
- 분류 전체보기 (1265)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- CSS
- SQL
- numpy/pandas
- pandas
- C++
- 딥러닝
- 파이썬라이브러리
- 데이터베이스
- 혼공머신
- 중학수학
- 컴퓨터비전
- JSP/Servlet
- 운영체제
- 텍스트마이닝
- 자바 실습
- 영어공부
- 연습문제
- 정보처리기사필기
- 정보처리기사실기
- 코딩테스트
- 컴퓨터구조
- 데이터입출력구현
- 중학1-1
- 자바
- 파이썬
- html/css
- 정수와유리수
- CNN
- 데이터분석
- 머신러닝
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
[AICON] Global AI 컨퍼런스 2024 마지막 날 3 - AI 윤리 1 : 데이터 윤리와 법 본문
[AICON] Global AI 컨퍼런스 2024 마지막 날 3 - AI 윤리 1 : 데이터 윤리와 법
huenuri 2024. 11. 16. 07:40AI 윤리 세션에 대한 강의를 2개 정도 선택해서 기록해보려고 한다. 미래 포럼 세션은 정리할만한 중요한 내용이 없어서 건너뛰고 이것만 정리하면 될 것 같다.
아무쪼록 빨리 컨퍼런스 기록을 다 끝내고 공부에 들어가고 싶다.
AI 윤리 1 - 데이터 윤리와 법

이번 강의를 하신 분은 법학박사이신데 데이터 윤리와 법에 대해 매우 자세하게 설명해 주셨다. PPT 자료만 봐도 이해가 될 정도로 내용은 어렵지 않았다.



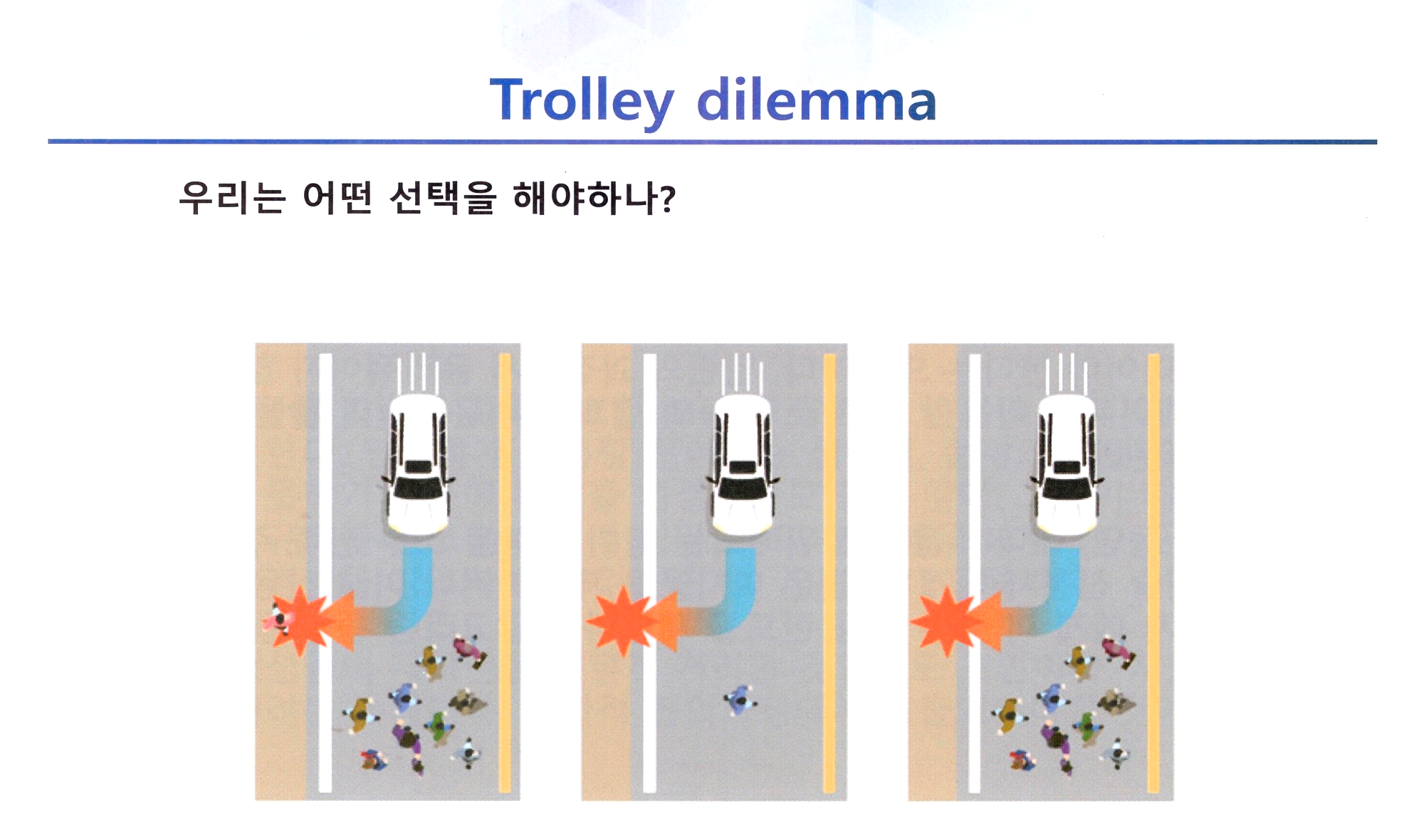
이 슬라이드는 트롤리 딜레마(Trolley Dilemma)라는 윤리적 문제를 자율주행차 상황에 적용하여, 자율주행 시스템이 사고 상황에서 어떤 선택을 해야 할지 고민하도록 제시하고 있다.
설명
트롤리 딜레마는 어떤 사고 상황에서 특정 그룹을 구하거나 다른 그룹을 희생해야 하는 상황을 통해 윤리적 선택을 요구하는 사고 실험이다. 이 이미지에서는 자율주행 차량이 다음 세 가지 선택지 중 하나를 선택해야 하는 상황을 보여준다.
- 왼쪽 : 차량이 왼쪽으로 회피하여, 한 명을 희생하고 다수의 인원을 보호하는 선택
- 중간 : 차량이 현재 경로를 유지하면서 앞에 있는 한 명을 피하지 않고 충돌하는 선택
- 오른쪽 : 차량이 오른쪽으로 회피하여 다수를 희생하고 한 명을 보호하는 선택
질문
슬라이드의 질문은 "우리는 어떤 선택을 해야 하나?"로, 이는 자율주행차가 실제로 사고 상황에서 어떤 윤리적 기준을 바탕으로 행동해야 할지를 묻고 있다.
논의 포인트
- 자율주행차는 사고가 불가피할 때 윤리적 판단을 내려야 하는가?
- 인간의 생명을 수치화하여 계산하는 것이 과연 타당한가?
- 각국의 윤리적 기준에 따라 자율주행 시스템이 다른 행동을 하도록 프로그램되어야 하는가?
이와 같은 질문은 자율주행차의 윤리적 프로그래밍에 대한 논쟁을 불러일으키며, 이는 앞으로 자율주행 기술 발전과 관련한 중요한 문제로 부각되고 있다.

주요 내용
- 윤리적 책임
- 기계학습이나 데이터 분석을 위해 데이터를 수집할 때, 윤리적이지 않은 방식으로 데이터를 확보하거나 사용하는 경우, 해당 행위에 대한 비윤리적 책임과 법적 책임에서 자유로울 수 없음을 강조하고 있다.
- 인터넷에 공개된 데이터의 제한
- 인터넷에 공개된 데이터라 하더라도 저작권이 있거나 개인 정보와 관련된 경우가 많아, 이를 무단으로 사용하는 것은 법적 문제가 될 수 있음을 설명하고 있다. 또한, 계약에 의해 사용이 제한된 데이터도 있음을 언급하고 있다.
- 적법한 절차의 중요성
- 데이터를 사용할 때는 적법한 절차를 따라야 하며, 이를 어길 경우 그 책임이 확대될 수 있음을 경고하고 있다. 투명성과 공정성을 확보하기 위해서는 절차 준수가 필수적이라는 점을 강조한다.
- 데이터 거버넌스 체계의 필요성
- 데이터 관리와 윤리를 위해 데이터 거버넌스 체계를 구축할 필요가 있으며, 그 체계의 정점에는 정책(Policy)과 최고 데이터 책임자(CDO, Chief Data Officer)가 위치해야 함을 강조하고 있다.
요약
데이터 윤리와 거버넌스는 데이터의 수집 및 활용에서 발생할 수 있는 윤리적, 법적 문제를 예방하고 투명성 및 공정성을 유지하기 위해 필수적이다.


데이터 크롤링은 웹에서 데이터를 수집하는 데 유용하지만, 법적 및 윤리적 책임을 수반한다. 데이터 수집 및 활용의 투명성과 적법성을 유지하며, 불필요한 정보는 정제하고, 출처와 저작권을 명확히 해야 한다는 점을 강조하고 있다.










이 슬라이드는 블랙박스 문제에 대해 설명하고 있으며, 딥 러닝(Deep Learning)의 구조를 도식으로 보여주고 있다.
주요 내용
- 딥 러닝 구조
- 그림에는 인공 신경망의 기본 구조가 나타나 있다. 입력층(Input Layer), 여러 개의 숨겨진 층(Hidden Layers), 출력층(Output Layer)으로 구성되어 있으며, 이 구조를 통해 딥 러닝이 데이터에서 특징을 추출하고 예측을 수행한다.
- 입력층: 다양한 특징(데이터의 속성)을 받아들이는 층이다.
- 숨겨진 층: 여러 개의 레이어가 쌓여 있으며, 데이터를 복잡하게 가공하고 변환한다. 이 레이어들이 많아질수록 네트워크가 더 깊어져 "딥 러닝"이라고 불리게 된다.
- 출력층: 최종 예측 결과를 내는 층이다.
- 블랙박스 문제
- 딥 러닝 모델의 계산 과정은 매우 복잡하고 많은 계층이 얽혀 있어서 내부 과정이 불투명하게 느껴지는 블랙박스(Black Box)로 인식된다. 모델이 어떤 이유로 특정 결정을 내렸는지 해석하기 어려운 문제가 발생한다.
요약
딥 러닝 모델은 입력된 특징을 바탕으로 숨겨진 층에서 복잡한 계산을 통해 결과를 예측하지만, 내부 계산 과정이 불투명하여 블랙박스 문제를 야기한다. 이는 딥 러닝이 높은 성능을 보이면서도 신뢰성과 해석 가능성에서 어려움을 겪게 만드는 주요 요인이다.







정리를 마치고
슬라이드 내용이 설명을 매우 잘 해놓아서 특별히 추가로 기록할 것은 많지 않았다. 이 강의를 듣고 인공지능에서 가장 고려할 부분은 기술적인 문제가 아니라 윤리라는 것을 알게 되었다. 그리고 인공지능 생산물에 대한 저작권 표기에 대해 누구에게 소유권이 있는지에 대한 것도 논의할 중요한 사항이다.
윤리는 사람을 위한 것이므로 인공지능에게 윤리를 부여할 수는 없을 것이다. 어떤 것이 인간을 위한 선택인지 우리는 많은 고민을 하며 앞으로도 여러 토의를 거쳐 인공지능 법 제도도 마련하고 체계화될 것이라 생각한다.
인공지능과 인간은 서로 상생하는 관계이다. 하나님께서는 인간을 창조하셨고, 인간은 인공지능을 만들었다. 이러한 조화가 참 놀랍고 경이롭다.



