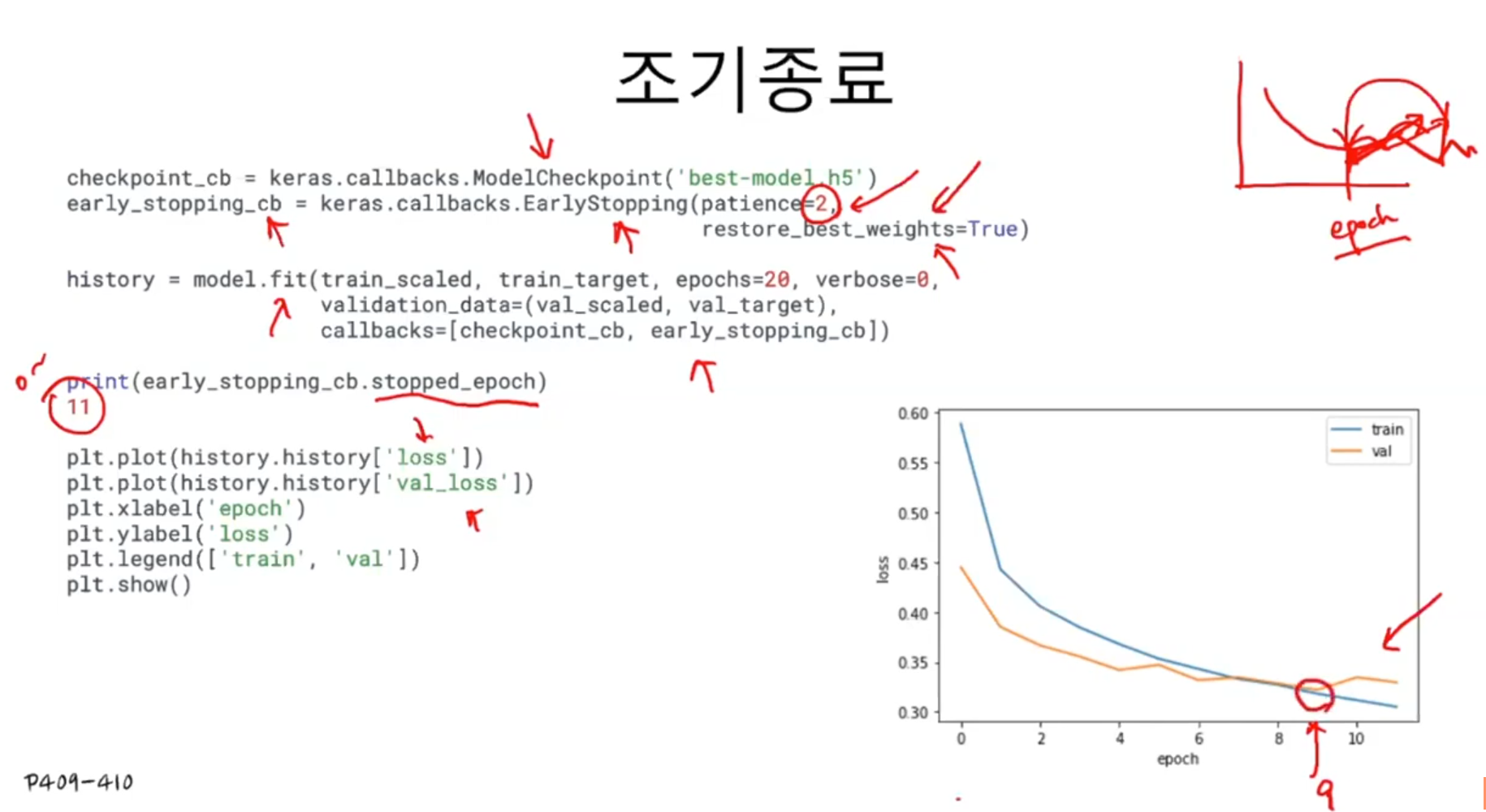
조기 종료는 에포크 횟수를 제한하는 역할이지만 모델이 과대적합되는 것을 막아주기 때문에 규제 방법 중 하나로 생각할 수도 있다. 케라스에는 조기 종류를 위한 EarlyStoppoing 콜백을 제공한다. 이 콜백의 parience 매개변수는 검증 점수가 향상되지 않더라도 참을 에포크 횟수로 지정한다.
EarlyStopping 콜백을 ModelCheckpoint 콜백과 함께 사용하면 가장 낮은 검증 손실의 모델을 파일에 저장하고 검증 손실이 다시 상승할 때 훈련을 중지할 수 있다. 또한 훈련을 중지한 다음 현재 모델의 파라미터를 최상의 파라미터로 되돌린다.
이 두 콜백을 함께 사용해 보겠다.

EarlyStopping 콜백을 추가한 것 외에는 이전과 동일하다. fit() 메서드의 callbacks 매개변수에 2개의 콜백을 리스트로 전달한 것을 눈여겨보라. 훈련을 마치고 나면 몇 번째 에포크에서 훈련이 중지되었는지 early_stoping_cb 객체의 stopped_epoch 속성에서 확인할 수 있다.
patience를 2로 지정했으므로 최상의 모델은 열한 번째 에포크일 것이다.
이제 훈련 센실과 검증 손실을 출력해서 확인해 보겠다.

열한 번째 에포크에서 가장 낮은 손실을 기록했고 열세 번째 에포크에서 훈련이 중지되었다. 조기 종료 기법을 사용하면 안심하고 에포크 횟수를 크게 지정해도 괜찮다.
마지막으로 조기 종료로 얻은 모델을 사용해 검증 세트에 대한 성능을 확인해 보겠다.

단원 마무리하기



다 틀릴 줄 알았는데 그래도 두 문제나 맞혔다. 2번에서 Dropout 클래스에는 이전 충의 출력을 0으로 만들 비율을 지정한다. 출력의 70%만 사용하려면 30%를 드롭아웃한다.
4번에서 검증 손실을 지정하려면 mointor 매개변수를 'val_loss'로 설정한다. 이 값이 monitore 매개변수의 기본값이다.
학습을 마치고
사실 어제 저녁식사 전에 다 마치려고 했던 건데 너무 배가 고파 저녁 먹고 나머지를 마무리하려고 했었다. 하지만 식사 후에는 계속 좋아하는 방송과 드라마를 보며 놀게 되었고 다음날에도 새벽에 평소보다 2시간이나 늦게 일어나고 말았다.
그래도 시작한 공부를 끝낼 수 있어서 정말 감사했다.
이 단원은 얼마나 지루했는지 모른다. 사실 딥러닝은 재미있는 분야는 아니다. 그리고 계획을 조금 변경하기로 했다. 원래는 텐서플로 책으로 수준 높은 딥러닝 공부를 하려고 했으나 나중에 정말 하고 싶을 때 하는 걸로 바꾸었다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 케라스 2 - 딥러닝 준비 2 : 딥러닝 프로세스 (0) | 2024.10.26 |
|---|---|
| 케라스 1 - 딥러닝 준비 1 : 주요 용어 정리 (0) | 2024.10.26 |
| 딥러닝을 시작합니다 5 - 신경망 모델 훈련 1 : 손실 곡선과 검증 손실 그리고 드롭아웃에 대하여 (0) | 2024.10.25 |
| 딥러닝을 시작합니다 4 - 심층 신경망 2 : 렐루 함수와 옵티마이저 (0) | 2024.10.25 |
| 딥러닝을 시작합니다 3 - 심층 신경망 1 : 심층 신경망 만들기 및 층을 추가하는 다른 방법 (0) | 2024.10.25 |



