
- 분류 전체보기 (1249)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 데이터베이스
- 정보처리기사실기
- 정수와유리수
- SQL
- 컴퓨터구조
- numpy/pandas
- 딥러닝
- CNN
- 자바 실습
- 연습문제
- pandas
- 중학1-1
- CSS
- 혼공머신
- 파이썬라이브러리
- 파이썬
- 코딩테스트
- 머신러닝
- html/css
- 텍스트마이닝
- C++
- 영어공부
- 데이터입출력구현
- 자바
- 중학수학
- 정보처리기사필기
- 컴퓨터비전
- 운영체제
- 데이터분석
- JSP/Servlet
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
CNN 16 - 이미지 생성 모델의 이해 2 : Diffusion 모델의 잡음 예측기 학습 및 예측 과정과 다양한 활용법 본문
CNN 16 - 이미지 생성 모델의 이해 2 : Diffusion 모델의 잡음 예측기 학습 및 예측 과정과 다양한 활용법
huenuri 2024. 11. 3. 05:39이번에는 이미지 생성 모델 실습을 하기 전에 Diffusion 모델에 대해서 더 공부해보려고 한다.
Diffusion 모델에 대하여
잡음 예측기의 학습 과정

Forward diffusion은 작음 예측기를 학습하는 과정이다. 원본 이미지에 노이즈 값을 지속적으로 추가하여 완전한 노이즈가 될 때까지 학습을 수행한다.
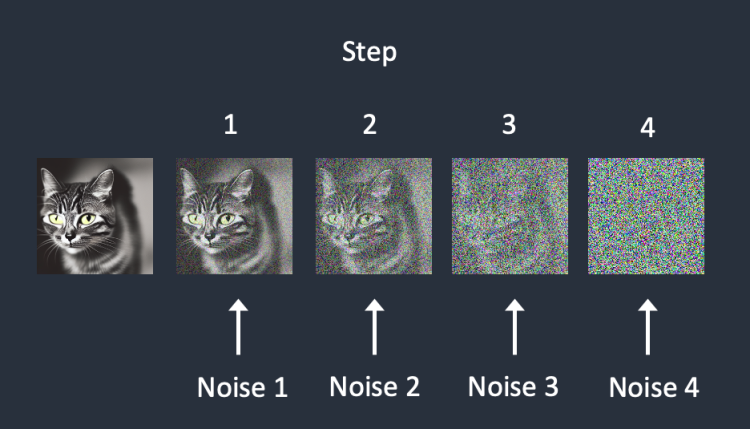
여기서는 총 네 번에 걸쳐 수행하는 과정을 보여준다. 처음에는 오리지널 이미지가 있는데 여기에 랜덤하게 숫자를 넣어 각 픽셀마다 연산한다. 그러면 1차 노이즈 이미지가 만들어지면 1번 이미지를 잡음 예측기 안에 집어넣는다. 잡음 예측기는 잡음 예측 정도를 계산한다. 실제 잡음 예측값과 잡음 예측기의 예측값의 차이를 계산하여 잡음 예측기의 값을 업데이트한다. 2번은 1번보다 더 노이즈가 된 이미지로 반복해서 이 과정을 수행한다.
이 잡음 예측이 어느 정도 되면 Reverse 프로세스가 이어진다.

잡음 예측기는 노이즈값이 얼마나 끼어있는지를 예측한다.
잡음 예측기의 예측 과정

예측 과정은 학습 과정과는 반대로 일어난다. 노이즈 데이터로부터 잡음 예측기에게 예측을 시켜 원래 이미지를 생성하는 과정을 Reverse Diffusion이라고 한다. 학습이 된 잡음 예측기에 완전한 노이즈 이미지를 집어 넣으면 노이즈 값을 알려준다.

그러면 이 잡음값을 조금 빼준다. 잡음을 빼주면 이미지가 조금씩 노이즈 값에서 회복이 되고 이 과정을 반복을하면 원래 원본 이미지로 복원된다.

잡음 예측기의 문제점 해결 방법


잡음 예측기에 원래 이미지를 집어 넣지 않고, 원래 이미지를 인코딩하여 압축된 정보로 만든 다음에 압축된 정보를 잡음 예측기에 집어 넣는 것이다. 인코더는 불필요한 정보를 제거하고 인코더 정보로 만든다. 사람이 보기에는 사진처럼 안 보일뿐 고양이에 대한 정보를 모두 담고 있다. 이것을 잡음 예측기의 입력으로 집어 넣고 여기에 노이즈를 조금씩 넣어 완전한 노이즈가 될 때까지 학습한다.
반대로 완전한 노이즈 데이터에서 잡음이 얼마나 추출되었는지 결과물을 뽑아낸다. 이것을 사람이 볼 수 있는 픽셀 단위로 변환해주는 것이 디코더이다.
여기서 사람이 개입할 수 있는 condition이라는 요소가 추가된다.
Diffusion 모델의 다양한 활용법

압축된 정보에 사용자가 필요한 정보를 삽입한다. 추가된 정보를 기반으로 복원하기 때문에 자신이 원하는 결과로 유도할 수 있다. 원래는 랜덤한 이미지로부터 시작하니 제어할 수 없었다.
1. 텍스트를 이용한 이미지 생성 프로세스

랜덤한 정보에 텍스트 프롬프트를 입력으로 집어 넣는다. 이 텍스트 정보를 숫자로 변환하여 노이즈 예측기에 입력으로 넣는다. 그러면 이 둘이 결합하여 최종적으로 자신이 의도한 정보가 삽입되어 만들어진다.
2. 이미지를 활용한 이미지 생성


엉성한 사과를 기반으로 진짜 사과를 만들고 싶다면, 엉성한 이미지를 인코더를 통해 압축된 잠재 이미지 텍터로 만든다. 이 잠재 이미지 벡터를 시작점으로 사용한다. 그러면 사과에 대한 형체 정보를 가지고 있는 상태로 노이즈가 있다고 생각하고 만들게 되고, 사과 형태 이미지를 유도할 수 있다. 이것을 condition이라고 부른다.
어떤 이미지 사진이 있을 때 그중 원하는 부분만 이미지 형태로 바꿀 수 있다. 바깥의 잘리는 부분만 추출해서 정상적인 상태로 만들 수 있다. 상태만 조절하면 자신이 원하는 형태로 만들 수 있으니 요즘 Diffusion이 각광받는다.
학습을 마치고
여기까지 1시간 반 동안 개념 학습이 진행되었다. 실습부터는 조금 더 재미있는 과정이 이어질거라 기대해본다. 어제는 정말 이해하기 어려웠을텐데 역시 공부는 집중력이 잘 되는 시간에 하는 것이 가장 좋다는 걸 느꼈다.
Diffusion을 통해 어떻게 이미지 학습과 예측을 하는지 배울 수 있는 시간이었다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| CNN 18 - 이미지 생성 모델 실습해보기 2 : 이미지 인페인팅으로 특정 부분 채우기 (2) | 2024.11.03 |
|---|---|
| CNN 17 - 이미지 생성 모델 실습해보기 1 : Stable Diffusion 기초 실습 (0) | 2024.11.03 |
| CNN 15 - 이미지 생성 모델의 이해 1 : 이미지 생성 모델의 원리, 생성자와 판별자 프로세스에 대하여 (2) | 2024.11.03 |
| CNN 14 - Image Segmentation 5 : 커스텀 데이터를 활용한 차량 파손 범위 예측 실습 2 - 영상 이미지 (0) | 2024.11.02 |
| CNN 13 - Image Segmentation 4 : 커스텀 데이터를 활용한 차량 파손 범위 예측 실습 1 - 사진 이미지 (0) | 2024.11.02 |



