
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 연습문제
- 텍스트마이닝
- pandas
- 컴퓨터비전
- 중학1-1
- 파이썬
- 데이터입출력구현
- 정보처리기사실기
- CNN
- 자바
- 영어공부
- 중학수학
- 운영체제
- 혼공머신
- 정보처리기사필기
- 컴퓨터구조
- 파이썬라이브러리
- 정수와유리수
- html/css
- 딥러닝
- 자바 실습
- SQL
- 코딩테스트
- 데이터분석
- 데이터베이스
- numpy/pandas
- CSS
- C++
- 머신러닝
- JSP/Servlet
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
[Spiring반] 기말 시험 1 - 머신러닝 시험 및 문제 풀이 본문
아침에 AICON에 가기 위해 버스를 타고 가다가 담임선생님이 오늘 시험을 본다고 해서 다시 집으로 왔다. 그리고 지금 시험을 보는 중인데 나중에 어떤 문제였는지 알 수 있도록 시험을 푸는 모든 과정도 학습일지에 올려보기로 했다.
전에도 몇 가지 과목 시험을 봤었는데 그건 정리하지 않았더니 언제 다시 정리하게 될지 모르겠다. 뭐든 바로 하는 게 좋기도 하고, 시험도 하나의 공부의 일종이니 기록을 해본다.
머신러닝 문제
1번 문제
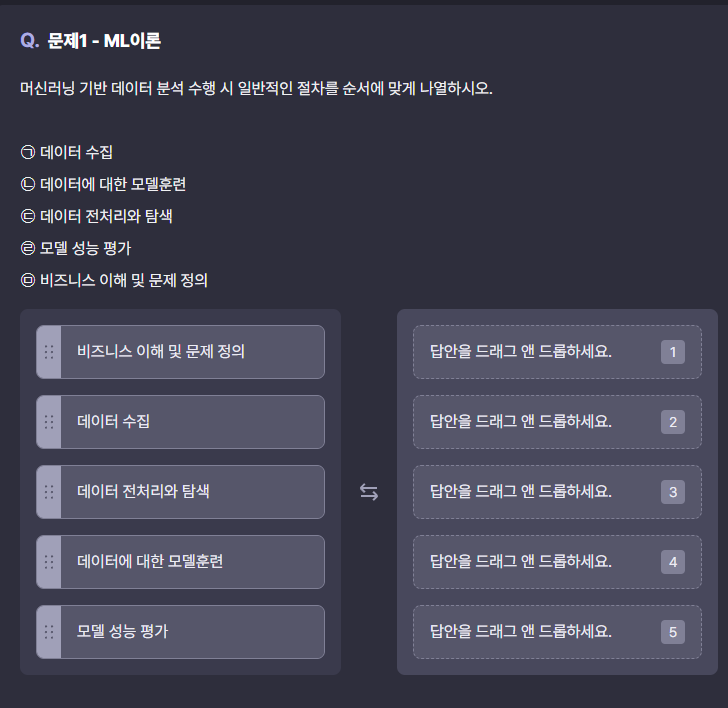
1번 문제를 풀다가 정리할 생각이 나서 이 문제의 순서는 거의 정답에 가깝다.

1번 문제는 별로 어렵지 않았다.
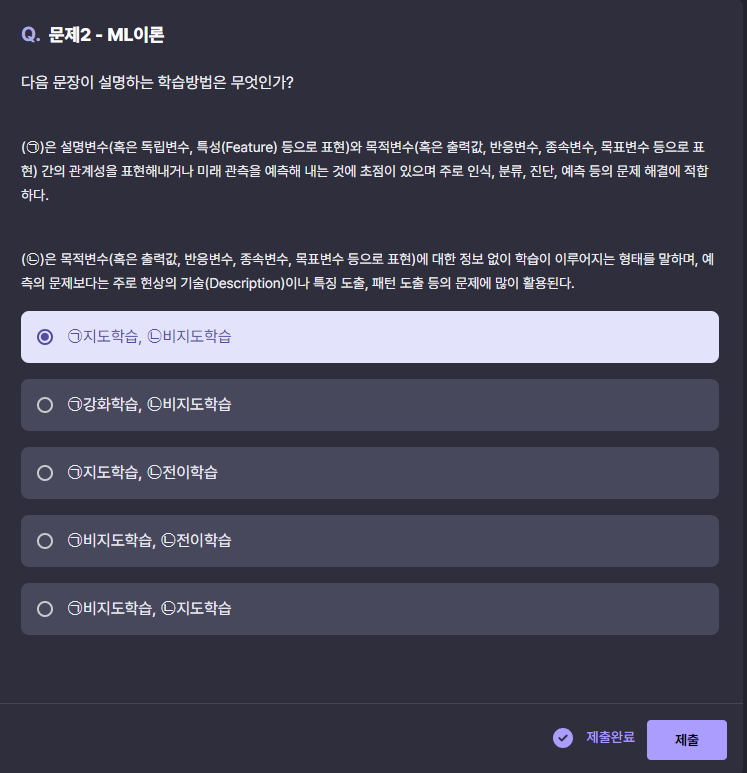
2번 문제

ㄱ은 예측을 하는 거니 지도학습, ㄴ은 정보 없이 특징을 도출하는 거니까 비지도학습 같다. 이 내용을 정리해 보면 다음과 같다.
지도학습 (Supervised Learning)
- 목적: 입력 데이터(설명변수)와 이에 대응하는 정답(목적변수 또는 레이블)이 주어진 상태에서 모델을 학습시켜, 새로운 입력 데이터에 대해 예측할 수 있도록 하는 것이다.
- 작동 방식: 정답(레이블)이 포함된 데이터를 사용해 모델을 훈련시킨다. 모델은 입력과 정답 사이의 관계를 학습하여, 새로운 데이터에 대해서도 예측을 할 수 있게 된다.
- 적용 예시:
- 분류(Classification): 이메일 스팸 필터링, 이미지 인식 (예: 고양이 vs 강아지 분류)
- 회귀(Regression): 주식 가격 예측, 주택 가격 예측 등
- 장점: 데이터와 정답의 관계를 명확하게 학습할 수 있어, 예측 정확도가 높은 편
- 단점: 레이블이 필요한 데이터를 준비하는 데 많은 시간과 비용이 소요될 수 있음
비지도학습 (Unsupervised Learning)
- 목적: 정답(레이블) 없이, 입력 데이터의 구조나 패턴을 발견하는 데 목적을 둔다. 주로 데이터의 분포를 파악하거나 데이터 간 유사성을 찾는 데 활용된다.
- 작동 방식: 레이블이 없는 데이터를 기반으로, 데이터 내에서 숨겨진 패턴이나 그룹을 찾아낸다.
- 적용 예시:
- 군집화(Clustering): 고객 세그먼트 분류, 유사한 행동을 보이는 사용자 그룹 찾기
- 차원 축소(Dimensionality Reduction): 데이터 시각화, 노이즈 제거, 데이터 압축
- 장점: 레이블 없이도 데이터를 분석할 수 있어, 데이터 준비 비용이 절감
- 단점: 결과 해석이 어렵고, 지도학습보다 예측의 정확성이 낮을 수 있음
3번 문제

문제에서 분류 평가 지표를 사용하여 모델의 성능을 향상시키기 위한 방법을 찾아보면 다음과 같다.
- 데이터의 분산을 증가시킨다.
- 모델의 일반화 성능을 높이는 데 도움을 줄 수 있으며, 과적합을 방지할 수 있다.
- 다른 모델들을 사용해본다.
- 여러 모델을 시도해 보고 성능이 더 좋은 모델을 선택할 수 있다.
- 새로운 특성을 추출하여 특성을 추가한다.
- 특성 엔지니어링을 통해 더 의미 있는 특성을 추가하면 모델의 성능이 향상될 수 있다.
- 편향된 데이터라도 수집하여 데이터의 양을 늘리고 본다.
- 편향된 데이터는 오히려 모델에 좋지 않은 영향을 줄 수 있다. 데이터의 양을 늘리더라도 편향이 유지되면 오히려 성능이 저하될 가능성이 있다.
- 하이퍼 파라미터를 변경해가면서 최적의 파라미터를 찾는다.
- 하이퍼파라미터 튜닝은 모델 성능을 최적화하는 데 중요한 역할을 한다.
따라서 답은 1, 2, 3, 5번이다.

4번 문제


다항식의 차수가 증가할수록 훈련 데이터와 테스트 데이터의 RMSE (평균 제곱근 오차) 변화를 나타내고 있다. RMSE는 낮을수록 좋은 모델 성능을 나타내며, 그래프에서 다항식 차수가 3일 때 일반화가 가장 잘 이루어진 상태라고 한다. 이를 기준으로 문제를 풀어보자.
- 테스트 데이터에서 오차가 최저점이 되는 부분이기 때문에
그래프를 보면, 테스트 데이터의 RMSE가 최저점이 되는 지점은 다항식 차수가 3이 아니다. - 훈련 데이터와 테스트 데이터의 오차가 0.2~0.3 사이 값이기 때문에
다항식 차수가 3일 때, 훈련 데이터와 테스트 데이터의 RMSE가 0.2~0.3 사이에 위치해 있다. - 훈련 데이터와 테스트 데이터에서 오차의 차이가 최소가 되는 부분이기 때문에
다항식 차수가 3일 때, 훈련 데이터와 테스트 데이터 간의 RMSE 차이가 최소가 된다. 이는 일반화가 잘 된 상태를 나타낸다. - 훈련 데이터와 테스트 데이터 모두 오차가 가장 급격히 떨어지는 부분이기 때문에
그래프를 보면 오차가 급격히 떨어지는 부분은 다항식 차수가 1에서 2로 증가할 때이다. 다항식 차수가 3일 때는 오차의 변화가 크지 않다.
따라서 답은 2번과 3번이다.

문제 5번

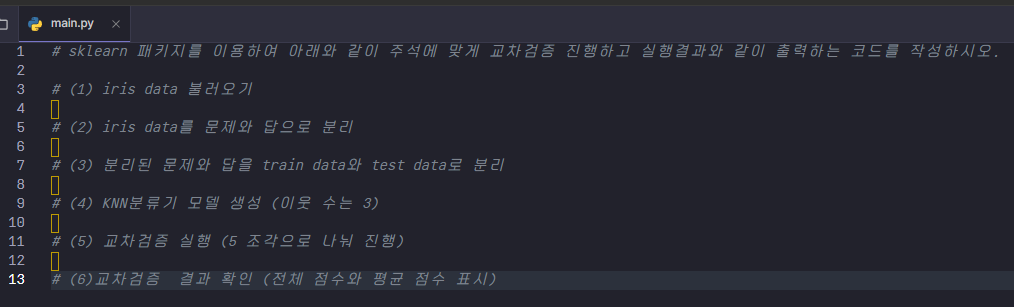
이 문제는 실습 문제라 많이 어려울 것 같아 나중에 풀어보려고 했는데 그냥 지금 풀어보려고 한다.

엘리스 창으로도 풀어보면 다음과 같다. 엘리스 창에서는 글씨가 잘 보이지 않으니 먼저 코랩으로 문제를 풀어보았다. 잘 풀리지는 확인도 할 겸.



근데 이런 오류가 뜨는데 예외가 발생했다는 것이다. cross_val_score에서 모델을 평가할 때 fit을 자동으로 수행하지만, 데이터를 나누는 train_test_split 부분이 교차 검증에는 불필요할 수 있다. 따라서 X_train, y_train 대신 전체 데이터 X, y를 사용하는 편이 좋을 것 같다.
즉, cross_val_score에서 교차 검증은 입력된 데이터를 폴드로 나누기 때문에 별도의 훈련 및 테스트 데이터 분할이 필요하지 않다.
코드 수정하기


여전히 같은 오류가 뜬다. 이 답은 도저히 모르겠어서 그냥 넘어가기로 했다. 이제 시험 시간이 1시간 20분밖에 남지 않았으니 서둘러서 문제를 풀어야 한다.
시험을 마치고
머신러닝 문제는 이론이라 찾아보면서 푸니 나름 풀만 했지만 실습 문제는 많이 어려웠다. 그래도 지금까지 머신러닝 공부한 것이 어느 정도 도움이 되었다. 이어서 컴퓨터 비전 문제를 풀어보겠다.
이 문제를 한 포스트에 담으려고 했더니 분량이 많아서 나누었다.
'개발 포트폴리오 > 수료증 및 시험' 카테고리의 다른 글
| [Spring반] 기말시험 3 - 딥러닝 시험 및 문제 풀이 (0) | 2024.10.31 |
|---|---|
| [Spiring반] 기말 시험 2 - 컴퓨터 비전 시험 및 문제 풀이 (0) | 2024.10.31 |
| SQL로 데이터 다루기 기초 이수증 (0) | 2024.10.19 |
| 비전공자를 위한 머신러닝 이수증 (0) | 2024.10.19 |
| 파이썬 데이터 분석 이수증 (0) | 2024.09.18 |



