
- 분류 전체보기 (764)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 딥러닝
- 코딩테스트
- 파이썬
- 데이터입출력구현
- 핵심프로젝트
- 디버깅
- 텍스트마이닝
- 자바 실습
- 이수증
- 자연수의성질
- 언리얼프로젝트
- html/css
- 데이터분석
- 정보처리기사필기
- numpy/pandas
- c언어
- 중학수학
- pandas
- 선형분류모델
- JSP/Servlet
- 자바
- 머신러닝
- 언리얼학습
- C++
- 선형회귀모델
- 데이터시각화
- 요구사항확인
- 정보처리기사실기
- Orange
- 데이터베이스
- Today
- Total
클라이언트/ 서버/ 엔지니어 " 게임 개발자"를 향한 매일의 공부일지
허깅페이스 4 - 파인 튜닝 모델 사용해보기 1 : 파인 튜닝의 개념 및 학습 데이터 로딩하고 전처리하기 본문
오늘도 새벽 4시 반에 일어나 하루를 시작해보았다. 수학 공부까지 하고 났더니 벌써 6시 반이 다 되어서 정말 많이 아쉽다. 하지만 앞으로 AI 분야와 게임 개발의 전문가가 될 것이므로 수학공부는 필수가 되었다. 수학 공부를 하며 나의 수학 실력이 얼마나 많이 부족한지 느끼고 있다.
오늘 새벽에는 2시간 반 정도 허깅페이스 공부를 하며 다 마치고 교회 가기 전까지 남은 1시간 정도는 플라스크 공부를 해볼 생각이다. 오늘의 학습 목표는 플라스크 공부를 다 마치고 엘리스로 머신러닝 1주차 학습을 마치는 것이다. 그럼 바로 학습을 시작해보자.
허깅페이스 파인 튜닝 모델 사용해보기

1. 모델 파인 튜닝이란 무엇인가?
모델 파인 튜닝(Fine-tuning)은 이미 학습된 사전 학습 모델을 기반으로 새로운 작업에 맞춰 조금 더 학습시키는 과정이다. 이 방식은 처음부터 모델을 학습시키는 것보다 더 빠르고 효율적이며, 적은 데이터로도 성능을 높일 수 있다는 장점이 있다.
모델 파인 튜닝의 개념
파인 튜닝은 크게 두 단계로 나눌 수 있다.
- 사전 학습(Pretraining)
- 대규모 데이터셋에서 기본적인 특성을 학습하는 단계이다. 예를 들어, 언어 모델(예: BERT)은 수많은 텍스트 데이터에서 단어 간의 연관성을 학습한다.
- 이때 모델은 기본적인 패턴이나 특성을 파악하지만, 특정한 문제에 대한 세부 지식은 아직 부족하다.
- 파인 튜닝(Fine-tuning)
- 사전 학습된 모델을 기반으로 새로운 데이터셋에 맞게 추가 학습을 하는 단계이다.
- 사전 학습된 모델의 가중치(weights)를 그대로 가져와서, 특정한 작업(예: 감정 분석, 이미지 분류 등)에 맞게 추가로 미세 조정한다.
- 사전 학습된 모델이 일반적인 특성을 이미 학습했기 때문에, 적은 양의 데이터로도 좋은 성능을 얻을 수 있다.
파인 튜닝의 과정
- 모델 불러오기
- 이미 학습된 사전 학습 모델을 불러오기
- 예를 들어, 이미지 분류에서는 ResNet, 텍스트 분류에서는 BERT 같은 모델을 사용할 수 있다.
- 특정 작업에 맞는 데이터 준비
- 새로운 작업에 맞는 데이터셋을 준비하고, 이 데이터로 모델을 학습시켜. 예를 들어, 고양이와 개를 분류하는 데이터셋이 있을 수 있다.
- 모델의 일부 계층 조정
- 사전 학습된 모델의 초기 계층은 일반적인 특성을 학습하고, 마지막 계층은 새로운 작업에 맞춰 변경한다.
- 예를 들어, 이미지 분류 모델의 경우 마지막 softmax 계층을 새로운 클래스로 바꾸는 식이다.
- 모델 학습
- 사전 학습된 가중치를 기반으로 새로운 데이터셋에 맞게 모델을 미세 조정한다.
- 이 과정에서 모델이 새로운 작업에 대한 세부적인 특성을 학습하게 된다.
- 평가
- 모델을 평가하여 파인 튜닝이 잘 되었는지 확인한다. 적절한 평가 지표를 사용해 성능을 측정할 수 있다.
파인 튜닝의 장점
- 시간과 자원 절약
- 처음부터 학습하는 것보다 훨씬 적은 시간과 컴퓨팅 자원이 필요하다. 특히 대규모 데이터셋을 사용할 필요가 없고, 소량의 데이터로도 좋은 성능을 얻을 수 있다.
- 사전 학습된 지식 재사용
- 대규모 데이터에서 학습한 일반적인 패턴을 새로운 작업에 재사용할 수 있어, 더 나은 성능을 기대할 수 있다.
- 빠른 수렴
- 파인 튜닝은 이미 학습된 가중치에서 시작하기 때문에 학습이 빠르게 수렴한다.
파인 튜닝의 사용 사례
- 자연어 처리(NLP)
- BERT나 GPT 같은 사전 학습된 모델을 특정한 텍스트 작업(감정 분석, 문서 요약 등)에 맞춰 파인 튜닝할 수 있다.
- 컴퓨터 비전(CV)
- 이미 학습된 이미지 분류 모델(ResNet, EfficientNet 등)을 특정 작업(예: 특정 동물 분류)에 맞춰 파인 튜닝할 수 있다.
- 음성 인식
- 음성 인식 모델을 특정 언어에 맞춰 파인 튜닝하여 성능을 개선할 수 있다.
요약하자면, 모델 파인 튜닝은 사전 학습된 모델을 활용하여 새로운 작업에 맞게 미세 조정하는 과정이다. 이 방법은 효율적이고, 적은 데이터로도 좋은 성능을 낼 수 있는 장점이 있다.

2. 파인튜닝 설정하기

이것은 비전 트랜스포머(Vision Transformer, ViT)**의 구조를 설명하고 있다. 트랜스포머 모델은 원래 자연어 처리(NLP)에서 사용되던 모델인데, 이를 이미지 처리에도 적용한 것이 ViT이다. 트랜스포머의 핵심 개념인 셀프 어텐션(Self-Attention) 메커니즘을 사용해서 이미지를 분류할 수 있다.
Vision Transformer (ViT)는 이미지를 작은 패치들로 나누고, 트랜스포머 인코더를 통해 이미지 패치 간의 관계를 학습한다. 이를 통해 이미지의 중요한 특징을 추출하고, 이를 최종적으로 분류하는 과정이다. ViT의 강점은 전통적인 CNN(합성곱 신경망)과는 다르게 모든 패치 간의 상관관계를 학습할 수 있다는 점이다.


이렇게 파이프라인 설치와 업데이트를 진행해준다. 그럼 본격적으로 모델을 가져와서 적용하는 실습을 진행해보자.
3. 학습 데이터 로딩

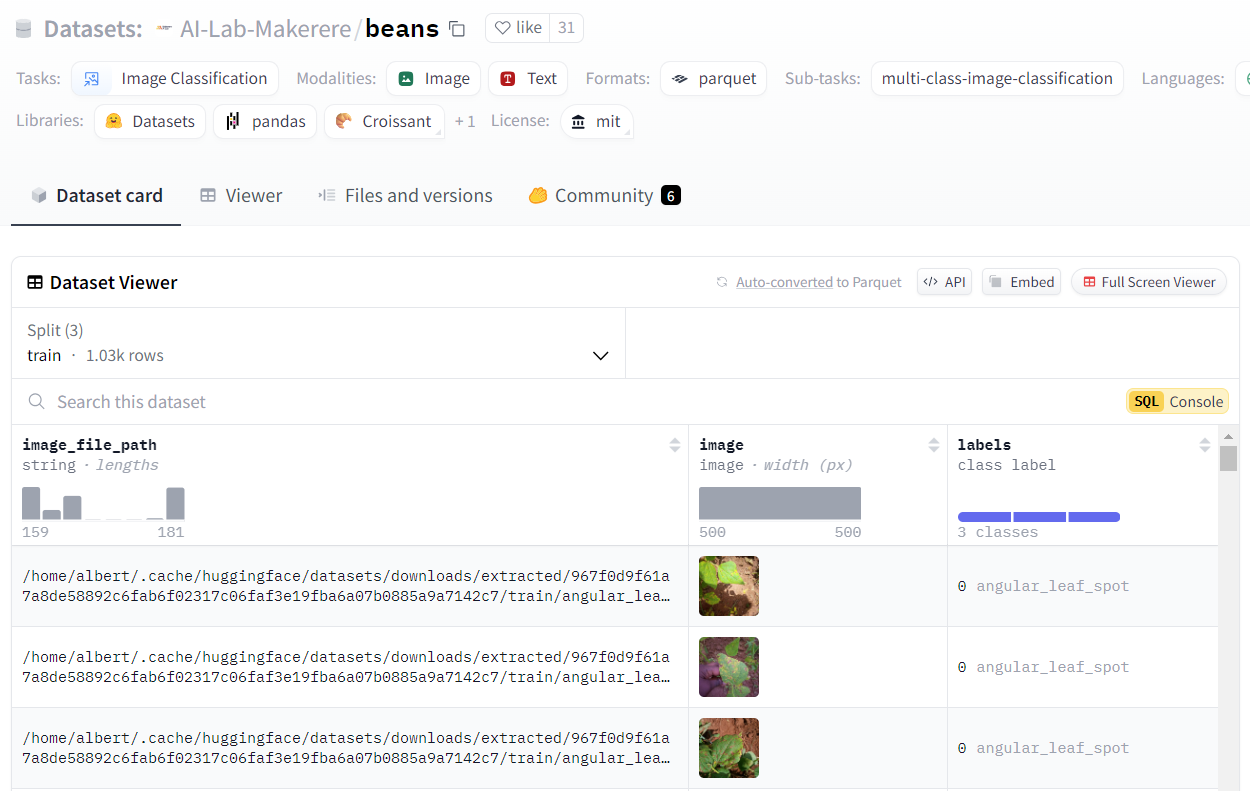
콩잎의 상태를 알아보는 과정을 살펴보기로 하자.

허깅페이스에서 제공하는 데이터셋을 불러온다. datasets 라이브러리의 load_dataset 함수를 사용해 Hugging Face의 "beans" 데이터셋을 로드한다.

그런 다음 bean의 데이터셋을 출력한다. DatasetDict라는 객체는 여러 개의 데이터셋을 포함하는 딕셔너리 형태로 구성되어 있다. 여기서는 훈련(train), 검증(validation), 테스트(test) 세 가지 데이터셋으로 나누어져 있다.
train은 모델을 훈련하고, validation은 모델 훈련 중의 성능을 검증한다. test는 최종적으로 모델이 얼마나 잘 일반화되었는지 평가할 때 사용한다.


train 데이터셋의 레이블 종류를 확인한다. 이 세 가지의 레이블 중에서 0번이라는 질병이라고 판단했다.
4. 이미지 전처리


이미지 전처리는 머신러닝 모델에 데이터를 넣기 전에 이미지를 크기 조정하거나, 주요 특징을 추출하고, 모델에서 필요로 하는 형태로 변환하는 과정이다. 이 코드에서는 다음과 같은 작업을 진행한다.
- 이미지 크기 맞추기 : 이미지를 ViT 모델이 요구하는 입력 크기로 맞추는 작업을 할 수 있다.
- 주요 특징 추출 : 이미지에서 중요한 부분(예: 객체의 모양, 패턴)을 추출한다.
- 스케일링 : 색상 데이터를 범위 0~1로 스케일링하여 모델이 효율적으로 학습할 수 있게 한다.
이 과정을 통해 ViT 모델에 맞는 입력 이미지를 생성할 수 있게 되며, 다음 단계에서 이 이미지를 모델에 전달해 예측을 수행할 수 있다.

dataset['train'][0]['image']라는 첫 번째 학습 데이터의 이미지를 feature_extractor를 통해 전처리하고 있다. 이 과정에서 이미지가 모델에 맞는 형태로 변환돼. return_tensors="pt"는 이 이미지를 PyTorch 텐서(pt) 형태로 반환해 달라는 의미이다. 이렇게 전처리된 이미지는 사전 학습된 모델에 적합한 형식으로 변환돼, 다음 단계에서 모델 입력으로 사용될 수 있다.

이미지 데이터를 전처리하는 함수(transform)를 정의하고, 그 함수를 데이터셋에 적용한 후 전처리된 이미지의 형태(shape)를 확인하는 과정이다.
그리고 콩잎 사진을 언제 보냈는지 궁금했다. 콩잎(beans) 데이터셋은 Hugging Face에서 제공하는 예시 데이터셋 중 하나이다. 앞서 "load_dataset('beans')"를 통해 이 데이터셋을 불러왔는데, 이 데이터셋에는 세 가지 클래스(병과 정상 상태의 콩잎 이미지)가 포함되어 있다. 여기에 따라 우리는 콩잎의 상태를 분석한 것이다.
여기까지 하면 전처리 과정이 끝났다.
학습을 마치고
수업 영상이 없으니 학습이 조금 더 빨리 끝난다는 장점이 있었다. 이 단원에서는 파인 튜닝 모델이 무엇이며 어디에 사용되는지에 대해서 먼저 학습했다. 그런 다음 콩잎 모델을 가져온 후 학습 데이터를 가져와 전처리하는 과정까지 진행해보았다.
이제는 어떤 단계에 따라 머신러닝이 동작하는지 좀더 익숙해졌다. 다음 포스트에서는 이 다음 단계인 학습과 검증하는 과정을 배워볼 것이다. 이제 허깅페이스 공부도 거의 마무리가 되어 간다.
처음에는 단어조차 낯설었지만 이젠 필요시에 모델을 가져다가 사용할 수 있다는 것도 알게 되고 많은 것들을 배웠다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 플라스크 1 - 플라스크 사용 환경 구축 및 첫 웹 페이지 열기 (0) | 2024.09.15 |
|---|---|
| 허깅페이스 5 - 파인 튜닝 모델 사용해보기 2 : 콩잎 모델 직접 만들고 사용해보는 실습 (0) | 2024.09.15 |
| 허깅페이스 3 - 객체 탐지 기능 사용해보기 : Yelo 모델 (0) | 2024.09.14 |
| 허깅페이스 2 - 한국어를 영어로 번역하고 요약하며 텍스트를 음성으로 들려주는 허깅페이스 모델 사용해보기 (0) | 2024.09.14 |
| 허깅페이스 1 - 구글 코랩으로 허깅페이스 모델 사용해보는 실습해보기 (0) | 2024.09.14 |



