
- 분류 전체보기 (1781)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 개발일기
- 파이썬
- 딥러닝
- 쇼핑몰홈페이지제작
- 자바
- ChatGPT
- SQL
- 중학1-1
- 컴퓨터비전
- 정보처리기사실기
- 데이터베이스
- 머신러닝
- 컴퓨터구조
- 자바스크립트
- 자바스크립트심화
- html/css
- 정보처리기사필기
- rnn
- JDBC
- 디버깅
- 타입스크립트심화
- 상속
- JSP/Servlet
- 자바 실습
- 순환신경망
- JSP
- 중학수학
- 데이터분석
- 혼공머신
- 연습문제
- Today
- Total
클라이언트/ 서버/ 엔지니어 "게임 개발자"를 향한 매일의 공부일지
데이터 다루기 3 - 데이터 전처리 1 : 이상한 도미 전처리하여 제대로 예측하게 만들기 본문
이제 다시 공부에 집중해 볼 것이다. 오늘부터는 새벽 6시 반에 운동을 하기로 다짐했다. 그러니까 2시간이 조금 안 되는 시간 동안 데이터 전처리 공부를 모두 마칠 생각이다.
올바른 결과 도출을 위해 데이터를 사용하기 전에 데이터 전처리 과정을 거친다.
지난 시간 복습

찾고자 하는 대상을 양성, 그 외의 대상을 음성 클래스로 설정한다. 그리고 훈련 세트와 테스트 세트로 나누어 훈련과 평가를 한다. 그리고 배열 자체가 아닌 인덱스로 섞는다.
학습 목표
전처리 과정을 거친 데이터로 훈련했을 때의 차이를 알고, 표준점수로 특성의 스케일을 변환하는 방법 배우기
시작하기 전에
김팀장은 혼공머신에게 길이가 25cm이고 무게가 150g인데 빙어로 예측한다고 말했다. 도미 같은데 무슨 일이 일어난 걸까?

넘파이로 데이터 준비하기

먼저 도미와 빙어 데이터를 준비해 본다. 하지만 이번에는 좀 더 세련된 방법을 사용해 보았다. 전에는 파이썬 리스트를 순회하면서 원소를 하나씩 꺼내 생선 하나의 길이와 무게를 리스트 안의 리스트로 직접 구성했다. 하지만 이제 넘파이를 통해 훨씬 간편하게 만들 수 있다.
바로 column_stack() 함수는 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결한다. 이렇게 두 리스트를 일렬로 세운 다음 나란히 옆으로 붙였다. 그리고 fish_length와 fish_weight를 합쳤다. 그외에 row_stack이 있는데 이건 열 방향으로 붙이는 것이다.
그리고 np.ones()와 np.zeros() 함수는 각각 원하는 개수의 1과 0을 채운 배열을 만들어준다. 이 두 함수를 이용해 1이 35개인 배열과 0이 14인 배열을 간단히 만들 수 있다. 그다음 두 배열을 그대로 사용하면 된다.
np.ones([2, 3])처럼 크기를 튜플로 지정하면 1로 채워진 배열을 만들 수 있다. 1, 0이 아닌 특정 값을 가진 배열을 만들고 싶을 때는 np.full([2, 3], 9)를 사용한다. 이렇게 하면 2x3 크기에 9로 채워진 배열을 만들 수 있다.
여기서는 배열을 연결하는 np.concatenate() 함수를 사용했다. 이 함수는 연결한 리스트나 배열을 튜플로 전달해야 한다.
사이킷런으로 훈련 세트와 테스트 세트 나누기
앞에서는 넘파이 배열의 인덱스를 직접 섞어서 훈련 세트와 테스트 세트로 나누었다. 사실 이 방법은 조금 번거로워 이번에는 다른 방법을 사용해 보겠다.
사이킷런은 머신러닝 모델을 위한 알고리즘뿐 아니라 다양한 유틸리티 도구도 제공한다. 대표적인 도구가 train_test_split() 함수이다. 이 함수는 전달되는 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어준다. 물론 나누기 전에 알아서 섞어 준다. 훈련과 테스트 세트 사이의 비율이 적절하지 않을 경우에는 잘 섞이지 않을 수 있으므로 stratify에 타킷값을 전달한다.

이 train_test_split() 함수에는 자체적으로 랜덤 시드를 지정할 수 있는 random_state 매개변수가 있다. 랜덤 시드를 42로 지정했다. 이 함수는 기본적으로 25%를 테스트 세트로 떼어낸다. 이렇게 전달하는 배열을 2개씩 쪼개어 전달한다.
하지만 테스트 세트의 시행 결과 샘플링 편향 현상이 조금 나타났다. 이처럼 무작위로 데이터를 나누었을 때 샘플이 골고루 섞이지 않을 수 있다. 특히 일부 클래스의 개수가 적을 때 이런 일이 생긴다.
train_test_split() 함수는 이런 문제를 간단히 해결하기 위한 방법이 있다. stratify 매개변수에 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눈다.
수상한 도미

훈련 데이터로 모델을 훈련하고 테스트 데이터로 모델을 평가한다. 배열 인덱싱을 사용한 결과 정확하게 잘 나왔다. 그리고 새로운 샘플을 다른 데이터와 함께 산점도로 그려보았다. 새로운 샘플은 marker 매개변수를 ^로 지정하면 삼각형으로 표시된다.
하지만 이 모델은 빙어에 가깝다고 판단했다. 분명 오른쪽 위로 뻗어 있는 다른 도미 데이터에 더 가깝다. 왜 그런 걸까? k-최근접 이웃은 주변의 샘플 중에서 다수인 클래스를 예측으로 사용한다. KNeighborClassifier 클래스는 주어진 샘플에서 가장 가까운 이웃을 찾아주는 Kneighbors() 메서드를 제공한다.
이 메서드는 가장 가까운 이웃의 샘플 5개를 추출한다.
이 샘플 메서드를 marker='D'로 지정하면 산점도를 마름모로 표시한다. 살펴보니 가장 가까운 이웃에 4개의 샘플이 모두 빙어이다. 눈으로 보기에는 가까워 보이지만 실제로는 그렇지 않다는 것을 다음 내용을 통해 확인해 볼 수 있다.
기준을 맞춰라
어림짐작으로 130보다 92의 간격이 너무 작아 보인다. 이것은 x축은 범위가 좁고(10~40), y축(0~1000)은 범위가 넓기 때문이다.

눈으로 확인하기 위해 x축의 범위를 동일하게 0~1000으로 맞추어서 그래프로 출력해 보았다. 산점도가 거의 일직선으로 나타남을 볼 수 있다. 즉, 이 데이터는 길이의 영향은 미비하고 무게에 따라 영향을 많이 받음을 확인할 수 있다. 두 특성의 값이 놓인 범위가 다를 경우(스케일이 다르다고도 함) 알고리즘이 올바르게 예측할 수 없다. 특히 알고리즘이 거리 기반일 때 그렇다. k-최근접 이웃 모델도 여기에 포함된다. 제대로 사용하려면 특성값을 일정한 기준으로 맞춰주어야 한다. 이런 작업을 데이터 전처리라고 한다.
가장 널리 사용하는 전처리 방법은 표준점수이다. 표준점수는 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타낸다. 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교할 수 있다.

표준점수는 평균을 빼고 표준편차를 나누어 주면 된다. 넘파이는 이 두 함수를 모두 제공한다. 이러한 넘파이 기능을 브로드캐스팅이라고 부른다.
만약 axis를 1로 지정하면 각 행별로 평균을 구한다. 즉 36개의 평균을 구하게 된다. 우리는 각 특성마다 평균을 구할 것이므로 axis를 0으로 지정한다. 모든 행을 다 빼지 않고 1행 2열만 빼면 모든 열에 다 적용하여 빼준다. 그렇기에 (36, 2)가 만들어진다.
전처리 데이터로 모델 훈련하기
그래프로 출력해 보면 오른쪽 맨 꼭대기에 수상한 샘플 하나만 덩그러니 떨어져 있다. 그 이유는 훈련 세트를 mean(평균)으로 빼고 std(표준편차)로 나누어 주었기 때문에 값의 크기가 크게 달라졌다. 이 도미는 특성이 하나이기에 표준편차나 표준점수를 구할 수 없다.
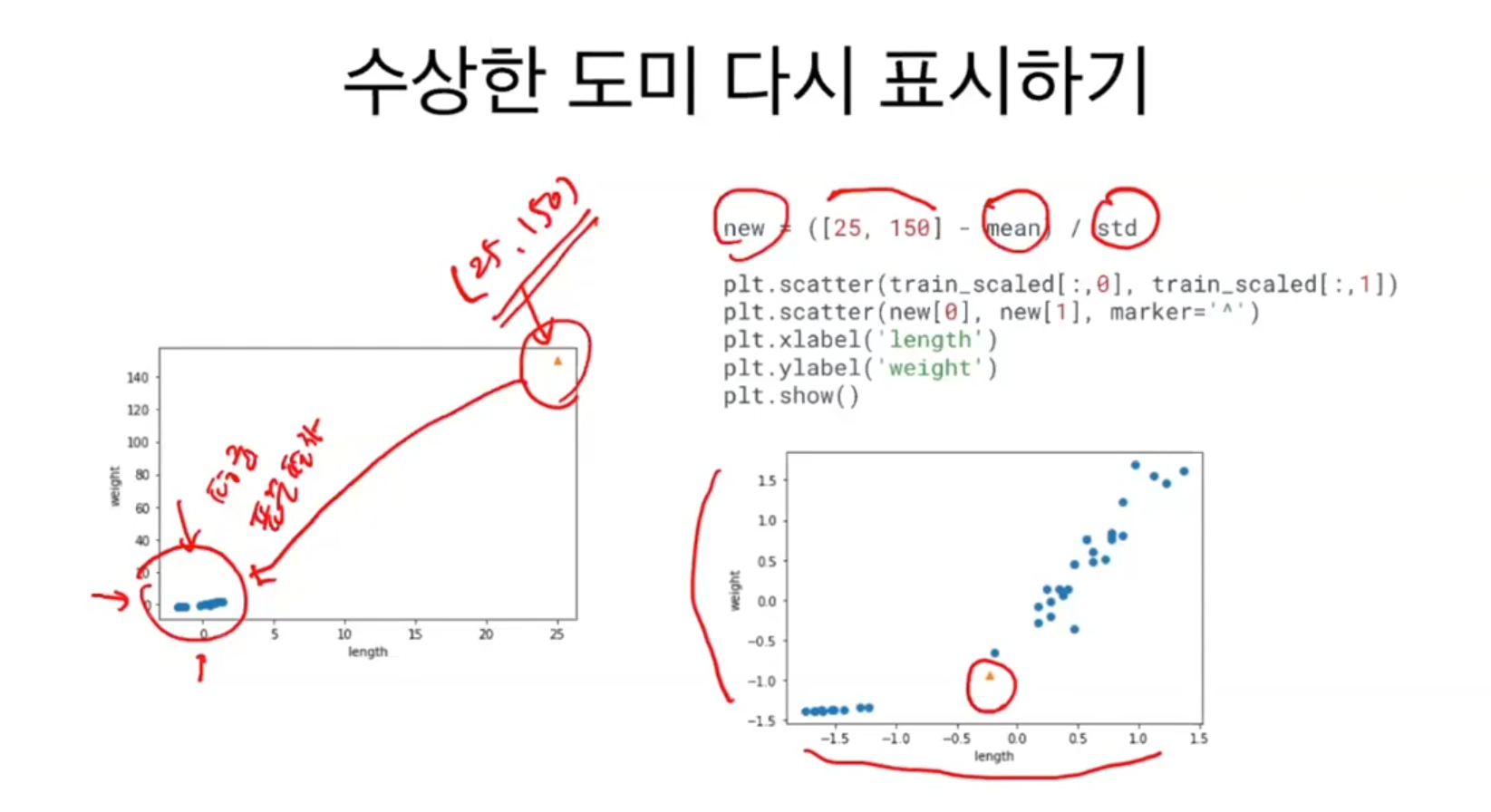
여기서 중요한 점은 훈련 세트의 mean, std를 이용해서 변환해야 한다. 새로운 값을 훈련 세트의 평균과 표준편차로 나누어 변환해주었다. 이 그래프는 변환하기 전의 산점도와 거의 유사하다. 크게 달라진 점은 x축과 y축의 범위가 -1.5에서 1.5로 바뀐 것이다. 이제 이 데이터셋으로 k-최근접 이웃 모델을 훈련해 볼 것이다.

테스트 세트도 훈련 세트의 평균과 표준편차로 변환해야 한다. 이제 25cm, 150g인 생선을 도미라고 예측하는 것을 볼 수 있다. 입력 데이터를 적절히 가공하는 것을 전처리라고 한다.
학습을 마치고
중간에 공부를 하다 너무 졸려서 12분 정도 잠을 자고 났더니 머릿속이 개운해졌다. 1시간 반은 강의를 듣고 공부하며 30분은 실습을 하고 문제를 푸는데 시간을 보내고 있다.
이제 운동 가기 전까지 나머지 학습을 진행해보려고 한다. 공부하다 보면 운동을 하는 시간이 무척 아깝게 느껴져서 잘하지 않을 때가 있다. 하지만 공부할 때 가장 중요한 것은 체력이고 이 체력을 기르려면 필수적으로 운동을 해야 한다. 요즘 미생을 다시 시청하고 있는데 거기에도 그런 이야기가 나온다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 회귀 알고리즘과 모델 규제 1 - k-최근접 이웃 회귀 1 : 회귀와 분류 모델 그리고 과대적합과 과소적합 문제 해결하기 (0) | 2024.09.28 |
|---|---|
| 데이터 다루기 4 - 데이터 전처리 2 : 스스로 실습하며 문제 풀어보는 시간 (0) | 2024.09.28 |
| 데이터 다루기 2 - 훈련 세트와 테스트 세트 2 : 스스로 실습하며 문제 풀어보는 시간 (0) | 2024.09.28 |
| 데이터 다루기 1 - 훈련 세트와 테스트 세트 1 : 지도 학습과 비지도학습의 차이와 훈련세트와 테스트세트로 나누는 것에 대하여 (0) | 2024.09.28 |
| 나의 첫 머신러닝 4 - 마켓과 머신러닝 2 : 스스로 실습하며 문제 풀어보는 시간 (0) | 2024.09.27 |



