
- 분류 전체보기 (1250)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- html/css
- 운영체제
- CSS
- 데이터베이스
- numpy/pandas
- 파이썬
- 연습문제
- 딥러닝
- 영어공부
- JSP/Servlet
- 텍스트마이닝
- 파이썬라이브러리
- CNN
- 자바
- C++
- pandas
- SQL
- 혼공머신
- 정수와유리수
- 코딩테스트
- 머신러닝
- 정보처리기사실기
- 컴퓨터구조
- 데이터입출력구현
- 중학1-1
- 컴퓨터비전
- 중학수학
- 정보처리기사필기
- 데이터분석
- 자바 실습
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
딥러닝 비전 7 - 다중 퍼셉트론 구현하기 2 : 하이퍼 매개변수 다루기 본문
이번 시간에는 하이퍼 매개변수를 다루는 것과 자연 영상 인식에 대해서 학습해보려고 한다.
3. 하이퍼 매개변수 다루기
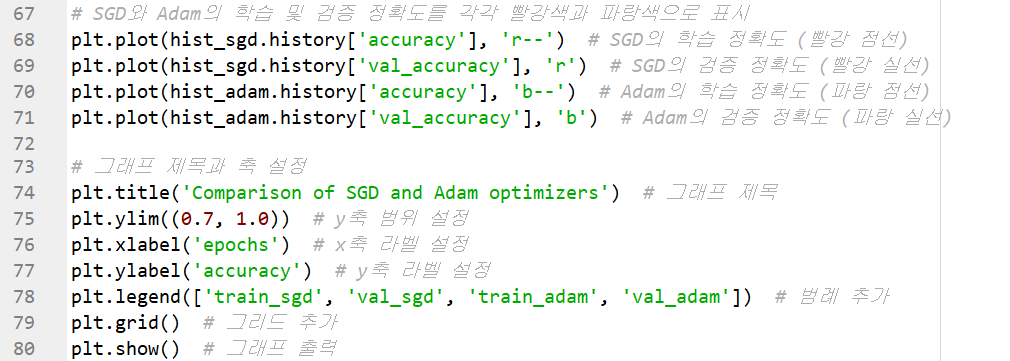
하이퍼 매개변수는 신경망의 구조 또는 학습관 관련하여 사용자가 설정해야 하는 매개변수다 프로그램 7-4는 옵티마이저에 관련된 하이퍼 매개변수늘 SGD(learning_rage=0.01)과 Adam(learnging_rate=0.001)로 다르게 설정하고 어떤 값이 더 좋은지 비교하여 Adam이 월등히 좋다는 것을 알아냈다. 이처럼 하이퍼 매개변수를 잘 설정해야 신경망이 높은 성능을 발휘한다.
하이퍼 매개변수의 최적값을 찾는 일을 하이퍼 매개변수 최적화라 한다.
하이퍼 매개변수 설정 요령
신경망의 하이퍼 매개변수는 생각보다 많다. Dense 클래스에는 노드 개수를 정하는 units, 활성 함수를 정하는 activation이 있고, compile 함수에는 손실 함수를 나타내는 loss, 옵티마이저를 나타내는 optimizer 등이 있다. 책에 나온 설명보다 chatgpt가 설명을 잘 해주어 하이퍼 매개변수 부분은 이 내용을 정리해보기로 했다.
하이퍼 매개변수를 초기화하는 것은 딥러닝 모델의 학습 성능과 효율성에 중요한 역할을 한다. 여기서는 몇 가지 일반적인 하이퍼 매개변수와 초기화 방법을 설명하겠다.
1. 하이퍼 매개변수 설정 예시
일반적으로 설정하는 주요 하이퍼 매개변수는 다음과 같다:
- 학습률 (Learning Rate): 모델이 학습하는 속도를 조정하는 매개변수로, 보통 0.001에서 0.1 사이의 값을 사용
- 배치 크기 (Batch Size): 한 번에 학습에 사용하는 데이터 샘플의 수로, 보통 32, 64, 128 등의 값을 사용
- 에포크 (Epochs): 전체 학습 데이터셋을 몇 번 반복해서 학습할지를 정하며, 보통 10에서 100 사이로 설정
- 최적화 알고리즘: SGD, Adam, RMSprop 등 다양한 최적화 알고리즘 중 하나를 선택하여 초기화
2. 매개변수 초기화 방법
하이퍼 매개변수는 보통 코드의 상단에서 일괄적으로 정의하여 모델을 생성하거나 학습할 때 사용하는데, 예시는 다음과 같다.
# 하이퍼 매개변수 초기화
learning_rate = 0.001 # 학습률
batch_size = 64 # 배치 크기
epochs = 50 # 에포크 수
# 모델 설정 시 하이퍼 매개변수 적용
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), # 최적화 알고리즘 설정
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 모델 학습 시 하이퍼 매개변수 적용
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test))
3. Keras Tuner를 사용한 하이퍼 매개변수 튜닝
Keras Tuner를 사용하여 하이퍼 매개변수를 자동으로 최적화하는 방법도 있다. 이 방법은 여러 매개변수를 테스트해 성능을 최적화할 수 있다.
from kerastuner.tuners import RandomSearch
# 모델 정의 함수
def build_model(hp):
model = Sequential()
model.add(Dense(units=hp.Int('units', min_value=32, max_value=512, step=32), activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(
optimizer=tf.keras.optimizers.Adam(hp.Choice('learning_rate', [0.001, 0.01, 0.1])),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
return model
# 튜너 설정
tuner = RandomSearch(
build_model,
objective='val_accuracy',
max_trials=5,
executions_per_trial=3,
directory='my_dir',
project_name='mnist_tuning'
)
# 튜닝 실행
tuner.search(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
요약
- 기본 초기화: 코드 상단에서 변수로 초기화한 후 모델에 적용
- Keras Tuner 사용: 자동 하이퍼 파라미터 튜닝을 통해 최적의 매개변수를 찾는다.
이 방법을 사용하면 매개변수를 초기화하거나 최적화할 수 있어, 모델 학습에 효과적으로 활용할 수 있다.
깊은 다층 퍼셉트론으로 MNIST 인식
프로그램 7-5는 그림 7-17처럼 은닉층을 깊게 쌓은 깊은 다층 퍼셉트론을 프로그래밍한다.
깊은 다층 퍼셉트론으로 MNIST 인식하기
이 코드는 MNIST 데이터셋을 이용하여 심층 다층 퍼셉트론(Deep Multilayer Perceptron, DMLP) 모델을 학습하고 평가하는 프로그램이다. 학습된 모델을 저장하고, 학습 및 검증 데이터의 정확도와 손실을 그래프로 시각화한다.

코드 요약
- 데이터 로드 및 전처리 : MNIST 데이터를 불러와 1차원으로 펼치고 정규화하며, 레이블을 원-핫 인코딩으로 변환
- DMLP 모델 정의 및 컴파일 : 3개의 은닉층과 출력층으로 구성된 MLP 모델을 정의하고, Adam 최적화와 손실 함수를 설정
- 모델 학습 및 평가 : 학습과 검증 데이터로 모델을 학습시키고, 정확률을 평가
- 모델 저장 및 그래프 시각화 : 학습된 모델을 파일로 저장하고, 학습 및 검증 정확도와 손실 그래프를 시각화
코드 실행하기

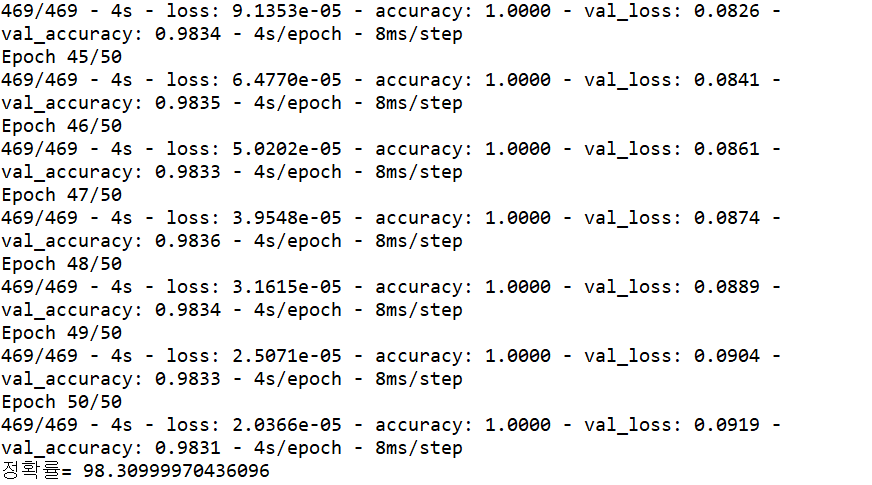


프로그램 실행 결과를 보면 98.3%의 정확률을 기록하고 있다. 다층 퍼셉트론보다 다소 향상되었다.
하이퍼 매개변수 설정 체험

텐서플로는 이 그림처럼 하이퍼 매개변수에 따라 신경망 동작이 어떻게 변하는지 실시간으로 체험할 수 있는 사이트를 제공한다. 빨간색 박스는 신경망 구조와 관련된 하이퍼 매개변수다. 은닉층 개수와 은닉층마다 노드 개수를 조정할수 있다. 파란색 박스는 학습관 관련된 하이퍼 매개변수다. 미니 배치 크기, 세대 수, 학습률, 활성 함수, 규제 종류 등을 조정할 수 있다.
4. 자연 영상 인식
지금까지 사용한 MNIST 데이터셋은 자연 영상에 비해 변화가 훨씬 적다. 아래 그림은 자연 영상에서 장나감 축에 속하는 CIFAR-10과 CIFAR-100 데이터셋을 보여준다. 깊은 다층 퍼셉트론은 CIFAR-10 자연 영상을 인식할 수 있을까? 정확률은 어느 정도일까?

프로그램 7-6은 깊은 다층 퍼셉트론으로 CIFAR-10을 인식한다.
깊은 다층퍼셉트론으로 CIFAR-10 인식하기
이 코드는 CIFAR-10 데이터셋을 사용하여 심층 다층 퍼셉트론(Deep Multilayer Perceptron, DMLP) 모델을 학습하고 평가하는 프로그램이다. CIFAR-10 데이터셋은 10개의 서로 다른 클래스로 분류된 작은 컬러 이미지들로 구성되어 있다. 이 코드에서는 학습된 모델의 정확도와 손실을 시각화하는 그래프를 생성한다.

코드 요약
- 데이터 로드 및 전처리: CIFAR-10 데이터를 불러와 1차원 벡터로 펼치고 정규화하며, 레이블을 원-핫 인코딩으로 변환
- DMLP 모델 정의 및 컴파일: 3개의 은닉층과 출력층으로 구성된 MLP 모델을 정의하고, Adam 최적화와 손실 함수를 설정
- 모델 학습 및 평가: 학습과 검증 데이터로 모델을 학습시키고, 정확률을 평가
- 그래프 시각화: 학습 및 검증 정확도와 손실을 시각화하여 모델 성능을 확인
코드 실행해보기




실행결과를 살펴보자. 55.65% 정확률을 달성했다. 부류가 10개니 무작위로 분류하면 10% 정확률일테니 의미가 없진 않지만 상당히 낮은 성능이다. 정확률 그래프를 보면 훈련 집합은 90%까지 치솟지만 테스트 집합은 55% 근방에서 수렴했다. 손실 함수 그래프를 보면 훈련 집합은 꾸준히 떨어지지만 테스트 집합에 대해서는 20세대 이후에 오히려 증가하여 과잉 적합 현상이 나타났다.
과잉 적합
과잉 적합이란 학습 알고리즘이 훈련 집합에 과다하게 맞추다 보니 일반화 능력을 상실하는 현상을 뜻한다. 일반화란 학습에 사용하지 않은 샘플 집합, 즉 테스트 집합에 대해 높은 성능을 유지하는 능력이다. 프로그램 7-6의 다층 퍼셉트론은 CIFAR-10에서 훈련 집합에 대해 90% 정도 달성했는데, 테스트 집합에 대해서는 55% 가량을 달성하여 35%나 차이가 난 과잉 적합이 발생했다.
과잉 적합은 신경망 모델의 용량이 큰데 데이터셋 크기가 작은 경우에 주로 발생한다. 신경망 모델의 용량은 가중치 개수로 측정할 수 있는데 프로그램 7-6의 신경망에는 (3072 + 1) x 1024 + (1024 + 1) x 512 + (512 + 1) x 10 = 3,939,338개의 가중치가 있다.
그에 비해 CIFAR-10 훈련 집합은 샘플이 50,000개이므로 모델 용렁이 데이터셋보다 훨씬 크다고 말할 수 있다. 딥러닝은 모델의 용량을 충분히 크게 설계하되 과잉 적합을 방지할 다양한 규제 기법을 적용하는 전략을 쓴다. 딥러닝에는 드롭아웃, 데이터 증강, 조기 멈춤, 배치 정규화, 가중치 감쇠 등과 같은 훌륭한 규제 기법이 많이 개발되어 있다.
학습을 마치고
딥러닝은 CPU를 사용하기에 실행하는데 조금 시간이 걸렸지만 그래도 내 컴퓨터 성능이 나름 괜찮은지 연산이 잘 되었다. 보통은 CPU를 사용하지 않고 코랩에서 GPU를 쓰는데 컴퓨터 비전에도 이런 실습이 있을줄 몰랐다. 모두 딥러닝을 공부할 때 했던 내용이라 가볍게 보아도 될 내용이었다.
이렇게 해서 다층 퍼셉트론에 대한 공부를 마쳤다.
'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| 컴퓨터 비전 5 - 플라스크 실습해보기 (0) | 2024.11.14 |
|---|---|
| 딥러닝 비전 8 - [비전 에이전트 5] 우편번호 인식기 v.1 (1) | 2024.11.13 |
| 딥러닝 비전 6 - 다층 퍼셉트론 구현하기 1 : 필기 숫자 인식과 성능 시각화 (0) | 2024.11.13 |
| 딥러닝 비전 5 - 학습 알고리즘 (0) | 2024.11.13 |
| 딥러닝 비전 4 - 깊은 다층 퍼셉트론 (1) | 2024.11.13 |



