
- 분류 전체보기 (764)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 선형회귀모델
- 코딩테스트
- 디버깅
- 데이터분석
- 이수증
- pandas
- 정보처리기사실기
- 정보처리기사필기
- 핵심프로젝트
- 텍스트마이닝
- C++
- 중학수학
- 데이터베이스
- 파이썬
- JSP/Servlet
- Orange
- 자바
- 자바 실습
- 선형분류모델
- 자연수의성질
- html/css
- 머신러닝
- 데이터시각화
- 딥러닝
- 요구사항확인
- 언리얼프로젝트
- 언리얼학습
- numpy/pandas
- 데이터입출력구현
- c언어
- Today
- Total
클라이언트/ 서버/ 엔지니어 " 게임 개발자"를 향한 매일의 공부일지
머신러닝 14 - 선형 분류 모델 실습해보기 6 : 선형 회귀와 선형 분류 평가 지표 및 모델 평가해보기 본문
선형 회귀와 분류의 평가 지표를 학습해보며 마지막 실습의 여정을 이어가려고 한다.
선형 회귀 평가지표

평균이 작을수록 오차가 적게 난다. 오차를 제곱하므로 차이값이 크게 난기에 원래 값에 제곱근을 한 RMSE가 있다.

선형 회귀 평가 지표

모델이 100개 중에서 20개를 예측하면 20%의 정확도를 갖고 있다. 정확도만 보았을 때는 모델에 대해 잘못된 평가를 내릴 가능성이 크다. 그렇기에 이 외에 정밀도나 재현율 같은 분류 평가 지표가 존재한다.
Confusion_matrix는 모델이 예측한 것과 실제에 대한 정보를 4분면으로 나누어 표기한 것이다. x축은 모델에 대한 예측을, y축은 실제 정보를 담는다. 실제도 양성과 음성으로 구분된다.

참 양성과 참 음성은 제대로 예측한 영역이 표기된다. 예를 들면 이직할 거라고 예측한 것과 실제 이직이 같은 경우이다. 반면 거짓 양성과 거짓 음성은 이직할 거라고 예측했지만 이직하지 않은 사람과 그 반대의 경우에 속한다. 정확도는 전체 비율에서 정확히 맞춘 것을 표기한다.

모델은 지금 현재의 사람들 모두 암 환자가 아니라고 예측했다. 왼쪽의 값을 모두 더하면 모델이 암 환자가 아니라고 예측한 값이 되고, 오른쪽은 암 환자가 아니라고 예측한 값이다. 암 환자가 아니라고 했지만 암 환자인 사람은 5명이 되어 정확도를 계산할 수 있다.
이 모델은 잘된 모델이라고 할 수 있을까? 우리는 양성 클래스를 더 잘 파악해야 한다. 하지만 이런 경우는 모델에서 자주 일어난다. 데이터 분석을 하면 데이터 불균형이 온기에 모델은 데이터가 더 많은 쪽에 비중을 두며 흘러가게 된다. 정확도에 중점을 두면 이러한 오류가 발생하게 된다. 관심을 갖는 양성 클래스가 아닌 음성 클래스에 데이터가 많이 분포되어 있을 경우에는 더욱 그렇다.

내가 관심을 갖고 있는 양성 클래스를 얼마나 잘 맞추었는지를 재현율이라고 부른다. 암 환자를 양성 클래스로 설정했을 때 모델이 암 환자를 정확히 맞춘 비율을 계산한 것이다.

이를 재현율로 계산하면 0%가 나온다. 이것을 보면 자신의 모델이 뭔가 잘못된 판단을 내리고 있음을 알 수 있다.


모델이 전부다 5명이 암 환자라고 판단하면 재현율은 100%로 다 맞지만 실제로는 잘못된 예측을 한 모델이 된다. 이렇게 정확도와 재현율만 보면 잘못된 판단을 내리게 된다. 여기서 정밀도를 다시 한번 확인할 필요가 있다.
정밀도는 예측한 양성 비율 중에서 실제로 양성인 비율을 말한다.

정밀도만 보면 잘못된 판단을 내릴 수도 있다. 그렇기에 정밀도, 재현율, 정확도 이 3가지를 함께 고려하여 모델을 평가해야 한다.
직원 이직 예측 실습해보기


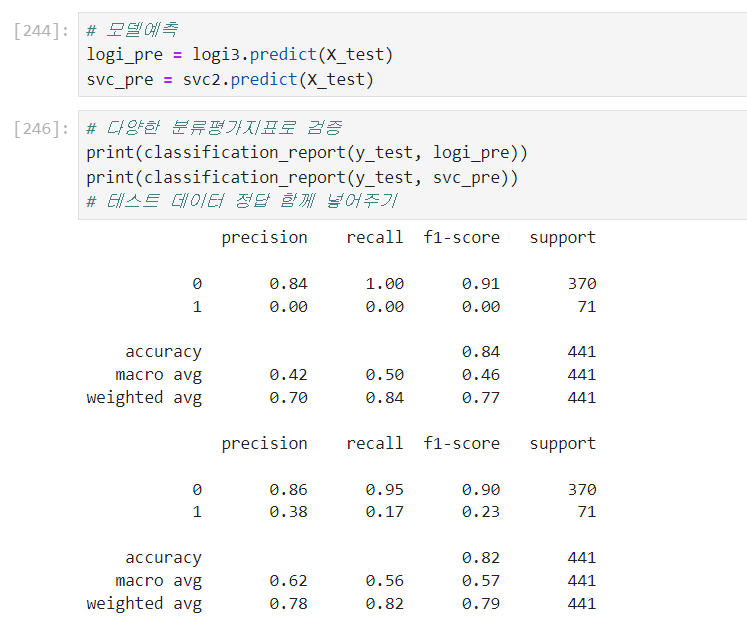
위에가 logi, 아래는 SVC이다. 0은 이직을 안한 사람을 양성이라고 보았을 때 정밀도는 84%이다. recall에서 실제 이직은 안한 사람은 다 맞추었다. 이직을 한 사람 중에서 이직할 거라고 예측한 사람은 한 명도 맞추지 못했다.
정확도만 보면 84%로 잘 맞춘 듯 보이지만, 이 모델은 이직을 안한 사람만 맞춘 것이다. 이직을 한 사람은 아무것도 맞추지 못했다.
SVC는 logi와는 달리 이직은 한 사람에 대해 조금 더 잘 맞추었음을 볼 수 있다. 하지만 여전히 예측의 정확도는 높지 않다. f1-score는 precision과 recall을 합쳐서 조합 평균을 낸 것이다. 보통의 평균은 값들을 더해서 해당 수로 나눈 것이 보편적이다. 하지만 조합 평균은 둘다 높아야 f1-score가 높게 나온다. 한쪽이 치우치면 점수가 높지 않다. 정밀도와 재현율이 모두 좋아야 좋은 모델임을 만들어내기 위해 f1-score가 등장한 것이다.
인공지능의 모델링을 할 때 성능을 높이는 것이 전부는 아니다. 중간 중간의 과정을 어떻게 전처리 하는지, 시각화, 모델링 등 다양한 방법을 생각하게 하는 것이 모델링 작업이다. 논문을 쓸 것이 아니라면 성능은 그렇게 크게 중요하지 않는 부분이다. 이 문제를 해결하기 위해 얼마나 다양한 방법론과 시각으로 시도해보느냐가 중요하다.
개발 분야도 마찬가지다. 하나를 너무 깊게 파는 것보다 두루두루 알아두고 공부해보는 것이 더 중요하다. 그래야 시야가 편협해지지 않고 다양한 관점에서 바라볼 수 있게 된다.
학습을 마치고
여기까지 해서 선형 회귀 모델 실습이 모두 끝났다. 아마 4일치 수업 분량은 되었던 것 같다. 그래도 끝까지 포기하지 않고 공부를 이어갔다는 것이 스스로도 참 대견스럽다. 이제 내일부터는 텍스트 마이닝 공부를 해서 이틀동안 이 공부를 마치려고 한다. 그런 다음에 주말에 딥러닝 공부를 이틀 정도 하고, 다음주부터는 컴퓨터 비전 과목을 시작해볼 계획을 갖고 있다.
컴퓨터 비전 수업을 받을 때는 정말 지루하고 재미없었는데 이 분야를 공부해두면 나중에 영상이나 게임 작업을 할 때 많은 도움이 될 것 같다는 생각이 들었다.
이 분야는 책도 구입해서 좀더 깊이있는 학습을 해볼 생각이다. 아무튼 오늘도 공부하느라 참 수고가 많았고, 남은 시간은 오늘 해야 하는 다른 공부와 운동을 하며 하루를 마무리할 것이다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝을 위한 데이터 준비하기 2 - 데이터 준비의 중요성과 파이프라인 (0) | 2024.09.19 |
|---|---|
| 머신러닝을 위한 데이터 이해하기 1 - 머신러닝을 위한 핵심 개념 살펴보기 (0) | 2024.09.19 |
| 머신러닝 13 - 선형 분류 모델 실습해보기 5 : 직원 이직 분석 실습으로 본 모델 복잡도와 하이퍼 파라미터 튜닝에 대하여 (0) | 2024.09.19 |
| 머신러닝 12 - 선형 분류 모델 실습해보기 4 : 직원 이직 분석 : 훈련용 및 평가용 데이터 분리 및 학습시키기 (0) | 2024.09.18 |
| 머신러닝 11 - 선형 분류 모델 실습해보기 3 : 직원 이직 분석 세번째 가설 및 모델링 작업하기 (0) | 2024.09.18 |



