
- 분류 전체보기 (1618)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- SQL
- 머신러닝
- JDBC
- 컴퓨터구조
- 혼공머신
- 정보처리기사실기
- 디버깅
- html/css
- c언어
- JSP/Servlet
- 중학수학
- 순환신경망
- 파이썬
- 데이터베이스
- CSS
- 연습문제
- 딥러닝
- 상속
- 자바 실습
- 자바스크립트심화
- 데이터분석
- 중학1-1
- 정보처리기사필기
- 컴퓨터비전
- 개발일기
- JSP
- rnn
- 자바
- 자바스크립트
- 오블완
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
머신러닝 11 - 선형 분류 모델 실습해보기 3 : 직원 이직 분석 세번째 가설 및 모델링 작업하기 본문
오늘 오후에 계속 놀고 먹고 잠을 자며 시간을 보내서 오늘은 새벽 늦게까지 날을 새고 공부를 해야 할 것 같다. 아무튼 다시 공부를 할 수 있어서 다행이다. 분명 쉬고 편안한 시간을 보냈으나 마음은 결코 편하지 않았다. 차라리 하기 싫은 마음을 이기고 건강한 음식을 선택하고 책상 앞에 다시 앉아 공부할 때가 마음이 편했을 것 같다.
언제나 사람은 두 가지 선택 중에서 후회를 한다. 하지만 이것을 해도 저것을 해도 후회를 할 거라면 좋은 선택을 한 후에 후회를 하는 것이 나을 것이다.
이제 다시 선형분류 학습을 시작해볼 것이다.
선형 분류 모델 복습

양성 클래스는 자신이 관심을 갖고 지금 예측하려는 모델을 말하고, 음성 클래스는 그 반대편에 있는 것이다. 예를 들어 직원들의 이직 예측을 하는 모델을 구현하고자 할 때 양성 클래스는 이직류이 된다. 만약 양성 클래스로 설정한 것은 1, 음성 클래스는 0이다.

분류를 더 잘할 수 있는 함수로 Sigmoid 함수를 만들어냈다.

이 분류 모델의 장점은 확률적 해석이 가능하다는 점이다. 0이면 0%, 1이면 100%로 말할 수 있어 0에서 1 사이값으로 확률을 예측할 수 있다. 이 함수값이 너무 적거나 많은 것은 확률의 변화가 거의 없다. 하지만 이 중간에서 확률이 많이 변한다. 그렇기에 이 모델이 전통적이지만 지금까지도 많이 사용되는 모델이다.

이 둘을 양성과 음성으로 구분할 때 경계선에 있는 직선 사이에서 최대한 많이 여백을 남길 수 있는 직선을 찾으려고 노력하는 모델이다. 만약 이 빨간선보다 기울기가 완만한 파란색 직선을 찾으면 어떻게 될까? 이 선에 동그라미가 가면 자신을 파란색 선이라고 인식한다. 이런 식으로 빗나간 데이터가 있을 때 예측값을 다르게 인식하게 되는 것이다.
하지만 여백을 최대한 많이 남기는 빨간색을 찾게 되면 예측값에서 조금 어긋나더라도 안정적이고 정확한 데이터를 만들 수 있게 된다.

데이터가 적다면 딥러닝을 할 때 전통적인 모델을 사용하는 것이 효율면에서 더 좋다. 차원이 낮은 데이터에서 분류가 잘 되지 않으면 이것을 고차원으로 옮겨준다. 이러한 기법을 커널 기법이라고 한다.
직원 이직 예측 실습하기
며칠 동안 노트북 환경에서 하다가 데스크탑으로 옮겨서 하니 코드 오류가 정말 많이 떠서 이 오류를 해결하는데 한참의 시간을 보냈다. 이미 제거한 결측치와 타입 속성도 다시 바꾸어서 몇 개의 코드를 추가해주었다.
전에는 코드 오류가 뜨는 당황하기부터 했지만 이제는 그렇지 않고 하나의 놀이처럼 즐길 수 있게 되었다. 다행히 모두 해결이 되어 이제 이 수업을 들을 준비가 모두 갖추어졌다. 이제 이어서 학습을 진행해보자.
여기서부터는 다시 원래 수업하셨던 선생님께서 바톤을 이어가셨다.

야근 시간에 따른 yes와 no의 개수와 총합을 확인해보았다.

야근을 하는 사람의 이직률이 높음을 볼 수 있다.



야근에 따른 연봉 인상률은 비슷한 편이다(전체 이직률은 16%).

야근을 하지 않는 사람들만 보여지고 있다. 여기서 이직률의 평균을 구해본다.
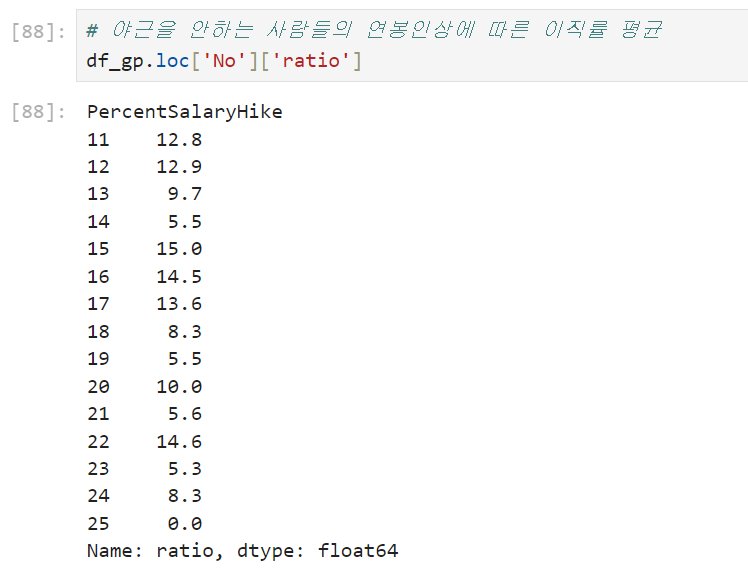



그래프를 보면 야근을 하는 사람들에 대해 연봉 인상을 해주면 이직률이 낮아지는 것을 볼 수 있다. 하지만 여기서 특이점을 볼 수 있는데, 능력이 좋아 야근을 하는 사람들은 이직한다는 걸 알게 된다.
일반적으로 이직률이 높으면 안좋은 기업으로 인식될 수 있지만, 대기업에서는 이직이 높다는 건 그만큼 인재 순환이 잘 된다는 것으로 생각되기도 한다. 우리 회사에 적응할 수 있는 사람들만 남고 그렇지 않은 사람들은 빨리 이직을 해야 회사 입장에서도 더 좋기 때문이다.







이렇게 글자형과 숫자형 데이터를 분리해주었다.

출장의 여부에 따라 이직률이 높을 것 같다는 생각이 들면 레이블 인코딩을 진행해주면 된다.







학습을 마치고
오후에는 많이 놀았지만 다시 저녁에 공부에 집중할 수 있어서 정말 좋았다. 공부를 하니 다시 마음이 안정되고 평안해졌다. 하나도 지루하지 않았고 재미있었으며, 데이터 분석이라는 학문도 참 괜찮은 분야라는 생각을 하게 된다.
데이터 과학자에 대한 공부를 오늘 아침에 했었는데 자신만의 가설을 세우고 예측을 해보며 이를 검증해나가는 것이 참 신기하게 느껴진다. 왜 사회학도 사회과학이라는 이름을 붙였는지 이해가 되었다. 그리고 내가 사회학과를 졸업하며 통계를 배울 수 있는 기회가 있었다는 것도 무척 감사하게 느껴졌다.
이과와 문과를 모두 다 경험했기에 난 개발자로서 많은 역량을 갖출 수 있게 되었다는 걸 알게 되었다. 모든 공부는 다 필요한 것이다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 13 - 선형 분류 모델 실습해보기 5 : 직원 이직 분석 실습으로 본 모델 복잡도와 하이퍼 파라미터 튜닝에 대하여 (0) | 2024.09.19 |
|---|---|
| 머신러닝 12 - 선형 분류 모델 실습해보기 4 : 직원 이직 분석 : 훈련용 및 평가용 데이터 분리 및 학습시키기 (0) | 2024.09.18 |
| 데이터 과학자 이해하기 5 - 심장질환 분석 실습해보기 2 : 최고의 요인 조합으로 최고의 정확도에 도전하기 (0) | 2024.09.18 |
| 데이터 과학자 이해하기 4 - 실장질환 분석 실습 해보기 1 : 선탁한 요인의 실제 연관성 파악하기 (0) | 2024.09.18 |
| 데이터 과학자 이해하기 3 - 머신러닝 업무 프로세스 이해 및 머신러닝을 위한 도구 (0) | 2024.09.18 |



