
- 분류 전체보기 (1690)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 중학수학
- CSS
- 디버깅
- html/css
- 정보처리기사실기
- JSP
- 정보처리기사필기
- ChatGPT
- 데이터베이스
- 상속
- 혼공머신
- 머신러닝
- 연습문제
- 컴퓨터비전
- 자바
- c언어
- 컴퓨터구조
- 자바 실습
- 자바스크립트심화
- JDBC
- 딥러닝
- 파이썬
- SQL
- JSP/Servlet
- 개발일기
- 순환신경망
- rnn
- 중학1-1
- 데이터분석
- 자바스크립트
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
딥러닝을 시작합니다 5 - 신경망 모델 훈련 1 : 손실 곡선과 검증 손실 그리고 드롭아웃에 대하여 본문
오후에 다른 일정이 있어서 오후 공부를 늦게 시작해 본다. 저녁 먹기 전까지 2시간 동안 정말 열심히 공부해서 7장의 마지막 장 학습을 마쳐볼 생각이다. 그리고 오늘 저녁부터 내일 혹은 모레 새벽까지 지난번에 공부하다 말았던 파이썬 딥러닝 텐서플로 책으로(무척 어려움) 캐라스 학습을 진행하려고 한다.
그런 다음에 다음 주에는 다시 지금까지 진행했던 시각지능 관련 수업을 모두 듣고 학습일지를 써볼 생각이다. 수업과 함께 CNN, RNN 관련 내용을 책 두 권과 함께 병행할 것이다.
그리고 나면 컴퓨터 비전도 학습할 수 있는 실력이 될 것 같다. 난 영상 처리 기술을 제대로 익혀서 특정 대상을 위한 유용한 앱을 만들고 싶다. 그럼 이제 공부를 시작해 보자!
지난 시간 복습

시작하기 전에
지금까지 인공 신경망에 대해 배우고 텐서플로의 케라스 API를 사용해 직접 만들어보았다. 1개 이상의 층을 추가하여 심층 신경망을 구성하고 다양한 고급 옵티마이저를 적용하는 방법도 알아보았다.
이전에 배웠던 머신러닝 알고리즘과는 어떤 차이가 있을까? 일반적으로 사이킷런에서 제공하는 머신러닝 알고리즘들은 좋은 성능을 내기 위해 매개변수를 조정하고 훈련하는 과정을 반복한다. 이런 알고리즘들은 모델의 구조가 어느 정도고정되어 있다고 느낄 수 있다.
반면 딥러닝에서는 모델의 구조를 직접 만든다는 느낌이 훨씬 강하다. 층을 추가하고 층에 있는 뉴런의 개수와 활성화 함수를 결정하는 일이 그렇다. 그래서인지 프로그래머에게는 텐서플로, 케라스와 같은 딥러닝 라이브러리가 조금 더 친숙하게 느껴질 수 있다.
이번 절에서는 케라스 API를 사용해 모델을 훈련하는데 필요한 다양한 도구들을 알아보겠다.
손실 곡선
이전 절에서 fit() 메서드로 모델을 훈련하면 훈련 과정이 상세하게 출력되어 학인할 수 있었다. 여기에는 에포크 횟수, 손실, 정확도 등이 있었다. 그런데 이 출력의 마지막에 다음과 같은 메시지를 보았을 것이다.

노트북의 코드 셀은 print() 명령을 사용하지 않더라도 마지막 라인의 실행 결과를 자동으로 출현한다. 이 메시지는 fit() 메서드의 실행 결과를 출력한 것이다. 실은 케라스의 fit() 메서드는 History 클래스 객체를 반환한다. History 객체에는 훈련 과정에서 계산한 지표. 즉 손실과 정확도 값이 저장되어 있다. 이 값을 사용하면 그래프를 그릴 수 있을 것이다.
먼저 이전 절에서 사용했던 것 같이 패션 MNIST 데이터셋을 적재하고 훈련 세트와 검증 세트로 나눈다.

if 구문의 역할은 model_fn() 함수에 (a_layer 매개변수로) 케라스 층을 추가하면 은닉층 뒤에 또 하나의 층을 추가하는 것이다. 여기서는 a_layer 매개변수로 층을 추가하지 않고 단순하게 model_fn() 함수를 호출한다. 그리고 모델 구조를 출력하면 이전 절과 동일한 모델이라는 것을 확인할 수 있다.

이전 절과 동일하게 모델을 훈련하지만 fit() 메서드의 결과를 history 변수에 담아보겠다.


history 객체에는 훈련 측정값이 담겨 있는 history 딕셔너리가 들어있다. 이 딕셔너리에 어떤 값이 들어있는지 확인해 보겠다.

손실과 정확도가 포함되어 있다. 케라스는 기본적으로 에포크마다 손실을 계산한다. 정확도는 compile() 메서드에서 metrics 매개변수에 'accuracy'를 추가했기 때문에 history 속성에 포함되었다.
history 속성에 포함된 손실과 정확도는 에포크마다 계산한 값이 순서대로 나열된 단순한 리스트이다. 맷플롯립을 사용해 쉽게 그래프로 그릴 수 있다.

파이썬 리스트의 인덱스는 0부터 시작하므로 5개의 에포크가 0에서부터 4까지 x축에 표현된다. y축은 계산된 손실 값이다. 이번에는 정확도를 출력해 보겠다.

확실히 에포크마다 손실이 감소하고 정확도가 향상한다. 그렇다면 에포크를 늘려서 더 훈련하면 좋지 않을까? 이번에는 에포크 횟수를 20으로 늘려서 모델을 훈련하고 손실 그래프를 그려보겠다.



예상대로 손실이 잘 감소한다. 이전보다 더 나은 모델을 훈련한 것일까?
검증 손실
4장에서 확률적 경사 하강법을 사용했을 때 과대/과소적합과 에포크 사이의 관계를 알아보았다. 인공 신경망은 모두 일종의 경사 하강법을 사용하기 때문에 동일한 개념이 여기에도 적용된다 에포크에 따른 과대적합과 과소적합을 파악하려면 훈련 세트에 대한 점수뿐만 아니라 검증 세트에 대한 점수도 필요하다. 따라서 앞에서처럼 훈련 세트의 손실만 그려서는 안 된다. 여기서는 손실을 사용하여 과대/과소적합을 다루어보겠다.
다음과 같은 그래프를 예상해 볼 수 있다.
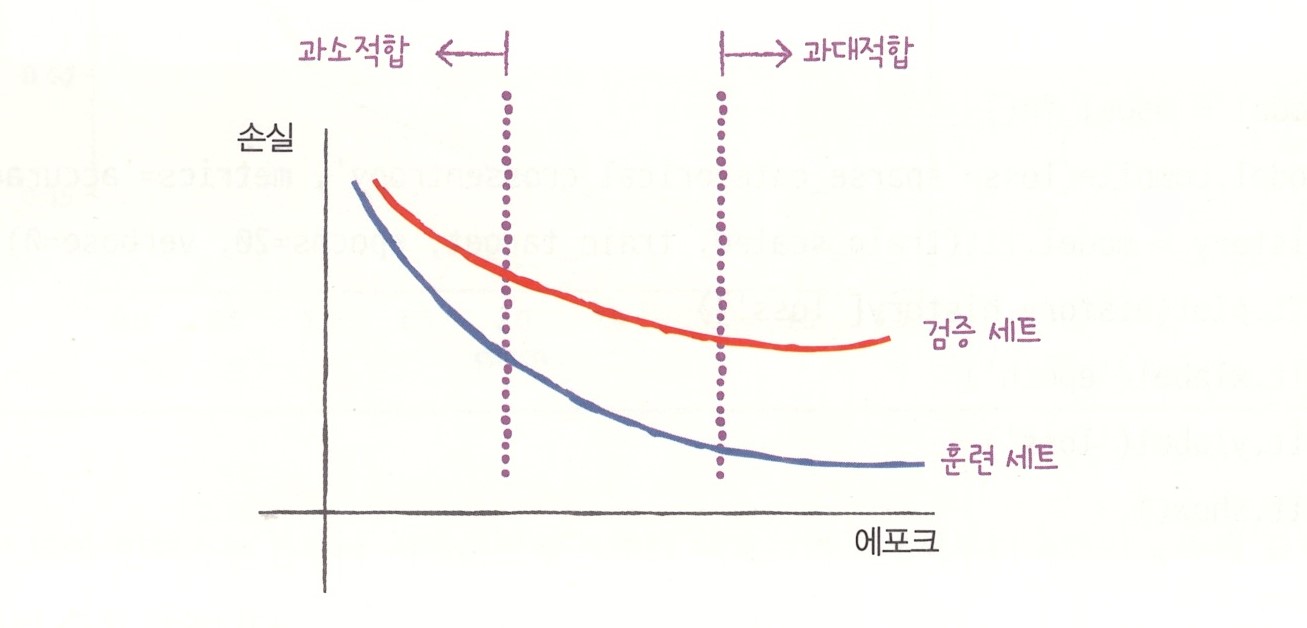
에포크마다 검증 손실을 계산하기 위해 케라스 모델의 fit9) 메서드에 검증 데이터를 전달할 수 있다. 다음처럼 validation_data 매개변수에 검증에 사용할 입력과 타깃값을 튜플로 만들어 전달한다.


과대/과소적합 문제를 조사하기 위해 훈련 손실과 검증 손실을 한 그래프에 그려서 비교해 보겠다.
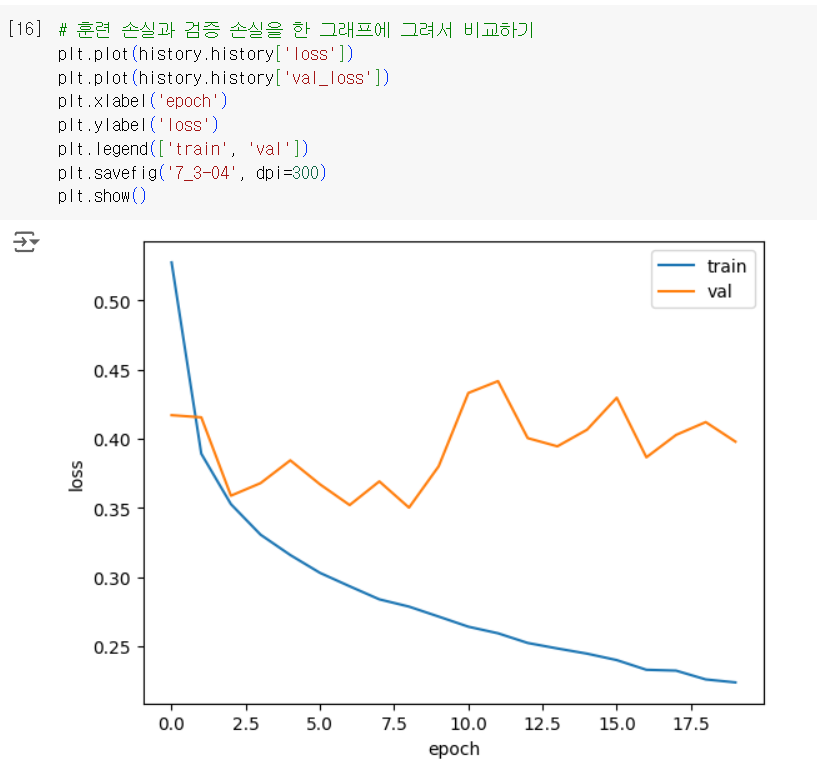
초기에 검증 손실이 감소하다가 다섯 번째 에포크만에 다시 상승하기 시작한다. 훈련 손실을 꾸준히 감소하기 때문에 전형적인 과대적합 모델이 만들어진다. 검증 손실이 상승하는 시점을 가능한 뒤로 늦추면 검증 세트에 대한 손실이 줄어들 뿐만 아니라 검증 세트에 대한 정확도도 증가할 것이다.
기본 RMSprop 옵티마이저는 많은 문제에서 잘 동작한다. 만약 이 옵티마이저 대신 다른 옵티마이저를 테스트해 본다면 Adam이 좋은 선택이다. Adam은 적응적 학습률을 사용하기 때문에 에포크가 진행되면서 학습률의 크기를 조정할 수 있다. Adam 옵티마이저를 적용해 보고 훈련 손실과 검증 손실을 다시 그려보겠다.


과대 적합이 훨씬 줄었다. 검증 손실 그래프에 여전히 요동이 남아있지만, 열 번째 에포크까지 전반적인 감소 추세가 이어지고 있다. 이는 Adam 옵티마이저가 이 데이터셋에 잘 맞는다는 것이다.
더 나은 손실 곡선을 얻으려면 학습률을 조정해서 다시 시도해 볼 수 있다. 이제 신경망에서 사용하는 대표적이 ㄴ규제 방법을 알아보겠다.
드롭아웃
드롭아웃은 딥러닝의 아버지로 불리는 제프리 힌턴이 소개했다. 이 방식은 다음 그림처럼 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서(뉴런의 출력을 0으로 만들어) 과대적합을 막는다.
어떤 샘플을 처리할 때는 은닉층의 두 번째 뉴런이 드롭아웃되어 h2 출력이 없다. 다른 샘플을 처리할 때는 은닉층의 첫 번째 뉴런이 드롭아웃되어 h1 출력이 없다. 뉴런은 랜덤하에 드롭아웃되고 얼마나 많은 뉴런을 드롭할지는 우리가 정해야 할 또 다른 하이퍼파라미터이다.

드롭아웃이 왜 과대적합을 막을까? 이전 층의 일부뉴런이 랜덤하게 꺼지면 특정 뉴런이 과대하게 의존하는 것을 줄일 수 있고 모든 입력에 대해 주의를 기울여야 한다. 일부 뉴런의 출력이 없을 수 있다는 것을 감안하면 이 신경망은 더 안정적인 예측을 만들 수 있을 것이다.
케라스에서는 드롭아웃을 keras.layers 패키지 아래 Dropout 클래스로 제공한다. 어떤 층의 뒤에 드롭아웃을 두어 이 층의 출력을 랜덤하게 0으로 만드는 것이다. 드롭아웃이 층처럼 사용되지만 훈련되는 모델 파라미터는 없다.
그럼 앞서 정의한 model_fn() 함수에 드롭아웃 객체를 전달하여 층을 추가해 보겠다. 여기에서는 30% 정도를 드롭아웃한다.


출력 결과에서 볼 수 있듯이 은닉층 뒤에 추가된 드롭아웃 층은 훈련되는 모델 파라미터가 없다. 또한 입력과 출력의 크기가 같다. 일부 뉴런의 출력을 0으로 만들지만 전체 출력 배열의 크기를 바꾸지 않는다.
훈련 손실과 검증 손실 그래프를 그려 비교해 보겠다.


과대적합이 획실히 줄었다. 열 번째 에포크 정도에서 검증 손실의 감 소가 멈추지만 크게 상승하지 않고 어느 정도 유지되고 있다. 이 모델은 20번의 에포크 동안 훈련을 했기 때문에 결국 다소 과대적합되어 있다. 과대적합 되지 않은 모델을 얻기 위해 에포크 횟수를 10으로 하고 다시 훈련해야겠다.
학습을 마치고
나머지 부분은 다음 포스트에서 이어서 학습해 볼 것이다. 무척 어려운 내용인데 그래도 학습을 잘하고 있다. 머신러닝도 그렇지만 특히 딥러닝 파트는 한번 보고 이해할 수는 없다. 몇 번 반복해서 하다 보면 어느새 능숙해질 때가 있을 것이다.
두 달 전까지만 해도 인공지능 관련 공부를 해볼 생각조차 하지 못했지만 지금은 약간의 흥미도 느끼고 필요성도 절감하고 있다. 앞으로의 시대는 인공지능을 모르고서는 개발을 제대로 할 수 없다고 생각한다. 그러니 AI는 모든 분야에 접목할 수 있으리라 확신한다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 케라스 1 - 딥러닝 준비 1 : 주요 용어 정리 (0) | 2024.10.26 |
|---|---|
| 딥러닝을 시작합니다 6 - 신경망 모델 훈련 2 : 모델 저장과 복원 및 콜백 (0) | 2024.10.26 |
| 딥러닝을 시작합니다 4 - 심층 신경망 2 : 렐루 함수와 옵티마이저 (0) | 2024.10.25 |
| 딥러닝을 시작합니다 3 - 심층 신경망 1 : 심층 신경망 만들기 및 층을 추가하는 다른 방법 (0) | 2024.10.25 |
| 딥러닝을 시작합니다 2 - 인공 신경망 2 : 인공 신경망으로 모델 만들기 (0) | 2024.10.25 |



