
- 분류 전체보기 (1634)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 정보처리기사실기
- 디버깅
- 상속
- 정보처리기사필기
- html/css
- 데이터분석
- 자바
- 자바스크립트심화
- c언어
- 데이터베이스
- 중학수학
- ChatGPT
- rnn
- JSP/Servlet
- CSS
- 자바 실습
- 순환신경망
- 자바스크립트
- SQL
- 혼공머신
- 파이썬
- 컴퓨터비전
- 딥러닝
- JSP
- 개발일기
- 컴퓨터구조
- 머신러닝
- 연습문제
- 중학1-1
- JDBC
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
순환 신경망(RNN) 6 - 자연어 처리 4 : 한국어 감성 분석 3 <데이터 전처리와 모델> 본문
매캅 설치가 잘 되었으니 이제 본격적으로 한국어 감성 분석을 진행해 보겠다. 얼마나 어려웠는지 모른다. 그래도 개발일지에 자세히 적어놓았으니 다음에 설치할 때 참고하면 될 것 같다.
한국어 감성 분석 세 번째
형태소 분석기 불러오기 이어서
매캅은 여기에 잘 설치되었다.

샘플 문장에 각 형태로 분석기를 적용해 형태소를 분리해 보겠다. "오늘날씨어때"는 띄어쓰기가 안된 문장이다. "오늘", "날씨"로 분리할 수도 있지만, "오늘날", "씨"라고 분리할 수도 있다. 이처럼 띄어쓰기가 안 돼 있을 때는 형태소 분석이 어렵다.
또한 오타가 있을 경우에도 제대로 된 분리가 어려울 수도 있다. 특정 분야(도메인)에서 즐겨 사용되는 전문 영어가 있다면 해당 단어를 사용자 사전에 미리 추가하는 것을 권장한다.
다음 코드에서 "영실아안녕오늘날씨어때?"라는 샘플 문장에 대한 분석 결과는 mecab이 가장 그럴듯하다.


안뇽이라는 단어를 신조어 또는 맞춤법이 틀린 단어라고 한다면, komoran과 mecab은 제대로 형태소를 분리하지 못하는 것을 볼 수 있다.


일반적으로 형태소 분리의 결과가 모델 성능에 큰 영향을 줄 수 있다. 따라서 띄어쓰기와 맞춤법에 맞는 문장으로 이루어진다면 좋은 성능을 기대할 수 있다. 샘플 문장을 통해 형태소 분석기별 특징을 더 자세히 살펴보겠다.


데이터 전처리
간단한 탐색적 데이터 분석 결과 특수문자, 숫자 등이 포함되어 있음을 발견할 수 있었다. 이제 데이터 전처리를 진행한다. 먼저 정규식을 활용해 영어, 한글, 띄어쓰기만 남긴다.
이전 코드가 실행되어야 이 코드가 실행될 수 있어 몇 개의 코드를 다시 실행했다.

결측치가 있는 행 5개는 앞에서 확인한 대로 빈 리뷰가 긍정도 있고 부정도 있어 의미가 없기 때문에 제거한다.

스탑워드는 불용어를 뜻한다. 일반적으로 사용하지 않는 단어, 관사, 전치사, 조사, 접속사 등 의미가 없는 단어를 제거한다. 많은 한글 불용어가 있겠지만 예제로 몇 개만 작성해 보았다. word_tokenization 함수에서 불용어를 제거하고 mecab을 통해 형태소를 분리한다.

다음과 같이 document 열의 텍스트 데이터에 word_tokenization 함수를 적용하면 형태소 단위로 분리된다.

train 데이터와 validation 데이터를 분리하는 방법은 여러 가지가 있으며 training_size를 기준으로 분리해 보자.

순환신경망(딥러닝)에 텍스트를 입력으로 넣기 위해서는 몇 가지 전처리가 더 필요하다.
- 토큰화 : 단어 사전을 만들고 문자를 숫자로 변환한다.
- 동일한 문장 길이로 정리 : 모든 텍스트의 길이를 동일하게 맞춘다. 최대 100개 글자로 맞춘다면 50개 글자를 가진 문장은 앞 또는 뒤에 0으로 채운다.

다음 코드에서 사용한 단어 수(vocab_size)를 15,000개로 설정했지만 단어 사전 크기(word_count)를 확인해 보면 단어의 개수는 전체 단어 수임을 알 수 있다. 먼저 전체 단어를 사전으로 만든 뒤 texts_to_sequences 할 때 우리가 설정한 vocab_size가 적용된다.


각 문장을 숫자 벡터로 변환하여 인코딩한다.

train 데이터셋의 문장 중에서 최대 길이(maxlen)는 74개이다.

문장의 길이를 동일하게 맞추기 위해 pad_sequences를 활용하여 패딩 처리한다 이때 maxlen 보다 짧은 문장은 padding_type = 'post' 설정으로 문장 뒤에 0을 붙여서 길이를 맞춘다(설정 값이 pre일 경우 문장 앞에 0을 붙인다). maxlen보다 긴 문장은 trunc_type = 'post' 설정으로 문장 뒤를 자른다. 동일한 길이가 적용된 샘플 데이터를 확인해 보자.

모델
임베딩은 텐서플로(케라스)에서 제공하는 임베딩 레이어를 통해 쉽게 사용할 수 있다. 정수 인덱스에서 고밀도 벡터로 매핑되어 단어 간의 유사성을 함께 인코딩한다.
양방향 LSTM 레이어와 긍정과 부정 분류를 위한 마지막 출력 레이어는 'sigmoid' 활성화 함수를 적용하기로 한다. 두 개 이상의 LSTM 레이어를 쌓기 위해서는 전체 시퀀스 출력이 필요하기 때문에 return_sequences = True로 설정한다.

Output Shape가 ?로 표시되는 이유는, Sequential 모델을 생성할 때 입력 데이터의 input shape(입력 크기)을 명시하지 않았기 때문이다. Keras는 입력 데이터의 크기를 모르는 상태에서 ?로 출력 Shape을 표시한다.


해결 방법
1. Embedding 레이어에 input_length 추가
Embedding 레이어에서 입력 데이터의 길이를 명시해 주면 문제가 해결된다. 예를 들어, 입력 데이터의 최대 길이를 100으로 설정한다고 하면
Embedding(vocab_size, 32, input_length=100)
2. Sequential 모델의 첫 번째 레이어에 input_shape 지정
Embedding 레이어 외에도 모델의 첫 레이어에서 input_shape을 명시할 수 있다. 입력 데이터의 크기를 (100,)으로 지정하면 Keras가 입력 Shape을 인식하게 된다.
Embedding(vocab_size, 32, input_length=100)
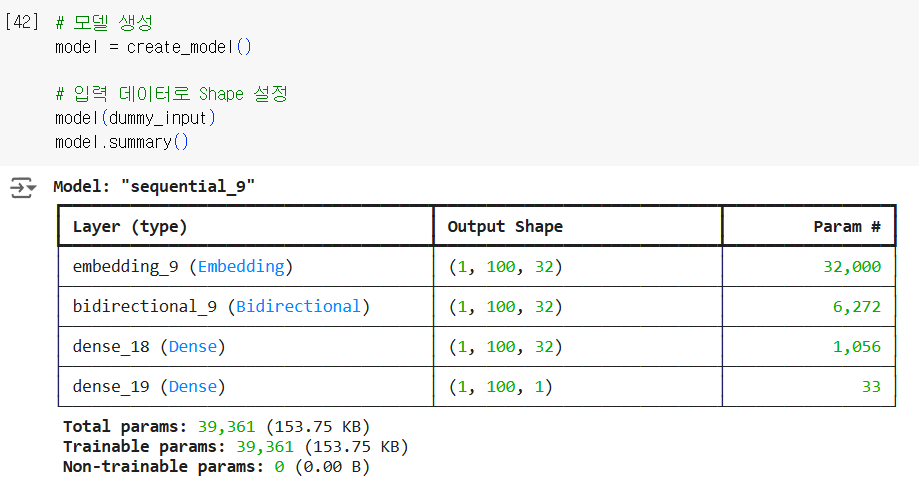
책과 다르게 None으로 나오지 않고 입출력 숫자가 나오고 있다. 최대한 책과 비슷하게 하려고 코드를 수정했으나 dummy_input을 지우면 다시 ?표로 나온다.
딥러닝 모델의 구조가 복잡할수록 데이터 크기가 클수록 학습 시간이 오래 걸린다는 문제가 있다. 따라서 오랜 시간 학습시킨 모델을 저장할 필요가 있다. 콜백 함수의 Model Checkpoint를 활용해 가장 좋은 평가 가중치만 저장하는 방법과 모델 전체를 저장하는 방법이 있다. save_best_only = True 옵션을 설정해, 평가 결과가 가장 좋은 가중치만 저장한다.

에러 메시지 ValueError: When using save_weights_only=True in ModelCheckpoint, the filepath provided must end in .weights.h5 (Keras weights format). Received: filepath=best_performed_model.ckpt 를 보면 save_weights_only=True 로 설정했을 때 파일 경로가 .weights.h5 로 끝나야 하는데, 현재는 best_performed_model.ckpt 로 끝나기 때문에 발생하는 문제이다.
ModelCheckpoint 콜백은 모델의 가중치 또는 전체 모델을 저장하는 데 사용된다. save_weights_only=True 로 설정하면 모델의 가중치만 저장되며, 이 경우 Keras는 파일 경로가 .weights.h5 로 끝나기를 기대한다. .h5 확장자는 Keras에서 모델 가중치를 저장하는 데 사용되는 HDF5 파일 형식을 나타낸다.
따라서, checkpoint_path 변수에 저장된 파일 경로를 .weights.h5 로 끝나도록 변경해야 한다.

이제 잘 된다. 책 코드와는 다른 경우가 많아 책만을 믿어서는 안 된다.
콜백 함수의 Early Stopping을 활용하여, 모델의 검증 손실함수(val_loss)가 2 epoch 이상 개선되지 않으면 학습을 조기에 종료하는 옵션을 설정한다.

오류 메시지와 함께 제공된 코드에 따르면, train_labels와 모델의 출력 output의 차원(rank)이 맞지 않아서 발생하는 문제야. target.shape과 output.shape의 차원을 맞춰야 오류를 해결할 수 있다.
문제 분석
오류 내용
ValueError: Arguments `target` and `output` must have the same rank.
target.shape=(64,), output.shape=(64, 116, 1)
- target (train_labels)의 Shape은 (64,) → 1차원
- output의 Shape은 (64, 116, 1) → 3차원
binary_crossentropy 손실 함수는 target과 output의 Shape이 같아야 작동하지만, 현재 모델의 출력이 추가적인 차원을 포함하고 있어 문제가 발생했다.
문제 해결 방법
1. LSTM 레이어의 return_sequences 설정 확인
LSTM 레이어에서 return_sequences=True로 설정했기 때문에, 출력의 Shape에 시퀀스 길이(116)가 포함되고 있다.
수정
- return_sequences=True를 제거하여 마지막 출력만 반환하도록 설정
Bidirectional(LSTM(32, return_sequences=False))
2. train_labels와 출력 Shape 일치시키기
train_labels의 Shape을 (64, 1)로 변경해 출력 Shape과 맞출 수도 있다.
수정
- train_labels의 Shape을 변경하기
train_labels = train_labels.reshape(-1, 1)



10 에포크 중 8번째까지 진행되었다. 책에서는 4까지 실행되었다.
학습을 마치고
이번 학습도 정말 만만치 않은 어려움이 있었지만 잘 이겨냈다. 이제 한국어 감성분석 실습도 얼마 남지 않았다. 평가부터는 다음 포스트에 이어서 학습해 보겠다.
이상하게도 책과 코드와 이렇게도 다른지 모르겠다. 컴퓨터 환경인지 텐서플로 버전마다 차이가 있는지 모르겠다. 그래서 책을 개정할 때는 이런 부분을 신경 쓰면 좋을 텐데 대부분의 저자들은 이 부분을 신경 쓰지 않고 오래된 코드를 배포하는 편이다. 책을 볼 때마다 느끼는 점이다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 순환 신경망(RNN) 8 - 자연어 처리 6 : 한국어 감성 분석 5 <KoBERT 토그나이저> (0) | 2024.12.19 |
|---|---|
| 순환 신경망(RNN) 7 - 자연어 처리 5 : 한국어 감성 분석 4 <평가와 저장된 모델 불러오기> (0) | 2024.12.19 |
| 순환 신경망(RNN) 5 - 자연어 처리 3 : 한국어 감성 분석 2 <형태소 분석기 불러오고 Mecab 설치하기> (1) | 2024.12.19 |
| 순환 신경망(RNN) 4 - 자연어 처리 2 : 한국어 감성 분석 1 <데이터 불러오기와 EDA> (2) | 2024.12.19 |
| 순환 신경망(RNN) 3 - 자연어 처리 1 : 자연어 처리 방법 (0) | 2024.12.18 |



