
- 분류 전체보기 (1596)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 디버깅
- 컴퓨터구조
- 상속
- 머신러닝
- 혼공머신
- 자바스크립트
- 데이터분석
- CSS
- 연습문제
- JDBC
- 중학1-1
- 데이터베이스
- 딥러닝
- JSP/Servlet
- 자바
- 정보처리기사실기
- 개발일기
- 중학수학
- 문자와식
- JSP
- 오블완
- c언어
- 자바스크립트심화
- 자바 실습
- 정보처리기사필기
- SQL
- html/css
- 컴퓨터비전
- 티스토리챌린지
- 파이썬
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
순환 신경망(RNN) 7 - 자연어 처리 5 : 한국어 감성 분석 4 <평가와 저장된 모델 불러오기> 본문
한국어 감성 분석을 평가하는 실습부터 진행해 보겠다.
한국어 감성 분석 네 번째
평가
모델 학습 결과를 그래프로 출력해서 확인한다. 훈련 셋과 검증 세의 예측 정확도를 비교해 보면 훈련 셋의 정확도는 89%이고 검증 셋의 정확도는 85%이다.

손실 함수 그래프를 살펴보자. 1 epoch 이후 loss는 계속 낮아지지만 val_losss는 점점 증가하면서 과대적합 경향을 보인다.

이제 테스트 데이터셋을 불러와서, 동일한 전처리 과정을 거친 후에 직접 모델에 적용해 본다.

앞에서 처리한 텍스트 전처리 과정을 그대로 처리하는 함수를 정의하고, 테스트 데이터셋을 입력한다.

테스트 데이터를 모델에 입력으로 넣은 결과 정확도가 84%로 나타났다. 이는 앞에서 나온 검증 결과와 차이가 없다.
저장된 모델 불러오기
체크포인트로 저장된 가중치를 불러온다. 비교를 위해 먼저 가중치 적용 전의 모델로 평가하고 이후 저장된 가중치를 적용하여 평가한다. 먼저 모델 학습을 하지 않은 상태의 가중치 적용 전의 기본 모델을 다시 생성해서 테스트 데이터에 대한 예측력을 평가하면 약 49%의 정확도를 나타낸다.

오류는 test_label의 Shape과 model2의 출력 Shape이 일치하지 않기 때문에 발생했다. target.shape는 (None,)인데, 모델 출력의 Shape은 (None, 116, 1)이므로 차원이 다르다는 문제가 발생한 것이다
문제 해결 방법
1. LSTM의 return_sequences 문제 해결
현재 모델의 LSTM 레이어가 return_sequences=True로 설정되어 있어 출력 Shape에 시퀀스 길이(116)가 포함된다. return_sequences=False로 설정하여 마지막 타임스텝의 출력만 반환하도록 수정해야 한다.

2. test_label의 Shape 확인
test_label은 1차원 배열이어야 하며, 각 값이 0 또는 1이어야 한다. 예를 들어 (num_samples,) 형태라면 아래처럼 2차원으로 변환해야 할 수도 있다.


이제 모델을 생성하고 평가를 진행했다.
요약
- LSTM에서 return_sequences=False로 수정하여 출력 Shape을 (None, 1)로 변경
- test_label의 Shape을 (num_samples, 1)로 맞춤
- evaluate 실행 전 데이터의 Shape 확인
이번에는 앞서 저장한 모델을 불러온다. 테스트 데이터에 대한 예측력을 평가하면 약 85%의 정확도를 보인다. 학습된 저장치를 그대로 불러와서 사용하기 때문에 정확도가 그대로 유지된다.

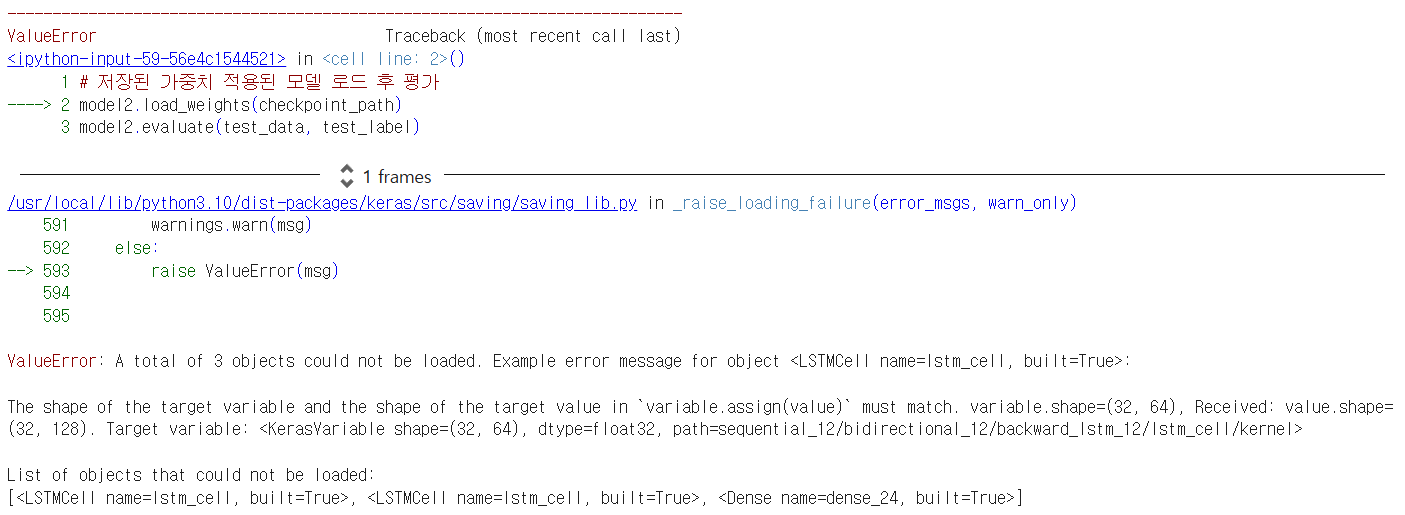
이 오류는 모델 구조가 가중치를 저장한 모델과 로드하려는 모델 사이에 불일치가 있기 때문에 발생한 것이다. 구체적으로, LSTM 레이어나 다른 레이어의 가중치 Shape이 맞지 않아서 문제가 발생했다.
해결 방법
1. 동일한 모델 구조를 사용
저장된 가중치를 로드하려면 저장할 때 사용한 모델과 완전히 동일한 구조를 사용해야 한다.
확인 및 해결 방법
model2를 생성하기 전에 가중치를 저장한 모델과 동일한 구조로 다시 정의해야 한다.
# 동일한 모델 구조 생성
model2 = create_model()
# 가중치 로드
model2.load_weights(checkpoint_path)
# 평가
model2.evaluate(test_data, test_label)
2. 가중치 저장 시 모델 구조 저장
모델 가중치뿐만 아니라 모델 구조까지 저장하고 로드하는 방법을 사용하면 이런 문제를 방지할 수 있다.
# 모델 저장
model.save('model_with_weights.h5')
# 모델 로드
model2 = tf.keras.models.load_model('model_with_weights.h5')
# 평가
model2.evaluate(test_data, test_label)


이래도 오류가 발생해서 몇 번을 수정했는지 모른다.


이 코드는 아무리 해도 실행이 되지 않아서 가중치 로드에서 한 줄을 삭제하고 실행했다. 이렇게 하니 정확도가 50%밖에 나오지 않는다. 마지막으로 한번 더 코드를 수정해 보기로 했다.
코드 다시 수정하기
ValueError: A total of 4 objects could not be loaded. 에러 메시지는 가중치를 불러오려는 모델(model2)의 아키텍처와 가중치를 저장할 때 사용된 모델(이전에 훈련되어 'best_performed_model.weights.h5'에 저장된 모델)의 아키텍처 간에 불일치가 있음을 나타냅니다. 이러한 불일치는 적어도 다음과 같은 측면에서 발생한다.
- 임베딩 레이어 : 저장된 모델은 vocab_size가 1000인 임베딩 레이어를 가지고 있었을 가능성이 높지만, model2는 vocab_size가 15000으로 정의되어 있다. 이는 에러 메시지 variable.shape=(15000, 32), Received: value.shape=(1000, 32)에서 확인할 수 있다.
- LSTM 레이어 : 저장된 모델의 LSTM 레이어는 model2의 LSTM 레이어와 다른 구성(예: 유닛 수)을 가질 수 있다. 에러 메시지는 LSTM 레이어(LSTMCell)와 관련된 객체를 불러올 수 없음을 보여준다.
- Dense 레이어 : Dense name=dense_42에 대한 에러 메시지에서 알 수 있듯이 Dense 레이어 중 하나에 불일치가 있을 수 있다. 이는 유닛 수 또는 다른 레이어 구성의 차이로 인해 발생할 수 있다.


이 코드도 1시간 넘게 고민하며 정말 공들여서 실행했다.
학습을 마치고
언어지능 공부가 너무나도 어렵고 힘들다. 코드를 아무리 실행하고 수정해도 맞는 코드가 별로 없어서 한 문장 실행하고 코드 고치는데 30분 이상 시간을 보내고 있다. 이런 식으로 공부하니 진도가 잘 나가지 않는다.
정말 힘들지만 그래도 하는 데까지 해볼 것이다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 순환 신경망(RNN) 9 - 자연어 처리 7 : 자연어 생성 (0) | 2024.12.19 |
|---|---|
| 순환 신경망(RNN) 8 - 자연어 처리 6 : 한국어 감성 분석 5 <KoBERT 토그나이저> (0) | 2024.12.19 |
| 순환 신경망(RNN) 6 - 자연어 처리 4 : 한국어 감성 분석 3 <데이터 전처리와 모델> (0) | 2024.12.19 |
| 순환 신경망(RNN) 5 - 자연어 처리 3 : 한국어 감성 분석 2 <형태소 분석기 불러오고 Mecab 설치하기> (0) | 2024.12.19 |
| 순환 신경망(RNN) 4 - 자연어 처리 2 : 한국어 감성 분석 1 <데이터 불러오기와 EDA> (0) | 2024.12.19 |



