
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 스프링프레임워크
- JDBC
- JSP/Servlet
- 머신러닝
- 쇼핑몰홈페이지제작
- ChatGPT
- 자바 실습
- 디버깅
- 정보처리기사필기
- 깃
- 개발일기
- 혼공머신
- 타입스크립트심화
- 파이썬
- 연습문제
- html/css
- 컴퓨터비전
- rnn
- 스프링
- 자바스크립트
- 자바
- 상속
- JSP
- 데이터분석
- SQL
- 정보처리기사실기
- 데이터베이스
- 자바스크립트심화
- 순환신경망
- 딥러닝
- Today
- Total
"게임 개발자"를 향한 매일의 공부일지 _ 1기
데이터베이스 - 오라클 데이터베이스 시작하기 본문
이제 본격적으로 데이터베이스 입문 과정을 시작해 본다. 다음 주 월요일에 데이터베이스 수업이 끝나니 가능하면 빨리 이 과정을 학습해 볼 계획이다. 열흘 안에 다 마치고 HTML/CSS 공부도 시작해야 한다. 어제 수업을 들어보니 많이 어렵지는 않았고 공부를 하면 충분히 따라잡을 수 있을 것 같았다.
게임 개발 수업을 들을 때 어떤 강사님께서 알고리즘과 데이터베이스, 컴퓨터 구조 등의 공부를 나중에 하는 게 좋다고 하셨는데 이렇게 지금 해볼 수 있어서 정말 감사하다.
오라클도 설치해야 하고 할 게 많지만 차근차근 따라해보면 분명 다음 주 월요일에 수업은 한결 수월해질 거라 믿는다.
시작하기 전에
데이터베이스 기초가 탄탄한 사람만이 실무에서 데이터베이스를 설계하고 관리할 때 높은 업무 효율을 낼 수 있다고 한다.
우선 출판사 홈페이지에서 자료를 다운 받았고, 저자의 깃허브도 들어가 보았다. 첫째 마당에서는 데이터베이스 개념을 잡고, 둘째 마당에서부터 본격적인 실무 교육이 들어간다. 오늘의 목표는 SELECT와 WHERE절까지 학습을 마치는 것이다.
오라클 데이터베이스를 사용하기 전에 데이터베이스 기본 내용을 먼저 살펴보기로 하자. 오라클 데이터베이스는 미국 오라클 사의 객체 관계형 데이터베이스 관리 시스템으로서 세계에서 가장 많이 사용되고 있는 데이터베이스 관리 시스템이다.
1. 데이터와 데이터베이스, DBMS
데이터베이스는 데이터(Data)와 베이스(Base)의 합성어이며, DBMS는 Database Management System의 약자로 '데이터베이스 관리 시스템'을 의미한다.
1. 데이터와 정보
데이터는 자료와 정보라는 두 가지 의미가 있다. 그러나 데이터베이스 분야에서 데이버와 정보는 다른 의미로 해석한다. 흔히 데이터를 원석, 정보를 보석으로 비유한다.
데이터와 정보의 차이
데이터 : 어떤 필요에 의해 수집했지만 아직 특정 목적을 위해 평가하거나 정제하지 않은 값이나 사실 또는 자료 자체
- A 카드사에서 발급한 카드를 사용한 커피 전문점 결제 내역
정보 : 수집한 데이터를 어떤 목적을 위해 분석하거나 가공하여 가치를 추구하거나 새로운 의미를 이끌어낼 수 있는 결과
- 커피 전문점 결제 분포의 최상위 순위를 30~40대 남성이 차지했다는 결과

2. 데이터 분석이 필요한 이유
여러 가지 방법으로 수집한 데이터는 분석을 위한 통합 작업만으로도 시간과 비용이 많이 든다. 데이터가 여기저기 흩어져 있다면 최신 데이터를 정확하게 찾아내는 게 쉽지 않다.
만약 데이터가 누락되거나 중복된다면 정확한 분석을 기대할 수 없고 결국 비싼 비용과 많은 시간을 투자한 분석이 실패하게 된다. 따라서 가치 있는 정보를 얻으려면 다음 조건에 맞게 데이터를 효율적으로 수집 · 통합하고 체계적으로 관리 · 분석해야 한다.
효율적인 데이터 관리를 위한 조건
- 데이터를 통합하여 관리
- 일관된 방법으로 관리
- 데이터 누락 및 중복 제거
- 여러 사용자(응용 프로그램 포함)가 공동으로 실시간 사용 가능
데이터베이스란 무엇인가?
위 조건을 만족하면서 특정 목적을 위해 여러 사람이 공유하여 사용할 수 있으며, 효율적인 관리과 검색을 위해 구조화한 데이터 집합
3. 파일 시스템과 DBMS
데이터베이스 개념이 등장하기 전에는 주로 파일 시스템 방식을 사용하여 데이터를 관리하였다.
파일 시스템을 통한 데이터 관리
파일 시스템은 서로 다른 여러 응용 프로그램이 제공하는 기능에 맞게 필요한 데이터를 각각 저장하고 관리한다. 따라서 각 파일에 저장한 데이터는 서로 연관이 없고 중복 또는 누락이 발생할 수 있다.

다음 예를 통해 파일 시스템 방식으로 응용 프로그램들이 각자 데이터를 관리하면 어떤 문제점이 발생하는지 살펴보자. 이떤 대학에 학사 프로그램과 장학금 신청 프로그램이 있다고 가정하자. 이 두 프로그램은 학생의 졸업 여부에 관련된 데이터를 각 파일에 저장하고 있다.
만약 이수선 학생이 학사 프로그램에는 졸업생으로 등록되어 있지만 장학금 신청 프로그램에서는 졸업했다는 내용이 누락되어 있다면, 실제로는 졸업생으로 분류된 학생도 장학금을 신청할 수 있는 상황이 발생할 수 있다.

이러한 현상은 학생의 재학 상태를 관리하는 데이터가 각 응용 프로그램별로 흩어져 있기 때문에 발생한다. 따라서 학생과 관련된 일련의 데이터를 한 곳에 모아 관리하고, 이렇게 한 곳에 모아둔 데이터를 각각의 응용프로그램이 함께 사용해야 한다. 그럴 때 직접 관리할 때 발생할 수 있는 데이터의 오류, 누락, 중복 등의 문제를 해결할 수 있다.
이렇게 여러 응용 프로그램이 사용할 데이터를 한곳에서 관리하기 위해 데이터베이스를 활용한다.
서비스 역할 분담
시간이 흐름에 따라 점점 거대해지고 복잡해지는 데이터를 각각의 응용 프로그램이 직접 관리한다면 데이터 관리에 소모되는 시간과 자원 또한 점점 증가하게 된다. 또 각 데이터 간의 불일치로 인한 오류 발생 확률도 높아진다. 이는 본래 의도한 기능, 즉 특정 서비스를 제공하는 효율과 질을 떨어뜨리는 원인이 된다.
이러한 문제를 방지하기 위해서는 하나의 서비를 처리하는데 역할 분담이 필요하다. 서비스를 요청받는 영역, 서비스 처리에 필요한 데이터를 다루는 영역, 처리한 데이터를 제공한 영역으로 나누는 것이다.
DBMS를 통한 데이터 관리
효율적인 디에터 관리 조건을 만족하며 서비스 제공의 효율성을 높이기 위해 데이터베이스 관리 시스템이 등장했다. 데이터베이스 관리 시스템은 데이터베이스의 데이터 조작과 관리를 극대화한 시스템 소프트웨어이다.
이를 DBMS라고 만이 부르며, 실무에서는 데이터베이스와 데이터베이스 관리 시스템을 따로 구별하지 않고 DB 또는 데이터베이스라고 부른다.
데이터베이스를 통한 데이터 관리란 여러 목적으로 사용할 데이터의 접근 · 관리 등의 업무를 DBMS가 전담하는 방식을 말한다. 다시 말해 응용 프로그램이 필요한 데이터 작업을 DBMS에 요청하면, DBMS는 자신이 관리하는 데이터베이스로 관련 작업을 수행하고 결과값을 제공한다.

이러한 작업 영역의 분리는 응용 프로그램의 서비스 제공과 데이터 관련 작업 효율을 높인다. 또한 여러 응용 프로그램이 하나의 통합된 데이터를 같은 방식으로 사용 · 관리할 수 있으므로 데이터 누락이나 중복을 방지할 수 있다.
DBMS는 다음 표와 같이 파일 시스템 기반 방식의 문제를 해결하면서 데이터 관리의 패러다임을 바꾸었다.

2. 데이터 모델
데이터 모델이란 컴퓨터에 데이터를 저장하는 방식을 정의해놓은 개념 모델이다. 대표적인 데이터 모델에는 계층형, 네트워크형, 관계형, 객체 지향형 등이 있다.
1. 계층형 데이터 모델과 네트워크형 데이터 모델
이 모델은 1960년대 말부터 1980년대 말까지 상업용 데이터베이스 시장에서 많이 사용한 데이터 모델이다.
계층형 데이터 모델
나뭇가지 형태의 트리 구조를 활용하뎌 데이터 관련성을 계층별로 나누어 부모 자식 같은 관계를 정의하고 데이터를 관리한다. 계층형 데이터 모델을 이해하기 위해서는 일대다(1:N) 관계의 데이터 구조를 파악해야 한다.
기본적으로 하나의 부모 개체가 여러 자식을 가질 수 있는 반면, 자식 개체는 여러 부모 개체를 가질 수 없다는 제약이 있다.
따라서 일대다 구조의 데이터를 표현하기에는 알맞지만, 자식 개체가 여러 부모를 가진 관계는 표현할 수 없다.

네트워크형 데이터 모델
네트워크형 데이터 모델은 망형 데이터 모델이라고도 하며 그래프 구조를 기반으로 한다. 개체 간 관계를 그래프 구조로 연결하므로 자식 개체가 여러 부모 개체를 가질 수 있다는 점에서 계층형 데이터 모델과 차이가 있다.

2. 객체 지향형 데이터 모델
1980년대 후반에 등장한 모델로 객체 지향 프로그래밍에서 사용하는 객체 개념을 기반으로 한 데이터 모델이다. 그리고 객체 지향 프로그래밍처럼 데이터를 독립된 객체로 구성하고 관리하며 상속, 오버라이드 등 객체 지향 프로그래밍에 사용되는 강력한 기능을 활할 수 있다.
하지만 이러한 객체 지향형 모델 개념을 완전히 데이터베이스에 적용하는 것은 쉽지 않기 때문에 이를 적용한 상용 DBMS는 많지 않다. 다만 오라클 데이터베이스와 같은 여러 DBMS 제품군이 관계형 데이터 모델을 바탕으로 객체 개념을 도입하여 '객체 관계형 DBMS'로 영역을 확장하고 있다.

관계형 데이터 모델
1970년 에드거 프랭크 커드가 제안한 모델로서 현재 가장 많이 사용하는 관계형 데이터베이스의 바탕이 되는 모델이다. 관계형 데이터 모델은 다른 모델과 달리 데이터 간 관계에 초점을 둔다.
예를 들어 회사의 사원 정보와 사원이 소속된 부서 정보를 데이터로 관리할 경우, 사원 정보와 부서 정보를 하나의 묶음으로 관리하면 데이터 구조가 간단해진다. 하지만 같은 부서 사원들은 부서 정보가 중복되므로 효율적인 관리가 어려워진다.

왜냐하면 부서 이름이 바뀌면 해당 부서 사원들의 부서 정보를 일일이 찾아서 모두 변경해 주어야 하기 때문이다. 따라서 관계형 데이터 모델에서는 각 데이터의 독립 특성만을 규정하여 데이터 묶음을 나눈다. 그리고 중복이 발생할 수 있는 데이터는 별개의 렐레이션(relation)으로 정의한다. 사원 정보에 소속된 부서를 식별하는 '부서 코드'를 포함하여 사원 정보 데이터와 부서 정보 데이터를 연결하는 것이다.

관계형 데이터 모델에서는 이렇게 데이터를 일정 기준으로 나누어 관리한다. 이를 위해 다양한 개념과 여러 구성 요소가 존재한다.

3. 관계형 데이터베이스와 SQL
1. 관계형 데이터베이스란?
관계형 데이터베이스는 관계형 데이터 모델 개념을 바탕으로 데이터를 저장 · 관리하는 데이터베이스를 의미한다. 관계형 데이터베이스를 관리하는 시스템은 DBMS에 데이터 간의 관계를 강조하기 위한 'relation'을 앞에 붙여 RDBMS, 즉 관계형 데이터베이스 관리 시스템이라고 부른다.
RDBMS는 1980년 후반부터 지금까지 가장 많이 사용하는 데이터베이스이다.
실무에서는 보통 오라클 데이터베이스와 같은 RDMS를 가리켜 '디비' 또는 '데이터베이스'라고 부른다.
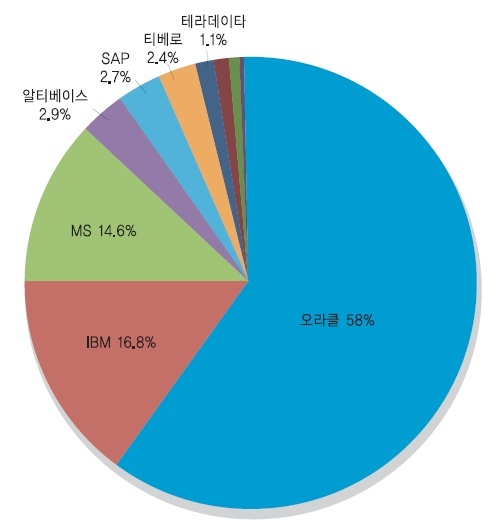
이 자료를 보면 오라클이 압도적으로 높음을 알 수 있다.
2. SQL이란?
SQL은 Structured Query Language의 약자로서 'SQL' 또는 '시퀄'이라고 부른다. SQL은 RDBMS에서 데이터를 다루고 관리하는 데 사용하는 데이터베이스 질의 언어이다. 지금은 SQL의 정의를 'RDBMS에게 데이터에 관해 물어보고 결과를 얻는다' 정도로 기억하면 된다.
SQL은 사용 목적에 따라서 다음과 같이 나뉜다.

SQL에 대하여
1970년대 IBM에서 도널드 D. 챔벌린과 레이먼드 F.보이스가 SEQUEL(Stuctured English Query Language)라는 이름으로 개발한 DBMS 관리 언어이다.
학습을 마치고
처음 데이터베이스를 공부하는 거라 좀 많이 헤맸고 머릿속에 잘 들어오지 않아 시간도 많이 걸렸다. 학습 일정을 너무 빡빡하게 계획한 것 같아 조금 수정해야 할 것 같다.
한 Chapter당 최소 1시간 반은 걸리는 듯하다. 근데 속도가 더딘 건 영타를 너무 못치기 때문이다. 이제 영어로 쓸 일도 정말 많은데, 주말에 타자연습을 시작해야 할 것 같다. 세벌식 타자 연습도 다시 해볼(20년 전에 세벌식으로 바꿀 때 해보고 그 이후로 한 번도 하지 않은 데다 키보드에 자판도 없어서 다 외워서 하니 많이 헷갈린다) 생각이다.
이제 데이터베이스가 무엇인지 조금 알 것 같다. 아직 오라클 설치는 하지 않고 다음 장에서 관계형 데이터베이스와 오라클 데이터베이스에 대해서 공부해보기로 하자.
'알고리즘 및 자료 관리 > 데이터베이스' 카테고리의 다른 글
| 오라클 데이터베이스와 도구 프로그램 설치 3 - 오라클 데이터베이스 처음 사용해보기 (0) | 2024.08.21 |
|---|---|
| 오라클 데이터베이스와 도구 프로그램 설치 2 - 오라클 데이터베이스 설치 및 첫 접속 (0) | 2024.08.21 |
| 오라클 데이터베이스와 도구 프로그램 설치 1 - 오라클 데이터베이스 설치하기 (0) | 2024.08.21 |
| 데이터베이스 기본 1 - 데이터 모델링과 논리적 모델링 (0) | 2024.08.21 |
| 관계형 데이터베이스와 오라클 데이터베이스 - 데이터베이스 구성 요소와 자료형 (0) | 2024.08.21 |



