
- 분류 전체보기 (1694)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 정보처리기사필기
- 연습문제
- 자바
- 딥러닝
- 자바 실습
- JSP
- 중학1-1
- JSP/Servlet
- 순환신경망
- 머신러닝
- 자바스크립트심화
- JDBC
- 데이터베이스
- 데이터분석
- 컴퓨터구조
- 파이썬
- SQL
- 중학수학
- 자바스크립트
- html/css
- 디버깅
- 정보처리기사실기
- CSS
- c언어
- 혼공머신
- ChatGPT
- 상속
- 개발일기
- rnn
- 컴퓨터비전
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
머신러닝 3 - 다중선형 회귀 모델과 평균 오차 제곱을 구하는 방법에 대하여 본문
이어서 다중 회귀 모델에 대해서 학습해보려고 한다.
1. 다중 선형 회귀 모델 실습해보기
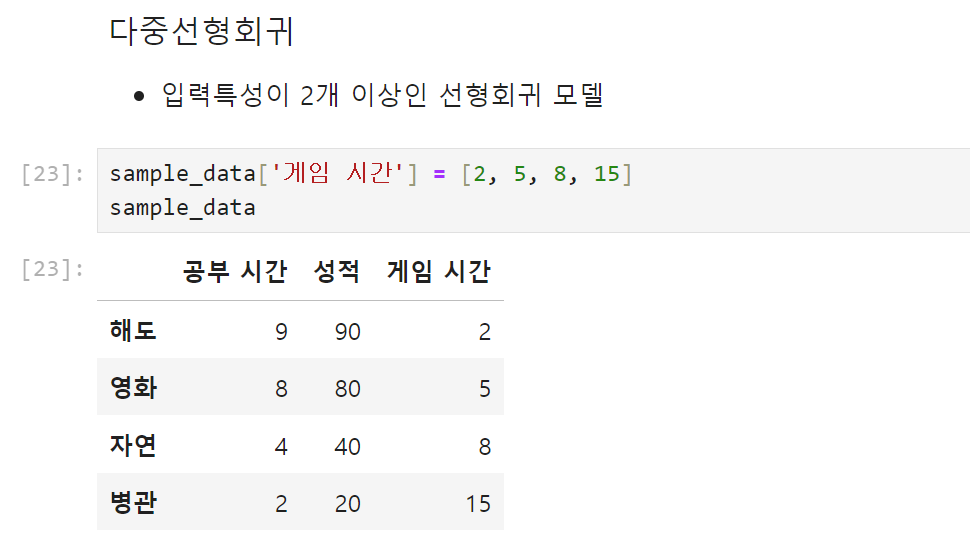
입력 특성에 게임 시간 하나를 추가해보았다.

두 개 이상의 컬럼을 꺼낼 때는 리스트로 묶어서 꺼내면 된다.
다중 선형 회귀 모델링하기


학습할 때는 fit, 예측할 때는 predict라는 단어를 많이 사용한다. 이제 선형 회귀 모델이 어떤 원리에 따라 학습을 하는지 좀더 깊이있는 학습을 해볼 것이다.

공부 시간과 성적을 세 개의 모델이 학습한 결과를 나타내고 있다. 이 중에서 현재의 데이터를 가장 잘 반영하고 있는 그래프는 몇 번 그림일까? 3번이다. 1, 2번은 데이터의 패턴을 잘 파악하지 못하고 있다.
선형 회귀 모델에서 모델이 학습을 잘 하고 있는지 그렇지 않은지 알 수 있는 방법이 존재한다. 실제 연산은 수치화하기 때문에 연산이 잘 맞는지 숫자값으로 추적할 수 있어야 한다.
2. 평균 제곱 오차 계산하는 방법

그래프를 숫자값으로 연산하는 방법은 평균제곱 오차를 사용한다. 현재 구성된 직선이 데이터를 잘 설명하고 있는지를 파악한다. 오차의 제곱값의 평균을 낸다는 뜻이다.
오차란 무엇일까?

외부 요인이 많이 때문에 데이터에 대한 오차가 발생한다. 실제 데이터 값과 예측값 사이의 간격을 오차라고 한다. 이 오차가 적을수록 예측 가설이 잘 성립한다고 볼 수 있다. 여기서 오차를 제곱해서 평균을 내는데 그 이유가 있다.
- 양수와 음수의 오차가 상쇄되는 것을 방지해준다
오차값은 예측값과 실제값의 차이에 따라 양수가 나오기도 음수가 나오기도 한다. 예측값이 실제값보다 작으면 음수가 나온다. 오차를 모두 더하면 상쇄되어 제대로된 판단을 내리기 어렵다.
2. 제곱을 하면 수가 매우 커지므로 모델의 안정성을 확보하는 근거 자료가 된다.
제곱은 원래 숫자보다 훨씬 더 극대화되어 계산되는 효과가 있다. 오차를 제곱하면 오차를 확대 해석하는 효과를 주는 것이다. 오차를 확대 해석하면 어떤 효과가 있을까? A 모델은 오차가 1, 1, 7, 1이 나왔고 B 모델은 2, 2, 3, 3이라고 할 때 어떤 모델이 오차값이 더 크게 나올까?
A 모델은 예측을 잘 하다가 한번씩 튈 때가 있고, B는 예측의 수준이 조금 부정확하기는 하지만 안정적인 예측을 할 수 있다. 만약 생명과 직결된 모델이 있을 때 우리가 쓰기에 적합한 모델은 B이다. 성능이 떨어지더라도 안정적인 모델이 더 적합하기 때문이다. 이때 오차에 제곱을 하면 하나라도 예측을 잘못 했을 때 예측값이 크게 떨어져 패널티를 강력하게 주는 효과가 있다. 그렇지 않으면 두 모델이 비슷하다는 판단을 내릴 가능성이 크다.

평균 제곱 오차를 비용 함수라고 한다. 학습 알고리즘이 제대로 동작하는지 판단하는 근거로서 활용되는 것을 비용 함수라고 부른다. 또는 loss function 손실 함수라고 부르기도 한다.
모든 모델에는 이런 손실 함수가 존재한다.
평균제곱 오차를 구하는 공식

H(x)는 가설값인데, 가설과 실제값의 차이를 구해 제곱하고 총합을 구한 다음 계수로 나눈다. 이제 이 공식을 사용해서 실제로 값을 구하는 실습을 진행해보기로 하자.
3. 평균제곱 오차 직접 계산해보기

3개의 샘플 데이터에서 두 개의 선형회귀 모델이 나오고 있다. 파란색과 빨간색의 평균 제곱 오차를 계산해보면 파란색이 훨씬 작게 나와야 정상이다. 즉 오차의 평균이 적다는 의미이다.

파란색은 예측값과 실제값이 같기 때문에 평균제곱오차가 0이 나왔다. 빨간색은 이렇게 1.16이 나왔음을 볼 수 있다.
학습을 마치고
평균제곱 오차를 구하는 실습은 분량이 많은 관계로 다음 포스트에서 이어서 학습하기로 했다. 선생님이 설명을 정말 자세히 해주셔서 이해도 잘 되고 선형 회귀 모델에 대해 더 알고 싶어지는 마음도 생겼다. 한 달 전의 수업인데 그때는 머신러닝에 대해 전혀 관심이 없어서 공부할 마음이 없었다.
하지만 어떤 공부든 자신이 하고 싶을 때 해야 능률이 오른다는 것을 이번에 확실히 느꼈다. 내가 해야 할 공부라면 필요한 공부라면 그것을 재미있게 만드는 것도 능력이다. 이제는 아무리 지루하고 힘든 공부도 이겨낼 수 있겠다는 믿음이 생겼다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 5 - 주택 가격 예측 선형회귀 모델 실습 1 : 문제 정의에서 데이터 전처리 및 탐색까지 (0) | 2024.09.17 |
|---|---|
| 머신러닝 4 - 평균제곱 오차를 구하는 실습해보기 (0) | 2024.09.16 |
| 머신러닝 2 - 선형 회귀 모델 개념 및 모델링 사용 방법 익혀보기 (0) | 2024.09.16 |
| 머신러닝 1 - 머신러닝 복습하기 (1) | 2024.09.16 |
| 머신러닝과 데이터 과학 이해하기 4 - 실습 문제 풀어보기 (0) | 2024.09.16 |



