
- 분류 전체보기 (1852)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 개발일기
- 데이터분석
- 혼공머신
- JSP/Servlet
- 정보처리기사필기
- html/css
- 컴퓨터비전
- JSP
- 자바 실습
- 상속
- 중학수학
- 스프링
- 딥러닝
- JDBC
- 정보처리기사실기
- rnn
- 머신러닝
- ChatGPT
- 자바스크립트심화
- 데이터베이스
- 중학1-1
- 타입스크립트심화
- 파이썬
- 스프링프레임워크
- 연습문제
- SQL
- 자바
- 자바스크립트
- 디버깅
- 쇼핑몰홈페이지제작
- Today
- Total
"게임 개발자"를 향한 매일의 공부일지 1기 : 2024년 5 ~ 12월
딥러닝 비전 6 - 다층 퍼셉트론 구현하기 1 : 필기 숫자 인식과 성능 시각화 본문
이번 장은 실습 프로그램이 있어서 나름 괜찮은 학습이 될 것 같다. 이전 절에서 프로그램 7-1을 통해 텐서플로가 제공하는 MNIST와 CIFAR-10 데이터셋을 확인하는 프로그래밍 실습을 했다. 여기서는 앞에서 배운 다층 퍼셉트론과 깊은 다층 퍼셉트론을 텐서플로로 구현하고 성능을 측정하는 실험을 한다.
1. 필기 숫자 인식
다음 프로그램은 다층 퍼셉트론으로 MNIST를 인식하는 실험이다. 1980~1990년대의 다층 퍼셉트론 시대에 주로 사용하던 SGD 옵티마이저와 현대 딥러닝이 주로 사용하는 Adam 옵티마이저의 성능을 비교하는 실험도 한다.
다층 퍼셉트론으로 필기 숫자 인식
텐서플로로 신경망을 학습하고 예측하는 첫 프로그래밍이다.
다층 퍼셉트론으로 MNIST 인식하기(SGD 옵티마이저)


이 코드는 MNIST 데이터셋을 이용하여 다층 퍼셉트론(MLP) 신경망을 학습하고 평가하는 프로그램이다. MNIST 데이터셋은 손글씨 숫자 이미지로 이루어져 있으며, 각 이미지를 0부터 9까지의 숫자로 분류하는 문제이다. 이 코드는 다음과 같은 과정으로 이루어져 있다:
- 데이터 로드 및 전처리: MNIST 데이터를 불러와서 학습 데이터와 테스트 데이터로 분리하고, 데이터를 모델에 적합한 형태로 변환한다. 특히 이미지를 1차원 벡터로 펼치고, 각 픽셀 값을 0과 1 사이의 값으로 정규화하며, 레이블을 원-핫 인코딩한다.
- MLP 모델 정의: 입력층, 은닉층, 출력층으로 구성된 MLP 모델을 정의한다. 은닉층은 512개의 뉴런을 가지며 tanh 활성화 함수를 사용하고, 출력층은 10개의 뉴런을 가지며 softmax 활성화 함수를 사용하여 각 숫자에 대한 확률을 예측한다.
- 모델 컴파일 및 학습: 모델을 컴파일하여 손실 함수와 최적화 방법을 정의하고, 학습 데이터를 이용하여 모델을 학습시킨다.
- 모델 평가 및 결과 출력: 테스트 데이터를 통해 모델의 성능을 평가하고, 정확률을 출력한다.
코드는 손글씨 숫자 이미지 분류 문제를 풀기 위한 기본적인 신경망 모델을 구현한 예제이다.
코드 실행해보기



마지막에 경고 메시지가 떠서 뭔가 잘못 되었나 했는데 아니었다.
학습 과정 (Epoch 1~50)
- 손실 감소: 첫 번째 에포크에서 loss 값이 0.0886이었고, 마지막 에포크에서는 0.0187로 점차 감소하였다. 이는 모델이 학습 데이터에 대해 점점 더 적합해지고 있다는 의미이다.
- 정확도 증가: accuracy는 첫 번째 에포크에서 0.1726 (약 17%)였지만, 마지막 에포크에서는 0.8881 (약 88.8%)로 상승하였다. 이는 모델이 학습 데이터에서 예측 정확도를 점차 높여갔음을 나타낸다.
- 검증 성능: val_loss와 val_accuracy도 마찬가지로 개선되었으며, 마지막 에포크에서 검증 정확도(val_accuracy)가 약 89.6%에 도달하였다. 이는 모델이 학습 데이터뿐 아니라 새로운 테스트 데이터에도 잘 일반화되고 있음을 의미한다.
최종 평가
- 정확률 출력: 정확률= 89.6399974822998은 테스트 데이터에 대한 최종 정확도로, 약 89.6%의 정확도를 달성하였다. MNIST 데이터셋에서 MLP 모델로 이 정도의 정확도는 적절한 성능이다.
경고 메시지
마지막에 나온 경고는 TensorFlow가 CPU 최적화와 관련된 내용으로, 현재 CPU 환경에서 최적화를 활용하고 있다는 정보이다. 이는 성능에 관한 것이므로 학습 결과에는 영향을 미치지 않는다.
결론
모델이 성공적으로 학습되었고, 약 89.6%의 정확도로 테스트 데이터를 분류할 수 있게 되었다.
코드에 대한 자세한 설명
1. 라이브러리 임포트
import numpy as np
import tensorflow as tf
import tensorflow.keras.datasets as ds
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD- numpy: 배열 연산과 데이터 전처리에 사용.
- tensorflow: 신경망 모델 구축 및 학습.
- tensorflow.keras.datasets: 데이터셋 로드를 위해 사용.
- Sequential, Dense, SGD: 신경망 모델 구조, 밀집층 정의, SGD 최적화 알고리즘.
2. MNIST 데이터셋 불러오기 및 전처리
(x_train, y_train), (x_test, y_test) = ds.mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)- 데이터 로드: ds.mnist.load_data()로 학습 데이터와 테스트 데이터를 불러온다.
- 데이터 형상 변환: 이미지는 28x28 크기의 2차원 배열이므로 (60000, 784)와 (10000, 784) 크기로 변환하여 1차원 벡터로 펼친다.
- 정규화: 이미지의 픽셀 값(0~255)을 0~1 범위로 스케일링하여 신경망이 학습하기 쉽게 한다.
- 라벨 원-핫 인코딩: 0~9 사이의 정수 레이블을 원-핫 벡터로 변환하여 각 숫자에 대한 확률을 예측하도록 만든다.
3. MLP 모델 정의
mlp = Sequential()
mlp.add(Dense(units=512, activation='tanh', input_shape=(784,)))
mlp.add(Dense(units=10, activation='softmax'))- 모델 구조: Sequential 모델을 사용하여 계층적으로 층을 추가한다.
- 은닉층: 첫 번째 Dense 층은 512개의 뉴런과 tanh 활성화 함수를 사용한다. 입력 크기는 784차원이다.
- 출력층: 두 번째 Dense 층은 10개의 뉴런과 softmax 활성화 함수를 사용하여 각 숫자(0~9)에 대한 확률을 예측한다.
4. 모델 컴파일
mlp.compile(loss='MSE', optimizer=SGD(learning_rate=0.01), metrics=['accuracy'])- 손실 함수: MSE (Mean Squared Error, 평균 제곱 오차)를 사용하여 예측과 실제 값의 차이를 측정한다.
- 최적화 함수: SGD (확률적 경사 하강법) 알고리즘을 사용하며 학습률은 0.01로 설정
- 평가지표: 모델의 성능을 평가하기 위해 accuracy(정확도)를 사용한다.
5. 모델 학습
mlp.fit(x_train, y_train, batch_size=128, epochs=50, validation_data=(x_test, y_test), verbose=2)- 학습 데이터: x_train과 y_train을 사용해 모델을 학습시킨다.
- 배치 크기: 128개의 샘플씩 나누어 학습
- 에포크 수: 50번 반복하여 전체 데이터를 학습한다.
- 검증 데이터: validation_data에 (x_test, y_test)를 지정하여 각 에포크 끝에서 성능을 평가
- 출력 설정: verbose=2로 학습 과정을 자세히 출력
6. 모델 평가 및 결과 출력
res = mlp.evaluate(x_test, y_test, verbose=0)
print('정확률=', res[1] * 100)- 모델 평가: 테스트 데이터 (x_test, y_test)를 사용해 학습된 모델의 성능을 평가하고, 정확도 값을 res[1]에 저장.
- 결과 출력: 정확률=을 통해 최종 정확도를 백분율로 표시한다.
요약
이 코드는 MNIST 데이터셋을 이용해 손글씨 숫자 이미지를 분류하는 MLP 신경망을 학습, 검증, 평가하는 프로그램이다. MLP 모델은 입력 이미지를 0~9 사이의 숫자로 분류하기 위해 설계되었으며, 학습 과정에서는 SGD 최적화 방법과 MSE 손실 함수를 사용하였다.
다층 퍼셉트론으로 필기 숫자 인식 : Adam 옵티마이저
프로그램 7-3은 프로그램 7-2의 compile 함수에서 SGC를 Adam으로 바꾼 프로그램이다. 학습률을 뜻하는 learning_rate 인수는 Adam의 기본값인 0.001로 설정했다.
다중 퍼셉트론으로 MNIST 인식하기(Adam 옵티마이저)
이 코드는 MNIST 데이터셋을 사용하여 다층 퍼셉트론(MLP) 신경망을 학습하고 평가하는 프로그램이다. 이 프로그램은 Adam 최적화 알고리즘을 사용하여 손글씨 숫자를 분류하는 모델을 학습시키고, 테스트 데이터로 정확도를 평가하여 출력한다.


코드 요약
- 데이터 로드 및 전처리: MNIST 데이터를 불러와서 이미지를 1차원 벡터로 변환하고, 픽셀 값을 0~1 사이로 정규화한다. 레이블은 원-핫 인코딩으로 변환한다.
- 모델 정의: 입력층, 은닉층(512개 뉴런, tanh 활성화 함수), 출력층(10개 뉴런, softmax 활성화 함수)으로 이루어진 MLP 모델을 정의한다.
- 모델 컴파일: 손실 함수로 평균 제곱 오차(MSE)를 사용하고, Adam 최적화 기법을 적용한다.
- 모델 학습: 학습 데이터로 50에포크 동안 모델을 학습시키며, 검증 데이터로 성능을 평가한다.
- 모델 평가 및 결과 출력: 테스트 데이터로 모델의 성능을 평가하여 정확도를 백분율로 출력한다.
코드 실행하기

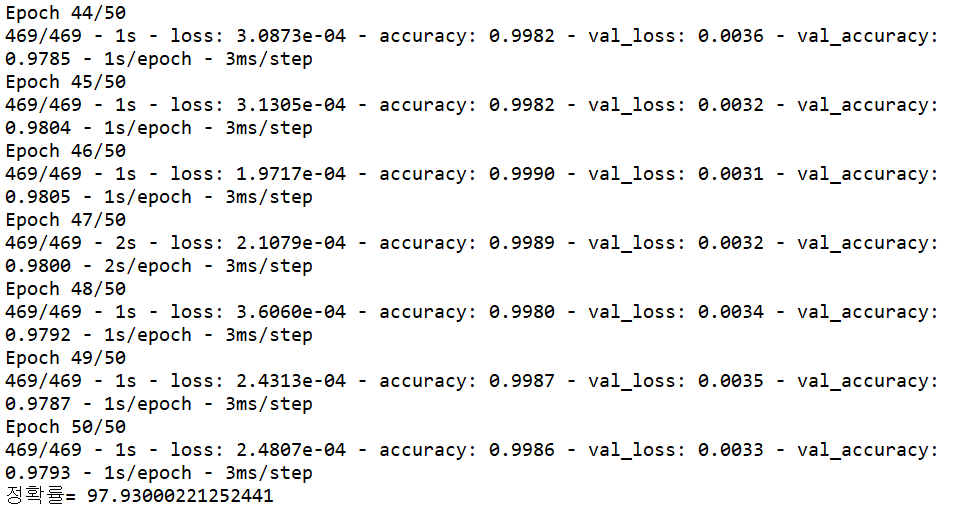
프로그램 실행 결과를 보면 놀랍게 향상된 성능을 확인할 수 있다. 첫 세대 만에 93.24%의 정확률을 달성하여 sgd를 사용한 프로그램이 50세대를 마친 후의 89.63%를 능가했다. Adam이 50세대를 마친 정확률은 97.93%로 SGD보다 8% 이상 증향상되었다.
2. 성능 시각화
텐서플로는 시각화에 쓸 수 있는 다양한 정보를 제공한다. 여기서는 SGD와 Adam의 성능을 비교할 목적으로 시각화를 이용한다. 프로그램 7-4는 2개의 다층 퍼셉트론을 만들고 각각 SGD와 Adam 옵티마이저로 학습을 수행한다.
다층 퍼셉트론으로 MNIST 인식하기(SGD와 Adam의 성능 비교 그래프)
이 코드는 MNIST 손글씨 이미지 분류 문제에서 두 가지 최적화 기법, SGD와 Adam을 사용하여 MLP 신경망을 각각 학습시키고, 두 기법의 성능 차이를 그래프로 비교하는 프로그램이다.



코드 요약
- 데이터 로드 및 전처리: MNIST 데이터셋을 불러와 1차원으로 펼치고 정규화하며, 레이블을 원-핫 인코딩으로 변환한다.
- SGD 모델 정의 및 학습: SGD 최적화 기법을 사용하는 MLP 모델을 정의하고 학습시키며, 최종 정확도를 출력한다.
- Adam 모델 정의 및 학습: Adam 최적화 기법을 사용하는 MLP 모델을 정의하고 학습시키며, 최종 정확도를 출력한다.
- 성능 비교 그래프: 두 모델의 학습 및 검증 정확도를 에포크마다 비교하여 시각화한다.
이 코드를 통해 SGD와 Adam 두 최적화 알고리즘의 성능을 비교하고, 어떤 알고리즘이 더 빠르게 높은 정확도를 달성하는지 확인할 수 있다.
코드 실행하기


출력은 잘 되었지만 몇 가지 문제가 발생했다.


그래서인지 그래프는 하나도 출력되지 않았다. 출력 내용을 보면 모델 학습과 평가 자체는 성공적으로 완료된 것으로 보인다. SGD와 Adam 최적화 기법을 각각 사용한 모델의 학습이 끝났고, 정확률도 정상적으로 출력되었다.
그러나 마지막에 발생한 에러 메시지는 OpenMP(병렬 처리를 위한 라이브러리)와 관련된 충돌로 보인다. 주요 원인은 OpenMP의 다중 라이브러리 초기화 문제로, libiomp5 라이브러리가 여러 번 초기화되면서 충돌이 발생하는 것이다. 이 문제는 성능 최적화와 관련된 경고로, 그래프 출력 시 충돌을 일으키고 Python 인터프리터가 비정상적으로 종료된 것으로 보인다.
해결 방법
환경 변수 설정
아래 코드를 실행하여 KMP_DUPLICATE_LIB_OK 환경 변수를 설정해, 라이브러리 충돌을 피하도록 한다.

다시 실행
환경 변수를 설정한 후, 그래프를 그리는 코드를 다시 실행해보면 정상적으로 그래프가 출력될 가능성이 높다.




이제 잘 실행된다. 그리고 다음과 같이 그래프로 그려졌다. 두 가지 옵티마이저의 정확률이 출력되었다.

프로그램 실행 결과를 살펴보자. Adam은 98%, SGD는 89%를 달성하여 무려 9%나 차이가 난다. 학습 곡선을 살펴보면 Adam이 SGD를 확실히 능가함을 확인할 수 있다. Adam은 훈련 집합에 대해 100% 가까운 성능을 달성했으며, 테스트 집합에 대해서는 10세대 근방에서 수렴했다.
SGD는 50세대에서도 수렴이 안 되어 세대 수를 늘리면 추가적인 성능 향상이 나타날 것이라고 예상할 수 있다.
학습을 마치고
코드를 실행할 때 안 되는 부분이 좀 많아서 예상했던 것보다 공부 시간이 30분 이상 뒤쳐졌다. 이제 빠르게 나머지 학습을 진행해볼 것이다. 오늘은 아침에 약속이 있어서 그 전에 새벽 공부를 마치고 수학과 영어 공부까지 다 하려고 하니 무척 바쁘다. 그래도 분명 다 할 수 있으리라 믿는다.
'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| 딥러닝 비전 8 - [비전 에이전트 5] 우편번호 인식기 v.1 (0) | 2024.11.13 |
|---|---|
| 딥러닝 비전 7 - 다중 퍼셉트론 구현하기 2 : 하이퍼 매개변수 다루기 (0) | 2024.11.13 |
| 딥러닝 비전 5 - 학습 알고리즘 (0) | 2024.11.13 |
| 딥러닝 비전 4 - 깊은 다층 퍼셉트론 (0) | 2024.11.13 |
| 딥러닝 비전 3 - 인공 신경망의 태동 (0) | 2024.11.13 |



