
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 머신러닝
- 영어공부
- pandas
- 텍스트마이닝
- 연습문제
- CNN
- 파이썬라이브러리
- 혼공머신
- 데이터입출력구현
- SQL
- CSS
- 코딩테스트
- 딥러닝
- 컴퓨터비전
- 자바 실습
- 중학수학
- JSP/Servlet
- numpy/pandas
- 파이썬
- 정보처리기사실기
- 중학1-1
- 자바
- 컴퓨터구조
- 데이터분석
- 정보처리기사필기
- html/css
- 운영체제
- C++
- 정수와유리수
- 데이터베이스
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
[Spring반] 기말 시험 4 - 시각지능 시험 및 문제 풀이 본문
이제 시각 지능과 언어 지능 시험도 풀어볼 것이다. 시각 지능은 어느 정도 공부했고 언어 지능은 아직 공부하지 않았지만 충분히 풀 수 있을 것 같다.
시각 지능 문제
문제 16번

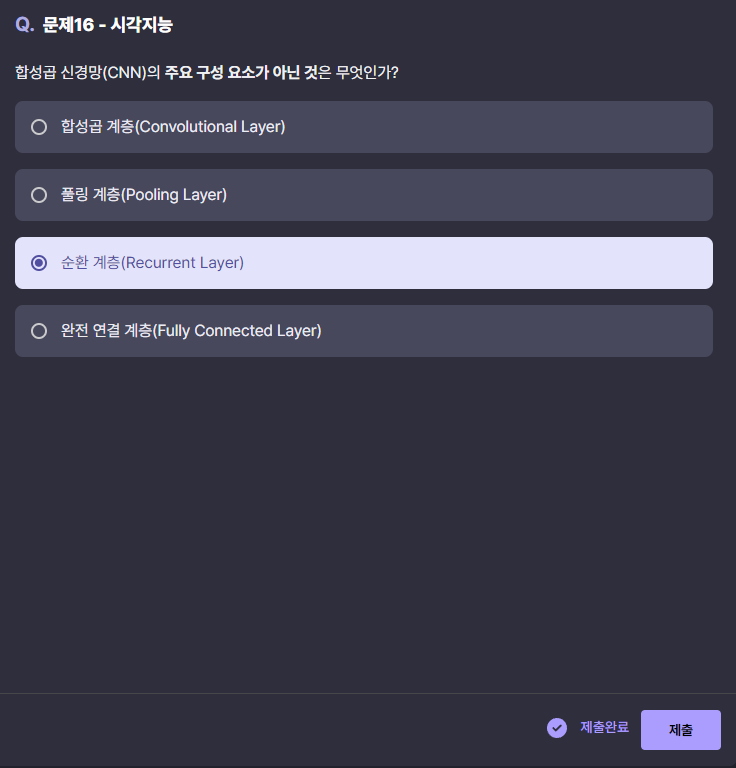
이름을 봐도 순환이라는 말이 들어가면 합성곱 신경망이 아니다. 합성곱 신경망(CNN)의 주요 구성 요소는 합성곱 계층 (Convolutional Layer), 풀링 계층 (Pooling Layer), 그리고 완전 연결 계층 (Fully Connected Layer)이다. 이들은 주로 이미지나 공간적인 데이터를 처리하기 위해 사용된다.
반면, 순환 계층 (Recurrent Layer)은 RNN(Recurrent Neural Network)의 구성 요소로, 시계열 데이터나 순차적인 데이터를 처리하는 데 사용되며, CNN의 구성 요소가 아니다.
문제 17번

조금 헷갈릴 만한 어려운 문제였다. 풀이는 다음과 같다.
- MLP는 2D 구조의 데이터를 처리할 수 있도록 설계되었다.
- MLP는 1차원 벡터 형태의 데이터를 처리하도록 설계되었다. 따라서 이미지와 같은 2D 데이터는 1차원으로 펼친 후 입력해야 한다.
- CNN은 모든 노드가 상호 연결된 완전 연결 구조만을 사용한다.
- CNN은 합성곱 계층과 풀링 계층을 사용하여 지역적 특징을 학습하며, 마지막에만 완전 연결 계층을 사용한다.
- MLP는 입력 데이터의 공간적 구조를 고려하지 않고, CNN은 지역적 특징을 학습한다.
- MLP는 데이터의 공간적 구조를 고려하지 않고 1차원 벡터 형태로 데이터를 처리하지만, CNN은 합성곱 계층을 통해 지역적 패턴을 학습한다. 따라서 맞는 답이다.
- CNN은 데이터를 1차원 벡터로만 입력받는다.
- CNN은 2D (이미지)나 3D (영상) 형태로 데이터를 입력받고 처리할 수 있다.
그러니까 답은 3번이다.

문제 18번


mAP (mean Average Precision)는 객체 탐지 모델의 성능을 평가하기 위해 사용되는 주요 지표이다. 이 지표는 각 클래스별 정밀도(Precision)와 재현율(Recall)의 관계를 통해 정확도를 계산한 후, 여러 클래스의 평균 정밀도(AP)를 산출하여 모델의 전반적인 성능을 평가한다.
따라서 mAP는 다양한 클래스의 평균 정밀도를 기반으로 모델의 객체 탐지 성능을 평가하는 목적에 적합한 지표이다.
- 객체의 크기를 비교하거나 모델의 성능을 평가하는 것: mAP는 객체 크기와 무관하며, 전반적인 정확도를 평가
- 이미지의 해상도를 평가하거나 학습 속도를 측정하는 것: mAP는 이미지 해상도나 학습 속도와 관련이 없음
mAP에 대해서 잘 모르지만 왠지 평균과 관련이 있을 것 같았다.
문제 19번


미세조정(Fine-Tuning)은 전이 학습의 한 방식으로, 이미 사전 학습된 모델을 새로운 데이터셋에 맞추어 추가 학습하는 방법이다. 일반적으로 미세조정에서는 모델의 하위(기본적인 특징을 학습하는) 층은 고정하고, 상위(특정 작업에 맞춘) 층을 재학습하는 방식으로 진행된다. 이를 통해 새로운 데이터셋에 대한 적응력이 생기면서도, 기존에 학습한 일반적인 특징은 유지할 수 있다.
- 사전 학습 된 모델을 그대로 사용하고, 추가 학습을 하지 않는 방법: 이는 미세조정이 아니라 특징 추출(feature extraction)로, 미세조정과 다르다.
- 모든 층을 고정한 상태로 출력층만 학습시키는 방법: 이는 고정된 특징 추출 방식이다. 미세조정은 일부 층을 고정하지 않고 재학습하는 것이 핵심이다.
- 새로운 데이터셋에 맞춰 처음부터 모든 파라미터를 다시 학습하는 방법: 이는 전이 학습이 아니라, 모델을 처음부터 학습하는 것이다.
이 문제도 잘 풀었다.
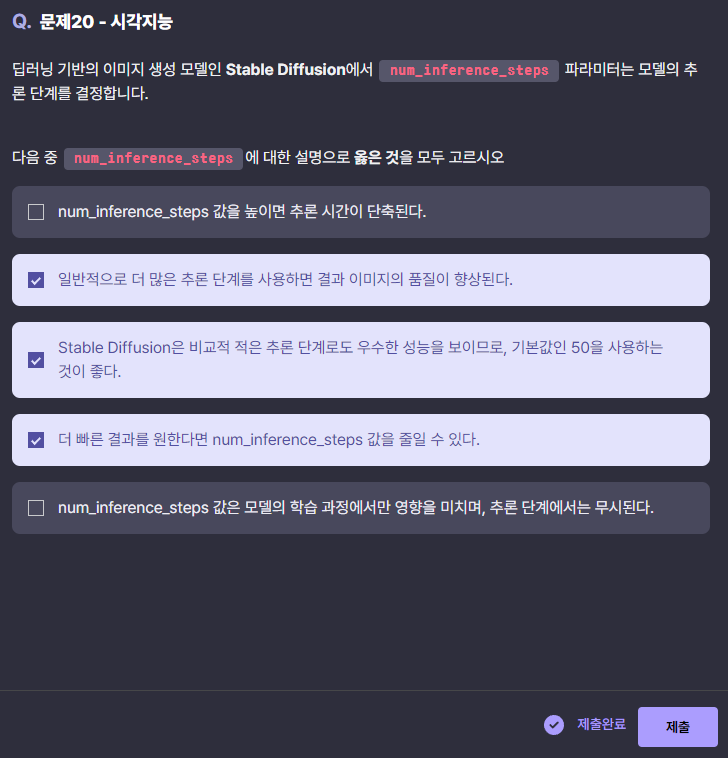
문제 20번

이 문제는 시각지능 문제에서 유일하게 풀기 어려웠다. 답지를 차근차근 살펴보기로 하자.
- num_inference_steps 값을 높이면 추론 시간이 단축된다.
- num_inference_steps 값을 높이면 추론 시간이 늘어난다. 추론 단계가 많아지면 모델이 더 많은 계산을 수행하기 때문에 시간이 더 걸린다.
- 일반적으로 더 많은 추론 단계를 사용하면 결과 이미지의 품질이 향상된다.
- num_inference_steps가 많을수록 모델이 더 많은 단계를 통해 이미지를 생성하므로, 이미지의 품질이 높아질 가능성이 있다. 다만 너무 많으면 성능 개선이 미미할 수 있다.
- Stable Diffusion은 비교적 적은 추론 단계로도 우수한 성능을 보이므로, 기본값인 50을 사용하는 것이 좋다.
- 부분적으로 맞다. Stable Diffusion은 기본적으로 50단계를 권장하지만, 사용 목적이나 필요에 따라 단계를 조절할 수 있다. 성능과 품질 사이의 균형을 맞추려면 50단계가 적당한 기본값이다.
- 더 빠른 결과를 원한다면 num_inference_steps 값을 줄일 수 있다.
- num_inference_steps 값을 줄이면 추론 시간이 줄어들고, 더 빠르게 결과를 얻을 수 있다. 다만 이미지 품질이 다소 낮아질 수 있다.
- num_inference_steps 값은 모델의 학습 과정에서만 영향을 미치며, 추론 단계에서는 무시된다.
- num_inference_steps는 추론 단계에서 사용되는 매개변수이며, 모델이 이미지를 생성할 때 중요한 역할을 한다. 학습 과정이 아닌 추론 과정에서 사용된다.
그러니까 답은 2, 3, 4번이다.
시험을 마치고
10문제나 되는 문제를 한 포스트에 담기는 많으니 언어 지능 문제는 다음 글쓰기 공간에 써볼 것이다. 이제 5문제만 남았다. 마지막까지 힘내서 문제를 풀어보자.
'개발 포트폴리오 > 수료증 및 시험' 카테고리의 다른 글
| SQL로 데이터 다루기 심화 이수증 (0) | 2024.10.31 |
|---|---|
| [Spring반] 기말 시험 5 - 언어지능 시험 및 문제 풀이 (0) | 2024.10.31 |
| [Spring반] 기말시험 3 - 딥러닝 시험 및 문제 풀이 (0) | 2024.10.31 |
| [Spiring반] 기말 시험 2 - 컴퓨터 비전 시험 및 문제 풀이 (0) | 2024.10.31 |
| [Spiring반] 기말 시험 1 - 머신러닝 시험 및 문제 풀이 (0) | 2024.10.31 |



