
- 분류 전체보기 (1703)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 자바
- 정보처리기사실기
- 중학수학
- 파이썬
- 자바 실습
- 데이터분석
- 순환신경망
- 자바스크립트
- JDBC
- 컴퓨터비전
- SQL
- 혼공머신
- JSP/Servlet
- 개발일기
- html/css
- c언어
- 중학1-1
- 딥러닝
- 디버깅
- 데이터베이스
- ChatGPT
- 컴퓨터구조
- rnn
- CSS
- 연습문제
- 자바스크립트심화
- 정보처리기사필기
- JSP
- 상속
- 머신러닝
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
Orange 3 - 머신러닝 7단계에 따라 BMI 예측 실습해보기 1 : 1~4단계 과정 본문
오렌지 프로그램의 첫번째 실습을 진행해보겠다. 수업 영상이 없어서 그냥 파일만 보고 어떤 내용인지 스스로 추측하며 학습일지를 정리해보려고 한다.
BMI 예측 실습해보기

1. 문제 정의 및 데이터 수집

1. 문제 정의
- 목표: 500명의 키와 몸무게 데이터를 바탕으로 BMI(체질량지수)를 예측하는 문제를 해결하는 것

각 컬럼(열)에는 데이터 유형과 역할을 정의한다.
- Gender (성별)
- Type: 범주형(Categorical) 데이터로 설정되었다. 이 열은 'Female', 'Male' 두 개의 값으로 구분된다.
- Role: skip으로 설정되어, 성별 데이터는 모델 학습에 사용되지 않는다. 성별은 BMI를 예측하는 데 중요한 역할을 하지 않기 때문에 학습에 포함하지 않은 것으로 보인다.
- Height (키)
- Type: 숫자형(Numeric) 데이터로 설정되었다. 키는 모델이 BMI를 예측할 때 중요한 **특성(Feature)**으로 사용된다.
- Role: feature로 설정되어, 모델이 학습하는 데 사용된다.
- Weight (몸무게)
- Type: 숫자형(Numeric) 데이터로 설정되었습니다. 몸무게 역시 BMI 예측에 중요한 **특성(Feature)**으로 사용된다.
- Role: feature로 설정되어, 학습에 사용된다.
- Label (BMI 레이블)
- Type: 범주형(Categorical) 데이터로 설정되었다. 이 열에는 'Extreme Obesity', 'Extremely Weak', 'Normal' 등 BMI 상태를 나타내는 값이 포함되어 있다.
- Role: target으로 설정되었다. 이 열은 모델이 예측해야 하는 **종속 변수(Target)**로, BMI 상태를 예측하는 것이 목표다.

파일에 bmi를 측정할 수 있는 데이터를 불러와서 넣었고 아래의 내용을 수정해주었더니 원본 데이터의 내용을 볼 수 있게 되었다. 전체 데이터는 500개의 인스턴스(행)와 2개의 특성(열)로 이루어져 있다.
이 데이터는 500명의 키와 몸무게를 바탕으로 BMI 상태를 예측하는 문제를 해결하기 위한 학습 데이터로 사용된다. 여기서 키와 몸무게는 독립 변수이고, BMI 상태가 종속 변수로 예측 대상이 되는 것이다.
2. 데이터 수집 및 원본 데이터
- 원본 데이터는 500명의 키(Height), 몸무게(Weight), 성별(Gender) 및 BMI 라벨이 포함된 데이터이다. 이 데이터는 머신러닝 모델의 학습에 사용된다.
- 데이터에 결측치가 없으며, 이상치도 확인되지 않았다. 평균값(mae)과 중위값(median)의 차이가 크지 않아 이상치 처리를 하지 않은 상태이다.
2. EDA 탐색적 데이터 분석

3번째 단계는 데이터 전처리인데 여기서는 이 과정이 필요치 않다.
1. 원본 데이터
- 원본 데이터는 500명의 키(Height), 몸무게(Weight), BMI 상태(Label)를 포함한 데이터셋이다. 이 데이터를 바탕으로 머신러닝 분석이 진행된다.
2. Selected Data -> Feature Statistics
- Feature Statistics로 가는 경로는 데이터의 통계적 특성을 보여주는 과정이다. 이 단계에서는 키와 몸무게의 평균, 중앙값, 분포 등을 확인할 수 있다.
- 이 과정을 통해 각 변수들이 어떻게 분포되어 있는지, 데이터에 이상치(outliers)가 있는지 확인할 수 있는 것이다.
3. EDA 탐색적 데이터 분석 -> 산점도 그래프(시각화)
- 원본 데이터를 기반으로 시각화를 통해 변수들 간의 관계를 확인할 수 있다. 여기서는 산점도 그래프를 통해 키와 몸무게의 상관관계를 파악하려는 것이다.
- 산점도는 각 데이터 포인트(개인)의 키와 몸무게가 어떻게 분포되어 있는지를 보여주고, 이를 통해 데이터의 전반적인 경향성을 확인할 수 있다.
4. Data Sampler (Train/Test 분리)
- 마지막으로 Data Sampler를 사용해 데이터를 **Train(학습 데이터)**와 **Test(평가 데이터)**로 나누는 단계이다. 이렇게 데이터가 분리되면 모델을 학습시키고 성능을 평가하는 데 사용된다.
- 모델의 정확한 평가를 위해 학습과 평가 데이터를 분리하는 것은 필수적인 단계이다.


각각의 그래프로 예측 모델이 만들어졌다. 산점도에 대해 설명해보면 다음과 같다. X축는 사람들의 키가, Y축은 몸무게로 구성되어 있다. 각 데이터 포인트는 **BMI 상태(Label)**에 따라 색상이 다르게 지정되어 있다. 오른쪽 하단의 범례(Legend)를 보면 각 색상이 무엇을 의미하는지 나와 있다.
- 파란색: Extreme Obesity (심각한 비만)
- 빨간색: Extremely Weak (심각한 저체중)
- 노란색: Normal (정상)
- 주황색: Obesity (비만)
- 연두색: Overweight (과체중)
- 핑크색: Weak (저체중)
각 점은 한 명의 데이터를 나타내고 있다. 예를 들어, 키와 몸무게가 비슷한 사람들은 점들이 서로 가깝게 모여있을 것이다. 같은 색상으로 그룹화된 데이터는 비슷한 BMI 상태를 공유하고 있는 걸 의미한다. 예를 들어, 파란색 점들이 주로 몸무게가 많이 나가고, 키가 큰 부분에 분포하고 있다. 이는 심각한 비만에 해당하는 사람들이다.
이 그래프는 키와 몸무게에 따라 BMI 상태가 어떻게 분포되는지를 직관적으로 보여주는 좋은 시각화이다. 이걸 통해 데이터의 분포와 각 BMI 상태별 특성을 한눈에 파악할 수 있다고 한다.
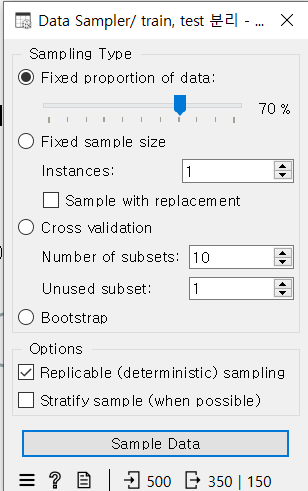
4 과정의 마지막인 세번째 화면은 Orange에서 Data Sampler 위젯을 사용해 데이터를 학습용(train)과 테스트용(test)으로 분리하는 설정 화면이야. 여기서는 데이터를 어떻게 샘플링할지를 설정할 수 있다. 아마도 조금 전에 학습했던 머신러닝 모델 훈련 테스트 과정과 유사해보인다.
이 설정 화면은 데이터를 학습용과 테스트용으로 나누는 과정에서, 얼마나 많은 비율의 데이터를 학습에 사용할지(여기선 70%)를 설정하고, 교차 검증이나 부트스트랩 샘플링 같은 고급 옵션도 선택할 수 있게 해준다.
학습을 마치고
아침에 공부를 하다가 너무나 졸리고 피곤하며 공부에 도저히 집중할 수가 없었다. 잠을 자고 싶지는 않았고 그냥 공부가 정말 하기 싫은 것 같았다. 평소보다 집에 조금 일찍 가서 쉬려고 했는데 집에 가자마자 몇 초만에 잠들어버렸다. 1시간 반 이상 낮잠을 잔 후에 겨우 일어날 수 있었다.
아마도 오늘 1시간밖에 잠을 자지 않아서 그런 것 같다. 잠을 자고 나니 다시 기분이 좋아졌고 머리도 맑아졌다.
그때 일어나서 점심을 먹고 나오느라 5교시가 거의 끝날 때 공부를 시작했지만 그래도 다시 머신러닝에 흥미를 갖고 공부할 수 있어서 기뻤다. 학습 효율은 신체적인 상태와도 관련이 깊다는 걸 오늘 깨닫게 되었다.
이번에는 머신러닝의 4 과정까지 학습을 진행했고 5과정부터 나머지는 다음 포스트에서 이어서 학습하려고 한다. 이 부분부터는 강의 영상이 일부 있어 참고갈 될 것 같다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝의 이해 4 - 머신러닝 개념 정리 및 과대적합 · 과소적합 · 일반화에 대하여 (0) | 2024.09.13 |
|---|---|
| Orange 4 - 머신러닝 7단계에 따라 BMI 예측 실습해보기 2 : 5~7단계 과정 (0) | 2024.09.13 |
| 머신러닝의 이해 3 - 머신러닝 모델 훈련과 테스트 과정 (0) | 2024.09.13 |
| 머신러닝의 이해 2 - 머신러닝의 개념과 종류 그리고 머신러닝의 7단계 과정에 대하여 (0) | 2024.09.13 |
| Orange 2 - 오렌지의 기본 기능 및 사용방법 익히기 (0) | 2024.09.13 |



