
- 분류 전체보기 (1645)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 순환신경망
- 데이터분석
- 정보처리기사필기
- 중학1-1
- 디버깅
- 파이썬
- 혼공머신
- 머신러닝
- 개발일기
- rnn
- 중학수학
- 정보처리기사실기
- 데이터베이스
- 자바
- 상속
- 딥러닝
- 연습문제
- SQL
- JSP
- JDBC
- 자바스크립트심화
- ChatGPT
- CSS
- JSP/Servlet
- 자바 실습
- 컴퓨터비전
- c언어
- 컴퓨터구조
- 자바스크립트
- html/css
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
순환 신경망(RNN) 11 - 자연어 처리 9 : Seq2Seq 모델로 챗봇 구현 2 <데이터 전처리> 본문
이번에는 Seq2Seq 모델로 데이터 전처리하는 내용을 공부해 보겠다.
Seq2Seq 모델로 챗봇 구현하기 두 번째
데이터 전처리
정규식을 활용해 숫자, 한글을 제거하는 함수를 정의했다. 때에 따라서는 특수문자나 영어가 필요할 수 있으니 활용하고자 하는 데이터 및 해결하려는 문제에 따라 의사결정이 필요하다.

앞서 정의한 clean_sentence 함수를 사용해서, 샘플 문장을 전처리해 보면 한글과 숫자 이외의 모든 문자가 제거되었음을 확인할 수 있다.

먼저 konlpy 라이브러리를 코랩 환경에 설치한다. 코랩은 프로그램과 라이브러리 설치 없이 구글 계정만 있으면 누구나 쉽게 활용할 수 있는 장점이 있다. 하지만 기본적으로 설치된 라이브러리 이외에는 매번 필요한 라이브러리 설치가 필요하다.
특히 한글과 관련된 라이브러리를 더욱 설치가 필수다.


네이버 영화 리뷰 감성 분류 모델에서 활용한 형태소 분석기 중에서 이번에는 Okt를 사용한다.

시퀀스 투 시퀀스 모델을 훈련하기 위해서는 3가지 데이터셋이 필요하다.
- question : 인코더에 입력할 데이터셋(질문 전체)
- answer_input : 디코더에 입력할 데이터셋(답변의 시작), <START> 토큰을 문장 처음에 추가
- answer_output : 디코더에 출력 데이터셋(답변의 끝), <END> 토큰을 문장 마지막에 추가
다음은 texts와 pairs에 들어 있는 문장을 입력받아서 question, answer_input, answer_output으로 정리하는 내용이다.


앞에서 구분한 세 가지 데이터를 하나의 리스트로 병합한다.

토크나이저를 활용하기 위해 필요한 라이브러리와 함수를 불러온다.

토크나이저로 단어 사전을 만든다. 사전에 없는 단어는 <OOV>로 표현한다. lower 매개변수는 텍스트를 소문자로 변환할지 결정한다.
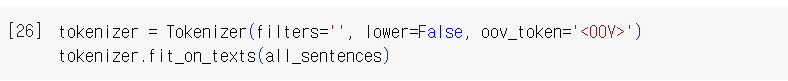
단어 사전(토큰)의 샘플을 출력해서 확인한다.

단어 사전(토큰)의 개수는 3604개로 확인된다.

텍스트 전처리 작업을 진행한다. 먼저 토큰(단어)을 단어 사전에 따라 숫자로 변경(인코딩)하고 문장의 길이를 30으로 맞춘다.

학습을 마치고
데이터 전처리에 관한 실습을 진행해 보았다. 글자를 이렇게 분리할 수 있다니 신기했다. 좀 더 공부하면 나중에는 챗봇 모델도 만들 수 있고 정말 많은 일들을 할 수 있을 것 같다.
힘들지만 공부를 계속 이어가며 오늘은 꼭 RNN 공부를 마칠 것이다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 순환 신경망(RNN) 13 - 자연어 처리 11 : 어텐션 (0) | 2024.12.19 |
|---|---|
| 순환 신경망(RNN) 12 - 자연어 처리 10 : Seq2Seq 모델로 챗봇 구현 3 <모델 학습과 예측> (0) | 2024.12.19 |
| 순환 신경망(RNN) 10 - 자연어 처리 8 : Seq2Seq 모델로 챗봇 구현 1 <챗봇 데이터 소개 및 탐색적 데이터 분석> (0) | 2024.12.19 |
| 순환 신경망(RNN) 9 - 자연어 처리 7 : 자연어 생성 (0) | 2024.12.19 |
| 순환 신경망(RNN) 8 - 자연어 처리 6 : 한국어 감성 분석 5 <KoBERT 토그나이저> (0) | 2024.12.19 |



