
- 분류 전체보기 (1632)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 정보처리기사필기
- 개발일기
- 중학1-1
- JDBC
- 자바 실습
- SQL
- 데이터분석
- 파이썬
- 딥러닝
- rnn
- 컴퓨터비전
- 데이터베이스
- JSP/Servlet
- 중학수학
- c언어
- 디버깅
- 연습문제
- 머신러닝
- 순환신경망
- 상속
- html/css
- 자바스크립트심화
- 정보처리기사실기
- 오블완
- CSS
- 혼공머신
- 컴퓨터구조
- 자바
- 자바스크립트
- JSP
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
컴퓨터 비전 13 - YOLO v8 객체 탐지 2 - YOLO 모델로 객체 탐지하고 속성값 확인하기 본문
저녁을 먹고 이제 다시 공부를 시작해 본다. 오늘은 몸이 무척이나 힘든 날이어서 다른 날보다 속도를 조금 늦추면서 학습을 진행하고 있다. 내일은 컨디션이 좀 나아지길 바라며 이제 나머지 공부를 시작해보려고 한다.
지금 YOLO 모델로 객체 탐지를 하는 실습을 진행 중이다.
YOLO v8 객체 탐지 하기 전 살펴볼 것
조금 전에 코드를 가져왔던 허깅페이스에 보면 밑에 링크가 하나 있다. 거기로 가면 좀 더 많은 정보를 얻을 수 있다.


모델에 들어가면 여러 코드들을 살펴볼 수 있다.

Models에는 YOLO 모델의 버전별로 나와있다.

우리가 사용할 코드는 바로 이것이다.
YOLO 모델로 객체 탐지하기



좌우 반전을 하는 코드를 추가하고 실행하면 이처럼 객체를 탐지해서 보여준다. 그리고 실행 결과를 보면 어떤 객체가 탐지되었는지 알려준다.

핸드폰이라고 탐지한 모습을 찍기 위해 여러 번 카메라 앞에 대어보았다. 어쩔 때는 서류 가방이라고 하고 의자 또는 랩탑이라고 나오기도 했다.
각각의 속성 살펴보기


data 폴더에 들어있는 사진을 탐지해보았다. 조금 전에 객체 탐지 실습 자료로 사용했던 어린이 사진을 탐지해 주었다. 그리고 새로운 사진을 하나 다운 받아서 진행했다. 사람이 4명 있다고 나오고, 위의 사진의 경우 사람 6명에 가방이 2개 있다고 나온다.
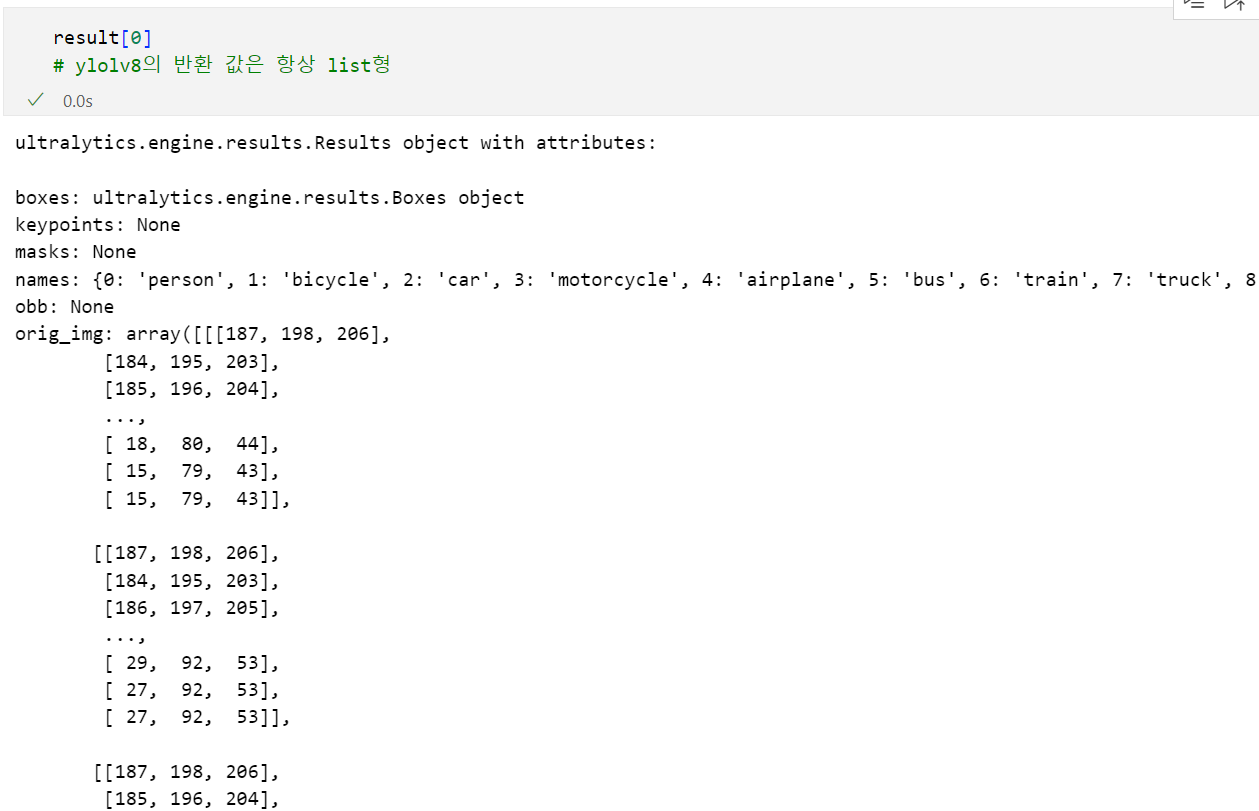
이 출력은 YOLOv8 모델을 사용하여 얻은 results 객체의 속성들을 보여준다. results 객체는 ultralytics 라이브러리의 YOLO 모델이 예측 결과를 반환할 때 사용하는 형식이며, 여기에는 다음과 같은 속성들이 포함되어 있다:
- boxes : Boxes 객체로 탐지된 객체들의 좌표와 클래스에 대한 정보가 포함되어 있다. boxes 속성 안에 각 객체의 위치 및 클래스 정보를 얻을 수 있다.
- names : 클래스 ID와 해당 클래스 이름을 매핑하는 딕셔너리. 예를 들어, {0: 'person', 1: 'bicycle', 2: 'car', ...}와 같이, 각 클래스 ID에 대응하는 객체 이름이 저장되어 있다.
- orig_img : 원본 이미지의 픽셀 데이터로, 예측에 사용된 이미지의 원본 형태이다.
- keypoints, masks, obb 등은 YOLOv8에서 추가적인 정보(키포인트, 마스크 등)를 제공할 때 사용하는 속성이며, 여기서는 None으로 설정되어 있다.
이를 통해 예측 결과로 얻어진 각 객체의 정보를 조회할 수 있으며, boxes 속성을 활용하여 각 객체의 위치와 종류를 확인하고 이미지에 표시할 수 있다.


이렇게 좌표값을 기반으로 객체를 탐지하게 된다. 이 출력은 YOLOv8 모델을 사용하여 이미지에서 탐지된 객체의 정보를 포함하고 있는 Boxes 객체의 속성들을 보여준다. 이 객체는 탐지된 객체들에 대한 다양한 정보를 포함하고 있으며, 각 속성은 다음과 같은 의미를 가진다:
- cls : tensor([0., 0., 0., 0.])와 같은 형태로, 탐지된 객체들의 클래스 ID를 포함한다. 예를 들어, 0은 사람이면, 탐지된 네 개의 객체가 모두 사람으로 분류되었음을 의미한다.
- conf : 객체에 대한 신뢰도 값 (confidence score)이다. 각 값은 해당 객체가 특정 클래스일 확률을 나타내며, 예를 들어 [0.9265, 0.9217, 0.8675, 0.6695]처럼 탐지된 객체 각각에 대해 신뢰도가 표시된다.
- data : 객체의 위치 정보와 클래스 신뢰도를 포함하는 2차원 텐서다. 각 행은 [x1, y1, x2, y2, confidence, class]로 표현되며, (x1, y1)은 좌상단 좌표, (x2, y2)는 우하단 좌표, 그리고 confidence와 class는 각각 신뢰도와 클래스 ID이다.
- xywh : 객체의 바운딩 박스를 중점 (x, y) 좌표와 폭 (width), 높이 (height)로 표현한 텐서이다. 예를 들어, [91.8511, 317.4660, 182.8351, ...] 형태로 객체의 중심 위치와 크기가 표시된다.
- xywhn : xywh를 이미지 크기에 맞춰 정규화한 값이다. 값은 0에서 1 사이의 값으로, 이미지 크기와 관계없이 상대적인 위치와 크기를 나타낸다.
- xyxy : 객체의 좌상단 (x1, y1)와 우하단 (x2, y2) 좌표를 가진 텐서로, 객체의 위치를 나타낸다. 예를 들어, [[4.3359e-01, 2.1101e+02, ...], ...]와 같은 좌표값을 포함한다.
이러한 정보를 이용하면 탐지된 객체의 위치와 크기, 신뢰도 등을 사용하여 객체를 이미지에 표시하거나, 특정 객체에 대한 정보를 활용할 수 있다.

JSON으로 바꿀 때 텐서보다는 array로 하는 것이 더 좋다.

이런 것들을 속성값으로 살펴볼 수 있다. 이제 yolo 모델을 플라스크와 연동해보려고 한다.
학습을 마치고
어제 저녁에 이 학습까지 마치려고 했는데 너무 졸려서 취침하고 다음날 새벽 2시 반에 일어나 나머지 내용을 이어서 학습했다. 취침 전에 영어 공부를 10분 정도 했는데 이 내용은 블로그에 쓸만한 분량은 아니라 조금의 학습을 한 것으로 만족했다. 이제 딱 한 시간 분량의 컴퓨터 비전 공부가 남았는데 이것까지 다 마치고 다음 단계로 넘어갈 수 있을 것 같다.
'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| 컴퓨터 비전 14 - YOLO v8 객체 탐지 3 - 플라스크 연동하여 홈페이지 정보 요청하고 가져오기 (0) | 2024.11.15 |
|---|---|
| 컴퓨터 비전 12 - YOLO v8 객체 탐지 1 : 라이브러리 설치 및 객체 탐지 예측하기 (0) | 2024.11.14 |
| 컴퓨터 비전 11 - 얼굴 탐지(Face Detection) 4 : 얼굴에 블러 효과 적용하기 (0) | 2024.11.14 |
| 컴퓨터 비전 10 - 얼굴 탐지(Face Detection) 3 : 얼굴 탐지 확률 그리기와 자신의 얼굴 탐지하기 (0) | 2024.11.14 |
| 컴퓨터 비전 9 - 얼굴 탐지(Face Detection) 2 : 사람 얼굴 객체 탐지하기 (0) | 2024.11.14 |



