
- 분류 전체보기 (1698)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 상속
- JDBC
- 정보처리기사실기
- 정보처리기사필기
- ChatGPT
- 중학수학
- JSP/Servlet
- rnn
- 자바 실습
- SQL
- c언어
- 자바스크립트
- 데이터베이스
- 연습문제
- 개발일기
- 컴퓨터비전
- 자바
- 디버깅
- CSS
- 중학1-1
- 혼공머신
- 딥러닝
- html/css
- 파이썬
- 데이터분석
- JSP
- 컴퓨터구조
- 순환신경망
- 머신러닝
- 자바스크립트심화
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
맞춤형 챗봇을 구축하는 LLM 활용 - 테스트 문제 풀기 본문
조금 전에 끝마친 과목에 대한 테스트 문제도 풀어보려고 한다. 프롬프트 엔지니어링 기초 지식 과목은 모두 퀴즈 문제뿐이라 별로 어렵지 않았는데 이 과목은 실습 문제도 있어서 시간이 상당히 걸릴 것 같다.
테스트 문제 풀기

문제 1번


답이 3번이라고 생각했는데 1번이었다.
Prompt Engineering
- 모델을 재학습시키지 않고 입력 프롬프트를 조정하여 원하는 출력을 얻는 방법
- 빠르고 경제적이며, 별도의 모델 변경이 필요 없지만, 모델의 한계로 인해 잘못된 답변을 내놓을 가능성이 있다.
- 정답 : Prompt Engineering은 잘못된 답변을 내놓을 수 있다. → 맞는 설명
Fine-tuning
- 사전 학습된 모델을 특정 데이터셋으로 추가 학습하여 특정 작업에 맞게 최적화하는 방법
- 상대적으로 많은 연산 자원이 필요하며, 학습 데이터에 따라 잘 맞는 결과를 도출함
- 정답 : Fine-tuning은 학습한 데이터에 잘 맞는 결과를 도출한다. → 맞는 설명
Fine-tuning은 Prompt-Engineering보다 적은 연산으로 학습이 가능하다.
이 문장은 틀린 설명이야. Fine-tuning은 Prompt Engineering보다 더 많은 연산 자원이 필요하다.
문제 2번


이유
ELMo, LSTM, BERT는 다음과 같은 특징이 있다.
- LSTM (Long Short-Term Memory) : RNN(Recurrent Neural Network)의 변형으로, 순차적인 데이터를 처리하며, 장기 의존성을 학습할 수 있음. 순환 신경망 기반 모델
- ELMo (Embeddings from Language Models): 문맥을 고려한 단어 임베딩을 생성하는 모델로, 양방향 LSTM을 사용해 단어의 문맥 정보를 학습함
- BERT (Bidirectional Encoder Representations from Transformers) : 트랜스포머 기반의 양방향 모델로, 문맥을 양방향으로 이해하고 처리하는 Encoder 구조를 사용
- GPT (Generative Pre-trained Transformer)
- 트랜스포머 기반이지만, 단방향(Left-to-Right)으로 학습하며 주로 텍스트 생성에 중점을 둔 Decoder 구조를 사용
결론
- ELMo, LSTM, BERT는 주로 양방향 또는 순차적 학습 구조를 가지는 반면, GPT는 단방향이고 주로 텍스트 생성에 특화된 구조를 가지고 있다.
- 따라서, GPT가 "다른 분류"에 해당한다고 볼 수 있다.
문제 3번


할루시네이션을 유도해서는 안된다.
문제 4번


이 문제는 빅오(Big-O) 표기법에 대한 틀린 설명을 고르는 문제이다.
선택지 분석
- "빅오 표기법은 알고리즘의 최악의 경우 실행 시간을 나타냅니다."
→ 맞는 설명- 빅오는 알고리즘의 최악의 경우 실행 시간 또는 복잡도를 나타내는 데 사용된다.
- "빅오(O)는 상한을 나타내며, 최대 실행 시간의 추정을 제공합니다."
→ 맞는 설명- 빅오 표기법은 상한(upper bound)을 나타내므로 최대 실행 시간에 대한 추정치를 제공함
- "빅오는 항상 정확한 실행 시간을 나타내며, 절대적인 값으로 해석할 수 있습니다."
→ 틀린 설명- 빅오는 실행 시간의 정확한 값을 나타내지 않고, 입력 크기에 따른 성장률(growth rate)을 나타내는 상대적인 개념임
- 절대적인 실행 시간을 제공하지 않으므로 틀린 설명
- "빅오는 주로 알고리즘의 효율성을 비교하고 분류하는 데 사용됩니다."
→ 맞는 설명- 빅오는 알고리즘의 효율성을 비교하고 분류하는 데 주로 사용됨
정답
3. "빅오는 항상 정확한 실행 시간을 나타내며, 절대적인 값으로 해석할 수 있습니다."
- 이는 빅오 표기법의 개념과 맞지 않으므로 틀린 설명이다.
문제 5번


주어진 코드는 재귀적으로 피보나치 수열을 계산하는데, 동일한 값을 여러 번 계산하기 때문에 비효율적이다. 효율적으로 만들기 위해 동적 프로그래밍(Dynamic Programming)을 활용할 수 있다. 아래는 효율적인 코드로 변환한 후, 파이썬 코드로 작성한 것이다.

변경 내용 설명
- 메모이제이션 사용
- 이전에 계산한 값을 배열에 저장해 중복 계산을 피함
- 반복문으로 재귀 대체
- 재귀 대신 반복문을 사용해 호출 스택 오버플로우 위험 제거
- 시간 복잡도 개선
- 기존 코드의 시간 복잡도는 O, 변경된 코드는 O(n)으로 개선됨

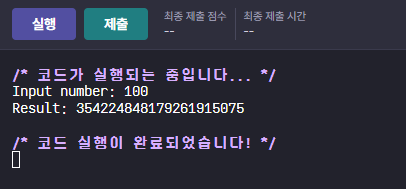

문제 6번



housing.csv라는 이름으로 이 파일이 저장되어 있다.
문제 풀기
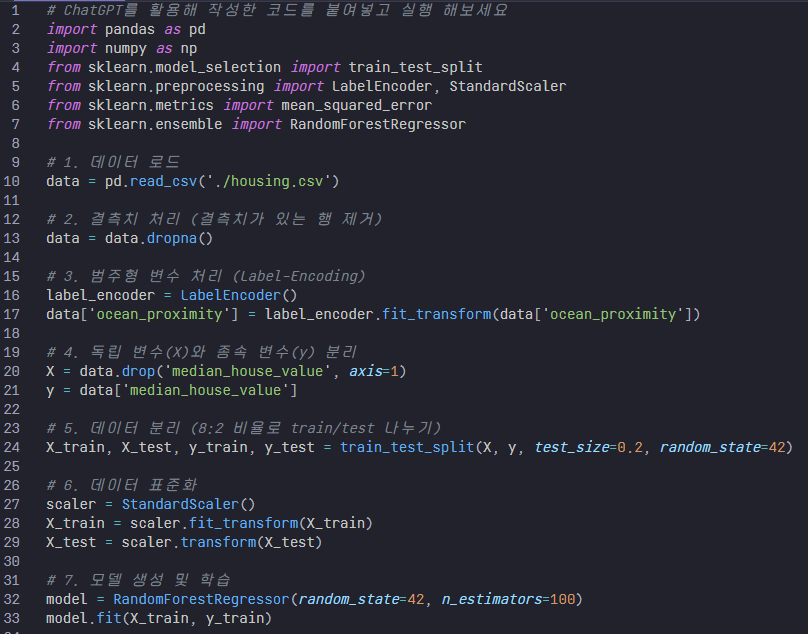

코드 설명
- 결측치 제거
- dropna()를 사용해 결측치가 포함된 행을 제거
- Label-Encoding
- ocean_proximity는 범주형 변수이므로 LabelEncoder를 사용해 숫자형으로 변환
- 데이터 분리
- train_test_split을 사용해 8:2 비율로 데이터를 분리
- 데이터 표준화
- StandardScaler를 사용해 데이터를 표준화(평균 0, 분산 1)하여 모델 성능을 향상
- 모델 학습
- 랜덤 포레스트 회귀(RandomForestRegressor)를 사용해 학습
- 모델 평가
- mean_squared_error를 활용해 RMSE를 계산


하지만 정답이 틀렸다고 나온다. 이번에 지시를 여러 개 추가해서 더 정확하게 코드를 요청했다.
코드 수정하기
아래는 요청에 따라 데이터를 학습시키기 위해 데이터 표준화를 제거하고, 랜덤 포레스트 대신 선형 회귀 모델을 사용한 수정된 코드이다. 또한, median_house_value를 예측하도록 구현했다.



이제 완벽하게 점수가 100점이다.
학습을 마치고
1시간이 넘도록 문제를 풀었다. 마지막 문제는 몇 번을 해도 안 나와서 넘어가고 싶었지만 그래도 끝까지 문제를 다 풀기를 잘했다는 생각이 들었다. 역시 난 프로그래밍에 재능이 있고 공부도 못하지 않고 잘하는 사람인 것 같다.
그동안 공부를 못한 게 아니라 안해서 그런 것임을 올해 느낄 수 있었다.
'인공지능 > 프롬프트 엔지니어링 & 생성형 AI' 카테고리의 다른 글
| 애플리케이션 개발을 위한 생성 AI 활용 프로세스 이해하기 2 - 세부 기능 정의와 UI 구현 (0) | 2024.12.22 |
|---|---|
| 애플리케이션 개발을 위한 생성 AI 활용 프로세스 이해하기 1 - 과정 소개 및 사용자 input과 생성 AI output (0) | 2024.12.22 |
| 프롬프트 엔지니어링을 위한 기초 지식 - 테스트 문제 풀기 (0) | 2024.12.21 |
| 프로그래밍을 위한 프롬프트 엔지니어링 6 - PDF 파일 이름 변경 및 병합 코드 생성하기 (0) | 2024.12.21 |
| 프로그래밍을 위한 프롬프트 엔지니어링 5 - 효율적인 코드로 변환하기와 전처리 코드 추가하기 (0) | 2024.12.21 |



