
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 타입스크립트심화
- 정보처리기사필기
- 상속
- 연습문제
- html/css
- 정보처리기사실기
- 스프링
- JDBC
- 자바스크립트심화
- 중학1-1
- JSP
- 파이썬
- 컴퓨터비전
- 자바 실습
- 디버깅
- JSP/Servlet
- 머신러닝
- 쇼핑몰홈페이지제작
- 중학수학
- 스프링프레임워크
- ChatGPT
- 자바
- 데이터베이스
- rnn
- 딥러닝
- SQL
- 혼공머신
- 개발일기
- 데이터분석
- 자바스크립트
- Today
- Total
"게임 개발자"를 향한 매일의 공부일지 _ 1기
순환 신경망(RNN) 15 - ViT 본문
마지막 단원이다. 정말 재미없는 공부를 이처럼 다 끝내다니 스스로가 대견스럽다. 마지막 공부를 이어가볼 것이다. 그리고 조금 쉬어야지.
ViT
ViT(Vision Transformer)는 컴퓨터 비전 분야에서 트랜스포머를 적용하는 개념이다. 즉, 자연어 처리에서 RNN을 물리치고 왕좌에 오른 트랜스포머를 이미지에도 적용하려는 아이디어를 구현한 것이다. 2020년에 발표된 논문을 바탕으로 간단하게 재구성해서 적용한다.

이미지를 여러 개의 패치(patch) 단위로 나누고, 순서대로 포지션에 대한 인코딩한 값을 더하여 트랜스포머에 넣어서 결과를 예측하는 개념이다. 다음과 같이 간단한 코드로 구현해보자.
CIFAR-10 데이터를 사용한다. 이미지 크기는 (32, 32, 3)이고, 패치의 크기를 4 픽셀로 정하기로 한다. 가로, 세로 각각 4 픽셀로 나누면 8개로 구분이 되고, 전체 이미지는 64조각(패치)이 된다. 각 패치는 (4, 4, 3) 형태를 갖는다.
다음과 같이 패키지를 불러 오고, 주요 파라미터 값들을 설정한다.

텐서플로 케라스 데이터셋에서 CIFAR-10 데이터를 가져와서 훈련 셋과 검증 셋으로 구분한다. 훈련 셋의 이미지는 50,000장이다. 각 이미지는 64개 패치로 분할되는데 개별 패치의 위치 인덱스를 0~63 범위 값으로 지정하고, position_input 변수에 넘파이 배열로 저장한다.
케라스 함수형 API를 활용하여 모델 구조를 정의한다. 원본 이미지와 각 이미지를 구성하는 64개 패치의 위치 인덱스를 입력받는다. 분할된 각 패치는 reshape 함수를 사용하여 크기가 48인 1차원 배열로 펼쳐준다. 다시 트랜스포머의 입력 형태인 크기 32로 줄인다.
채널이 1인 위치 인덱스 배열로 Embedding 레이어를 거쳐서 32로 늘린다. 패치 배열과 인덱스 배열을 더해서 트랜스포머의 입력으로 사용한다. 트랜스포머를 거쳐서 나온 출력을 다시 완전연결층을 거쳐서 최종 분류한다.


위 오류의 원인은 tf.image.extract_patches가 Keras의 Functional API 텐서를 입력으로 받을 수 없기 때문이다. 이 함수는 NumPy 배열이나 일반 텐서를 입력으로 받을 수는 있지만, Keras의 Functional 텐서는 사용할 수 없다.
이 문제를 해결하려면 tf.image.extract_patches를 사용하기 전에 입력 데이터를 명시적으로 변환하는 작업이 필요하다.










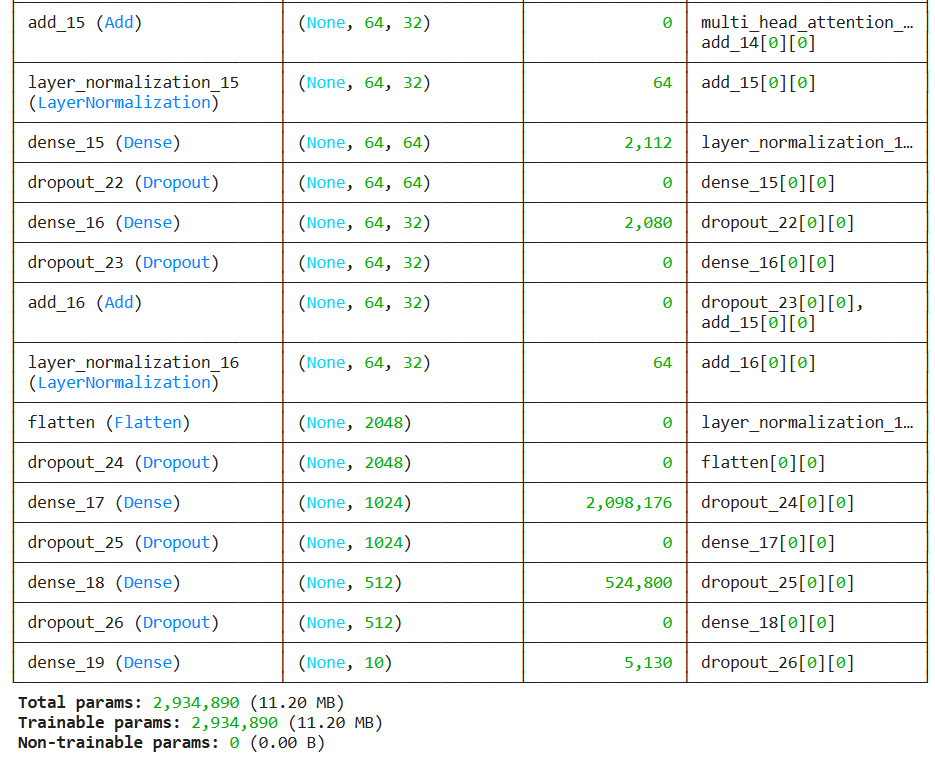
모델 구조를 출력해본다.


원본 이미지가 64개 파치로 분할되는 것을 보여주기 위한 모델을 추가적으로 생성한다. 이 모델은 앞에서 생성한 ViT 모델의 입력 이미지를 64개 패치로 구분된 이미지로 출력한다.

원본 이미지를 시각화아면 다음과 같은 개구리 사진을 알 수 있다.

앞의 개구리 이미지를 64개 패치로 분할하면 다음과 같이 나뉜다.

다중 분류 문제에 맞도록 옵티마이저, 손실함수, 평가지표를 설정하고 모둘을 훈련시킨다. 평가 지표에 사용한 top-5-accuracy는 모델의 예측값 기준으로 상위 5개 클래스에 해당하는지 알려준다.


학습을 마치고
드디어 순환신경망 공부를 마칠 수 있게 되었다. 마지막 실습은 좀 오래 걸리기는 했지만 기다리는 동안 다른 일도 하며 시간을 보낼 수 있어서 좋았다.
이제 언어지능 즉 순환신경망을 어떻게 만들고 훈련하고 결과를 도출하는지 어느 정도 알게 되었다. 12월까지는 하기 싫어도 내가 하던 공부를 마무리할 생각이다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 순환 신경망(RNN) 14 - 트랜스포머 (0) | 2024.12.19 |
|---|---|
| 순환 신경망(RNN) 13 - 자연어 처리 11 : 어텐션 (0) | 2024.12.19 |
| 순환 신경망(RNN) 12 - 자연어 처리 10 : Seq2Seq 모델로 챗봇 구현 3 <모델 학습과 예측> (0) | 2024.12.19 |
| 순환 신경망(RNN) 11 - 자연어 처리 9 : Seq2Seq 모델로 챗봇 구현 2 <데이터 전처리> (0) | 2024.12.19 |
| 순환 신경망(RNN) 10 - 자연어 처리 8 : Seq2Seq 모델로 챗봇 구현 1 <챗봇 데이터 소개 및 탐색적 데이터 분석> (0) | 2024.12.19 |



