
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- CSS
- 딥러닝
- html/css
- numpy/pandas
- 데이터분석
- 연습문제
- 파이썬라이브러리
- 텍스트마이닝
- 정보처리기사필기
- 영어공부
- 컴퓨터구조
- CNN
- 컴퓨터비전
- 중학수학
- SQL
- 운영체제
- 자바 실습
- 데이터베이스
- C++
- 혼공머신
- 정보처리기사실기
- 코딩테스트
- pandas
- 정수와유리수
- 중학1-1
- 머신러닝
- 자바
- JSP/Servlet
- 데이터입출력구현
- 파이썬
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
CNN 15 - 이미지 생성 모델의 이해 1 : 이미지 생성 모델의 원리, 생성자와 판별자 프로세스에 대하여 본문
원래 어제 5시까지 특강이 있었는데 너무 지루하고 별로 도움이 되는 강의도 아닌 것 같아 3시쯤 나와서 집에 왔다. 집에 가서 공부를 시작한 지 30분도 되지 않아 정말 졸리고 피곤해서 도저히 공부에 집중할 수 없었다. 차라리 저녁을 일찍 먹고 일찍 취침한 후 다음날 일어나서 공부를 해야겠다고 생각했다.
사실 딥러닝 공부는 많이 지루하고 재미는 없다. 그냥 필요하니까 하는 거지 재미있어서 하는 공부는 아니었다. 딥러닝과 시각지능을 1주일 넘게 공부하다 보니(이번주에는 다른 일정이 있어 많아 평소 공부량의 절반도 되지 않았음) 이제는 정말 지루해서 RNN까지는 공부하기 힘들 것 같다.
중간에 다른 과목으로 좀 틀었다가 다시 나머지 공부를 진행하는 것이 나을 것 같았다. 처음 딥러닝을 공부할 때도 이런 식으로 하니 공부를 이어갈 수 있었다. 아무튼 어제 오후 5시에 취침을 해서 다음날 3시 넘어서 일어났다. 무려 10시간 넘게 잠을 잔 것이다. 가끔씩 난 잠을 아주 많이 잘 때가 있는데 어제는 잠이 많이 필요한 날이었나 보다.
아마도 요즘 외부 일정이 많고 사람들을 많이 만났더니 좀 힘들어서 피로가 쌓인 것 같다.
이미지 생성 모델의 원리 이해하기

보통 단일 모델을 많이 활용하여 입력층부터 출력층까지 순차적으로 처리되는 선형 모델이다. 생성 모델은 모델을 두 개 세 개 엮어서 사용한다. GAN도 생성자와 판별자라고 하는 딥러닝 네트워크를 연결해서 학습해서 생성하는 모델이다.
이제 이 개념을 차근차근 알아보겠다.


왼쪽이 생성자, 오른쪽이 판별자로 둘 다 Convolution Network를 형성한다. 생성자는 이미지를 만들어내는 값을 의미하며 랜덤하게 만들어진 숫자 묶음으로부터 내가 원하는 이미지를 생성한다. 디코더의 구조와 비슷하다. 디코더는 압축된 파일을 복원시켜 주는 역할을 하는 것이다. 즉 압축한 램덤한 숫자를 풀어서 우리가 원하는 결과를 만드는 것이기 때문이다.
판별자는 이미지를 집어넣으면 진짜인지 가짜인지 구별하는 단순 분류 모델이다. 진짜이면 1, 가짜이면 0으로 분류한다. 두 가지가 서로 경쟁하며 학습하게 되는데, 생성자는 진짜 같은 이미지를 만들어내고 판별자는 이미지가 진짜인지 가짜인지 잘 판별한다. GAN을 예로 들 때 경찰과 도둑 이야기를 많이 한다.
판별자 훈련 프로세스

판별자는 이미지로 진짜인지 가짜인지 예측하는데 진짜 이미지를 절반 넣고, 생성자가 만든 가짜 이미지 절반을 넣어 학습을 수행한다. 판별자는 어느 정도 학습이 완료되면 일시정지 한다. 그리고 나서 생성자가 학습을 시작하는데, 판별자가 학습이 정지된 상태에서 수행한다.
생성자 훈련 프로세스

생성자는 판별자의 도움을 받아서 학습한다. 판별자는 학습이 정지된 상태이다. 여기서 D라고 보이는 부분이 판별자이다. 생성자는 랜덤한 숫자로부터 이미지를 생성한다. 처음에는 잘못된 이미지를 만드는데 판별자에게 집어넣으면 이것이 가짜 이미지라는 것을 안다. 이때 생성자가 만든 판별값과 실제 이미지의 값을 분석하는데 이 차이를 Loss 손실값이라고 한다. 판별자는 진짜와의 차이인 간격을 조사하고 이 값을 생성자에게 넘겨준다.
생성자는 가짜와 진짜와의 차이를 알기 때문에 모델을 업데이트한다. 다음에는 좀 더 정교한 모델로 업데이트하는 과정을 계속 반복한다. 이렇게 두 개가 학습을 별개로 진행한다.
Diffusion



분자가 확산하는 모습을 이미지에 녹여서 만들어낸 모델이다. 위에 있는 그림은 Diffusion이 커지는 모습을 표현한 것이다. 이것을 분자라고 말하는데, 분자에게 힘을 가하면 위쪽으로 퍼지면서 패턴이 만들어진다. 이때 어떤 형태로 분자가 만들어졌는지를 알게 되면 다시 원래 형태로 만들 수 있다는 원리이다.
아래 그림은 이미지에다 Diffusion을 녹인 예시이다. 이미지의 픽셀을 분자라는 개념으로 이해하면 된다. 픽셀에 노이즈 값을 취하면 이미지가 흐려진다. 여기에 노이즈를 계속 추가하면 결국 아무런 형태가 없는 순수한 노이즈 값만 갖게 된다. 이것도 노이즈 값을 얼마나 주었는지 기억하여 연산하면 거꾸로 원래 이미지로 복원할 수 있다는 개념이다.

이 U-Net 모델은 소카 이미지 Segmentation에서도 등장했다. U-Net은 모델이 U자 형태로 되어 있기 때문에 이렇게 부른다.
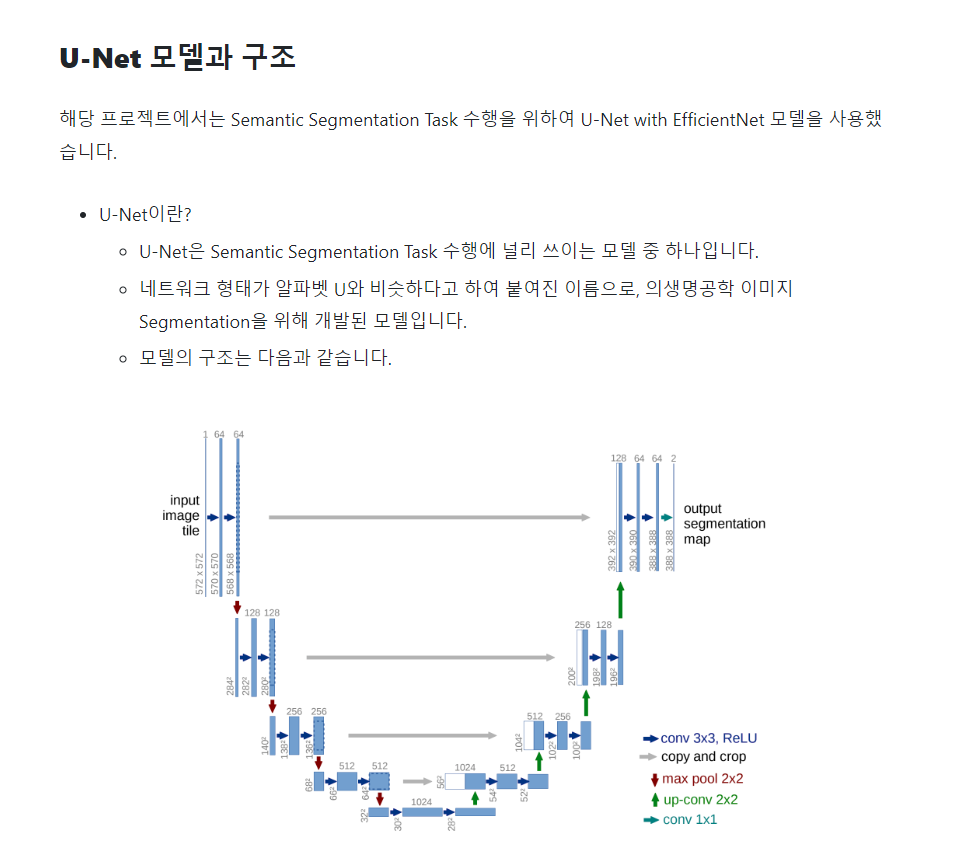
U자 형태를 반으로 쪼개서 앞쪽은 인코더 역할을, 뒤쪽은 디코더 역할을 한다. 그리고 각각은 CNN 레이어로 압축된 정보를 통과시키도록 한다. 압축된 정보를 복원할 때도 Convolution Network가 활용된다. 압축할 때 너무 많이 압축하면 정보가 별로 없으니 압축이 조금 덜 된 결과를 참조한다. 이것을 Skip Connection이다.
ㅗ

Diffusion에서는 리본 모양으로 많이 표현한다.
학습을 마치고
어제 특강을 가지 말고 그냥 집에서 공부나 할 걸 하는 후회가 들었다. 특강에 가서 정말 별거 없었고 차라리 그 시간에 공부를 했더라면 에너지가 부족해서 어제처럼 잠만 자는 일도 없었을 것 같다. 다음에는 외부 활동을 줄이고 좀더 내가 해야 할 일에 집중하며 진짜 중요한 것이 무엇인지 잘 선택하기로 다짐했다.
실패를 통해서도 많이 배운다. 난 내향형이고 그것도 내향적인 부분이 아주 강한 사람이기 때문에 다른 사람보다 이런 에너지 관리에 무척 신경을 써야 한다. 11월 말쯤 진행하려고 했던 프로젝트는 잠시 미루어야 할 것 같다. 지금은 더 공부하고 배울 시기이다.



